






机器学习模型结果可信度基础理论
模型评估指标是用于评估模型效果好坏的数值指标,例如SSE就是评估回归类模型拟合效果的指标。但是否是评估指标好的模型就一定能用呢?其实并不一定。这里会涉及到一个关于评估指标可信度、或者说了解模型真实性能的重要命题。
其实,要了解模型的性能其实并不简单,固然我们会使用某些指标去进行模型评估,但其实指标也只是我们了解模型性能的途径而不是模型性能本身。而要真实、深刻的评判模型性能,就必须首先了解机器学习的建模目标,并在此基础之上熟悉我们判断模型是否能够完成目标的一些方法,当然,只有真实了解的模型性能,我们才能进一步考虑如何提升模型性能。因此,在正式讲解模型优化方法之前,我们需要花些时间讨论机器学习算法的建模目标、机器学习算法为了能够达到目标的一般思路,以及评估模型性能的手段,也就是模型评估指标。
无论是机器学习还是传统的统计分析模型,核心使命就是探索数字规律,而有监督学习则是希望在探索数字规律的基础上进一步对未来进行预测,当然,在数字的世界,这个预测未来,也就是预测未来某项事件的某项数值指标,如某地区未来患病人次、具备某种数字特征的图片上的动物是哪一类,此处的未来也并非指绝对意义上的以后的时间,而是在模型训练阶段暂时未接触到的数据。正是因为模型有了在未知标签情况下进行预判的能力,有监督学习才有了存在的价值,但我们知道,基本上所有的模型,都只能从以往的历史经验当中进行学习,也就是在以往的、已经知道的数据集上进行训练(如上述利用已知数据集进行模型训练,如利用过往股票数据训练时间序列模型),这里的核心矛盾在于,在以往的数据中提取出来的经验(也就是模型),怎么证明能够在接下来的数据中也具备一定的预测能力呢?或者说,要怎么训练模型,才能让模型在未知的数据集上也拥有良好的表现呢?
目的相同,但在具体的实现方法上,传统的数理统计分析建模和机器学习采用了不同的解决方案。
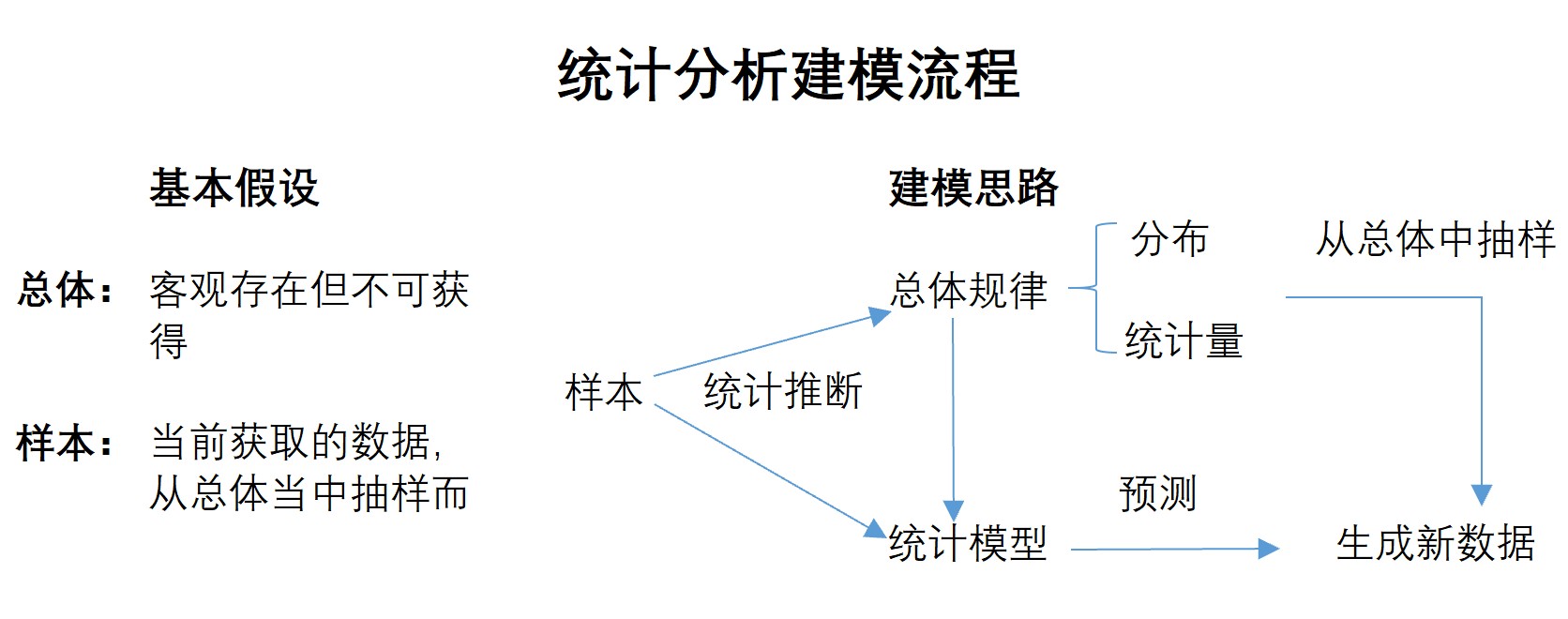
首先,在统计分析领域,我们会假设现在的数据和未来的数据其实都属于某个存在但不可获得的总体,也就是说,现在和未来的数据都是从某个总体中抽样而来的,都是这个总体的样本。而正式因为这些数据属于同一个总体,因此具备某些相同的规律,而现在挖掘到的数据规律也就在某些程度上可以应用到未来的数据当中去,不过呢,不同抽样的样本之间也会有个体之间的区别,另外模型本身也无法完全捕获规律,而这些就是误差的来源。
虽然样本和总体的概念是统计学概念,但样本和总体的概念所假设的前后数据的“局部规律一致性”,却是所有机器学习建模的基础。试想一下,如果获取到的数据前后描绘的不是一件事情,那么模型训练也就毫无价值(比如拿着A股走势预测的时间序列预测某地区下个季度患病人次)。因此,无论是机器学习所强调的从业务角度出发,要确保前后数据描述的一致性,还是统计分析所强调的样本和总体的概念,都是建模的基础。
在有了假设基础之后,统计分析就会利用一系列的数学方法和数理统计工具去推导总体的基本规律,也就是变量的分布规律和一些统计量的取值,由于这个过程是通过已知的样本去推断未知的总体,因此会有大量的“估计”和“检验”,在确定了总体的基本分布规律之后,才能够进一步使用统计分析模型构建模型(这也就是为什么在数理统计分析领域,构建线性回归模型需要先进行一系列的检验和变换的原因),当然,这些模型都是在总体规律基础之上、根据样本具体的数值进行的建模,我们自然有理由相信这些模型对接下来仍然是从总体中抽样而来的样本还是会具备一定的预测能力,这也就是我们对统计分析模型“信心”的来源。简单来说,就是我们通过样本推断总体的规律,然后结合总体的规律和样本的数值构建模型,由于模型也描绘了总体规律,所以模型对接下来从总体当中抽样而来的数据也会有不错的预测效果,这个过程我们可以通过下图来进行表示。
而对于机器学习来说,并没有借助“样本-总体”的基本理论,而是简单的采用了一种后验的方法来判别模型有效性,前面说到,我们假设前后获取的数据拥有规律一致性,但数据彼此之间又略有不同,为了能够在捕捉规律的同时又能考虑到“略有不同”所带来的误差,机器学习会把当前能获取到的数据划分成训练集(trainSet)和测试集(testSet),在训练集上构建模型,然后带入测试集的数据,观测在测试集上模型预测结果和真实结果之间的差异。这个过程其实就是在模拟获取到真实数据之后模型预测的情况,此前说到,模型能够在未知标签的数据集上进行预测,就是模型的核心价值,此时的测试集就是用于模拟未来的未知标签的数据集。如果模型能够在测试集上有不错的预测效果,我们就“简单粗暴”的认为模型可以在真实的未来获取的未知数据集上有不错的表现。其一般过程可以由下图表示。

虽然对比起数理统计分析,机器学习的证明模型有效性的过程更加“简单”,毕竟只要一次“模拟”成功,我们就认为模型对未来的数据也拥有判别效力,但这种“简单”的处理方式却非常实用,可以说,这是一种经过长期实践被证明的行之有效的方法。这也是为什么机器学习很多时候也被认为是实证类的方法,而在以后的学习中,我们也将了解到,机器学习有很多方法都是“经验总结的结果”。相比数理统计分析,确实没有“那么严谨”,但更易于理解的理论和更通用的方法,却使得机器学习可以在更为广泛的应用场景中发挥作用。(当然,负面影响却是,机器学习在曾经的很长一段时间内并不是主流的算法。)
据此,我们称模型在训练集上误差称为训练误差,在测试集上的误差称为泛化误差,不过毕竟在测试集上进行测试还只是模拟演习,我们采用模型的泛化能力来描述模型在未知数据上的判别能力,当然泛化能力无法准确衡量(未知的数据还未到来,到来的数据都变成了已知数据),我们只能通过模型在训练集和测试集上的表现,判别模型泛化能力,当然,就像此前说的一样,最基本的,我们会通过模型在测试集上的表现来判断模型的泛化能力。



















 1109
1109

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











