






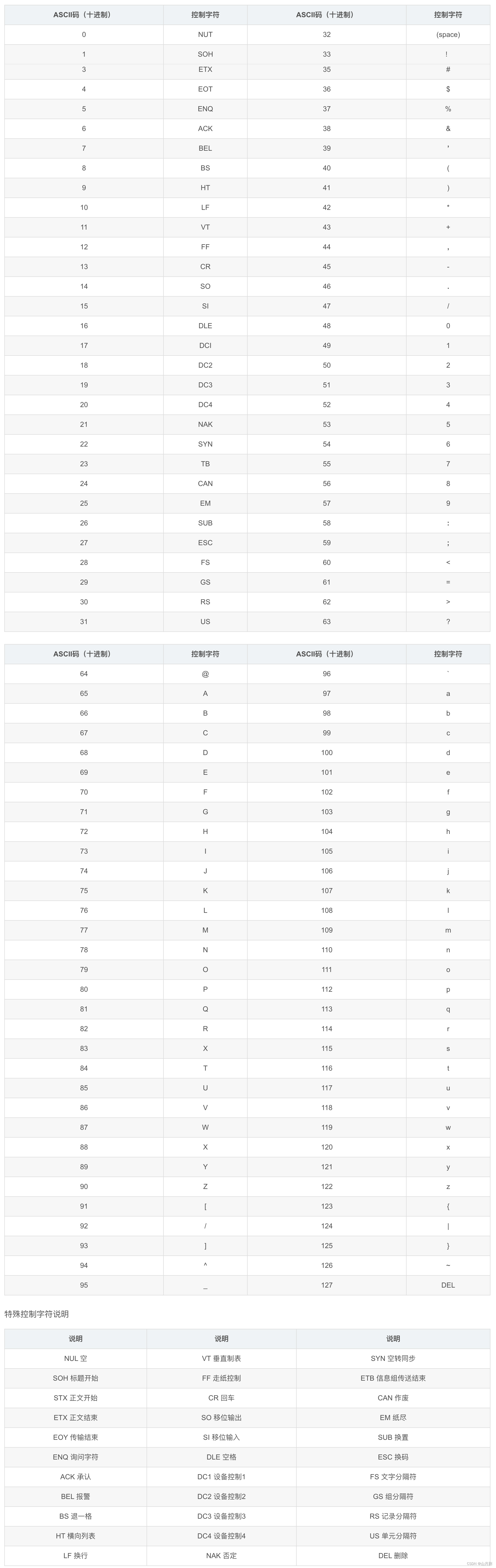
 ASCII码是一种基于拉丁字母的电脑编码系统,用于显示现代美式英语。标准ASCII包含128个字符,包括大小写字母、数字和标点符号。在网页中,ASCII码值以十进制表示,如0代表数字0。扩展ASCII编码增加了更多字符,但不同地区对扩展字符的定义不一。
ASCII码是一种基于拉丁字母的电脑编码系统,用于显示现代美式英语。标准ASCII包含128个字符,包括大小写字母、数字和标点符号。在网页中,ASCII码值以十进制表示,如0代表数字0。扩展ASCII编码增加了更多字符,但不同地区对扩展字符的定义不一。
ASCII码值为十进制数字串,在网页中使用应在数字串前后分别加上“&#”和“;”,例如数字0的ASCII编码是48,则在网页中使用的格式应为“0”。
ASCII(American Standard Code for Information Interchange,美国信息互换标准代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代美式英语,并等同于国际标准ISO/IEC 646。标准ASCII编码可表示128个字符,包括大小写拉丁字母,阿拉伯数字、英语标点符号,以及在美式英语中使用的特殊控制字符。另有扩展版本的ASCII编码添加了一些西欧字符,可以表示255个字符,但是西欧国家间对扩充的字符定义不一致,并不是通用版本。


















 984
984

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











