







-
from sklearn
import svm
-
import pandas
as pd
-
import numpy
as np
-
from sklearn.model_selection
import train_test_split
-
#SVM模型实现汽车性能评测
-
car_data = pd.read_csv(
r'D:\pyproject\sklearn\car.csv')
-
car_data = car_data.dropna()
#去掉缺失值
-
#提取特征和类别
-
X= car_data.ix[:, :
'safety']
-
y= car_data.ix[:,
'class']
-
#划分训练集和测试集
-
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=
0.3, random_state=
0)
-
# 建立模型。 设置算法内核类型,有 'linear’, ‘poly’, ‘rbf’, ‘sigmoid’;惩罚参数为1,一般为10的幂次方
-
svc_model = svm.SVC(kernel=
'rbf', C=
1)
-
svc_model.fit(X_train, y_train)
-
predict_data = svc_model.predict(X_test)
-
accuracy = np.mean(predict_data==y_test)
-
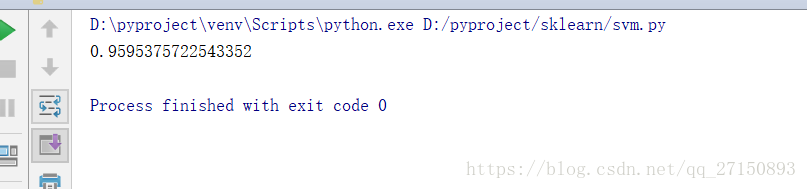
print(accuracy)
运行结果:
1.2 MLP神经网络模型
-
from sklearn.neural_network
import MLPClassifier
-
import pandas
as pd
-
import numpy
as np
-
from sklearn.model_selection
import train_test_split
-
#MLP神经网络模型实现汽车性能评测
-
car_data = pd.read_csv(
r'D:\pyproject\sklearn\car.csv')
-
car_data = car_data.dropna()
#去掉缺失值
-
#提取特征和对象类别
-
X= car_data.ix[:, :
'safety']
-
y= car_data.ix[:,
'class']
-
#划分训练集和测试集
-
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=
0.3, random_state=
0)
-
#建立MLP神经网络模型 ,MLP的求解方法为adam,可选lbfgs、sgd,正则化惩罚alpha = 0.1
-
mpl_model = MLPClassifier(solver=
'adam', learning_rate=
'constant', learning_rate_init=
0.01,max_iter =
500,alpha =
0.01)
-
mpl_model.fit(X_train, y_train)
-
predict_data = mpl_model.predict(X_test)
-
accuracy = np.mean(predict_data == y_test)
-
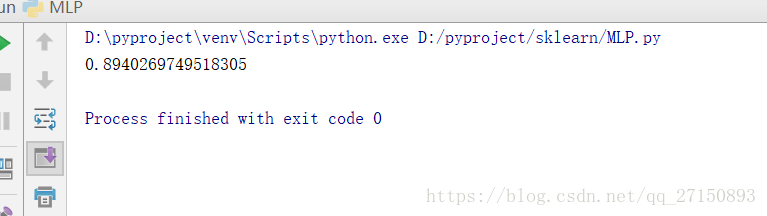
print(accuracy)
运行结果:
1.3 逻辑回归模型
-
import pandas
as pd
-
import numpy
as np
-
from sklearn.model_selection
import train_test_split
-
from sklearn.linear_model
import LogisticRegression
-
#逻辑回归模型实现汽车性能预测
-
car_data = pd.read_csv(
r'D:\pyproject\sklearn\car.csv')
-
car_data = car_data.dropna()
#去掉缺失值
-
#提取特征和对象类别
-
X= car_data.ix[:, :
'safety']
-
y= car_data.ix[:,
'class']
-
#划分训练集和测试集
-
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=
0.3, random_state=
0)
-
#建立逻辑回归模型 ,惩罚参数为100
-
lr_model = LogisticRegression(C=
100, max_iter=
1000)
-
lr_model.fit(X_train, y_train)
-
predict_data = lr_model.predict(X_test)
-
accuracy = np.mean(predict_data == y_test)
-
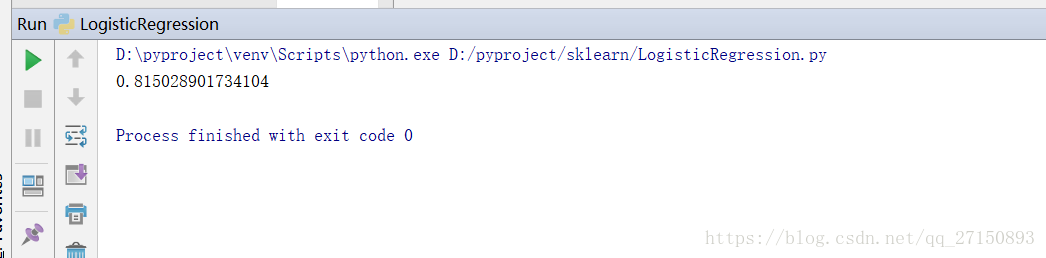
print(accuracy)
运行结果:
-
from sklearn
import tree
-
import pandas
as pd
-
import numpy
as np
-
from sklearn.model_selection
import train_test_split
-
#决策树模型实现汽车性能预测
-
car_data = pd.read_csv(
r'D:\pyproject\sklearn\car.csv')
-
car_data = car_data.dropna()
#去掉缺失值
-
#提取特征和类别
-
X= car_data.ix[:, :
'safety']
-
y= car_data.ix[:,
'class']
-
#划分训练集和测试集
-
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=
0.3, random_state=
0)
-
# 建立决策树模型,选择算法为熵增益,可选gini,entropy,默认为gini
-
tree_model = tree.DecisionTreeClassifier(criterion=
'gini')
-
tree_model.fit(X_train, y_train)
-
predict_data = tree_model.predict(X_test)
-
accuracy = np.mean(predict_data==y_test)
-
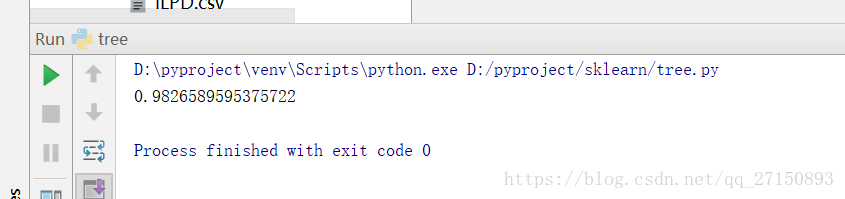
print(accuracy)
运行结果:
-
from sklearn
import neighbors
-
import pandas
as pd
-
import numpy
as np
-
from sklearn.model_selection
import train_test_split
-
#K最邻模型实现汽车性能预测
-
car_data = pd.read_csv(
r'D:\pyproject\sklearn\car.csv')
-
car_data = car_data.dropna()
#去掉缺失值
-
#提取特征和类别
-
X= car_data.ix[:, :
'safety']
-
y= car_data.ix[:,
'class']
-
#划分训练集和测试集
-
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=
0.3, random_state=
0)
-
# 建立KNN模型,邻居数选为7,默认为5
-
knn_model = neighbors.KNeighborsClassifier(n_neighbors =
7)
-
knn_model.fit(X_train, y_train)
-
#对测试集进行预测
-
predict_data = knn_model.predict(X_test)
-
accuracy = np.mean(predict_data==y_test)
-
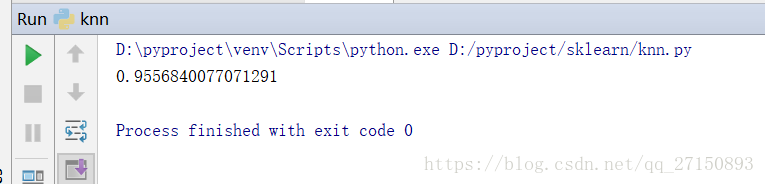
print(accuracy)
运行结果:
-
from sklearn.linear_model
import LinearRegression
-
from sklearn.datasets
import load_boston
-
from sklearn.model_selection
import train_test_split
-
#导入结果评价包
-
from sklearn.metrics
import mean_absolute_error
-
#利用线性回归模型预测波斯顿房价
-
-
#下载sklearn自带的数据集
-
data = load_boston()
-
#建立线性回归模型
-
clf = LinearRegression()
-
#划分训练集和测试集
-
X_train, X_test, y_train, y_test = train_test_split(data.data, data.target, test_size=
0.3, random_state=
0)
-
clf.fit(X_train, y_train)
-
predict_data = clf.predict(X_test)
-
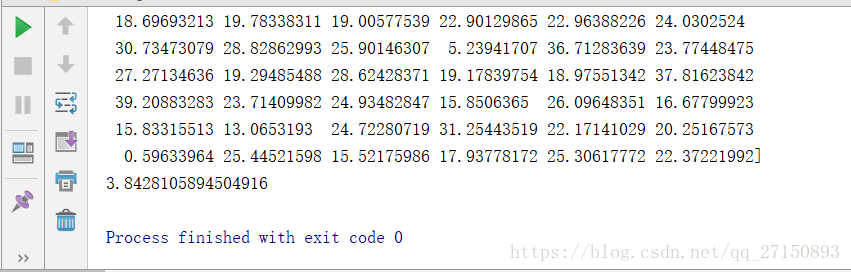
print(predict_data)
-
#平均绝对值误差对结果进行评价
-
appraise = mean_absolute_error(y_test, predict_data)
-
print(appraise)
运行结果:















 9828
9828

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









