






提问:最近在学习Attention和Transformer相关的技术,看到很多资料说Transformer适合做多模态任务,看了模型结构中不知道哪里体现出了这一点?
蜡笔小熊猫(复旦大学 计算机)回答:
这个问题其实应该从两个方面回答:
第一个是任务方面,之前的多模态任务是怎么做的,为什么现在大家会转向Transformer做多模态任务?
在Transformer,特别是Vision Transformer出来打破CV和NLP的模型壁垒之前,CV的主要模型是CNN,NLP的主要模型是RNN,那个时代的多模态任务,主要就是通过CNN拿到图像的特征,RNN拿到文本的特征,然后做各种各样的Attention与concat过分类器,这个大家可以从我文章栏的一篇ACL论文解说《Writing by Memorizing: Hierarchical Retrieval-based Medical Report Generation》略窥一二,使用这种方式构造出来的多模态模型会大量依赖各种模型输出的特征进行多重操作,pipeline巨大并且复杂,很难形成一个end2end的方便好用的模型
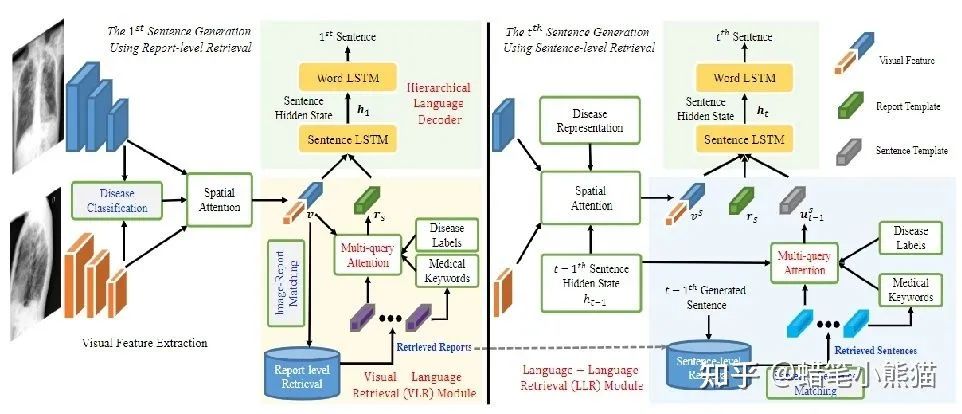
但是Transformer,特别是ViT(Vision Transformer)出来之后,这个模型壁垒就被打破了,人们发现原来对付图像和文本都可以使用同一个模型,那么处理多模态的任务,就直接使用把两种模态输进这个模型,然后接上自己的下游任务,省时省力end2end,还能把精力更多放在任务而不是特征如何concat和attention上
第二个是模型原理层面,为什么Transformer可以做图像也可以做文本,为什么它适合做一个跨模态的任务?
说的直白一点,因为Transformer中的Self-Attetion机制很强大,使得Transformer是一个天然强力的一维长序列特征提取器,而所有模态的信息都可以合在一起变成一维长序列被Transformer处理

attention本身就是很强大的,已经热了很多年了,而self-attention更是使得Transformer的大规模pretrain成为可能的重要原因
self-attention的序列特征提取功能其实是非常强大的,如果你用CNN,那么一次提取的特征只有一个限定大小的矩阵,如果在句子里做TextCNN,那就是提取一小段文字的特征,最后汇聚到一起;如果做RNN,那么会产生长程依赖问题,当句子 太长最后RNN会把前面的东西都忘掉
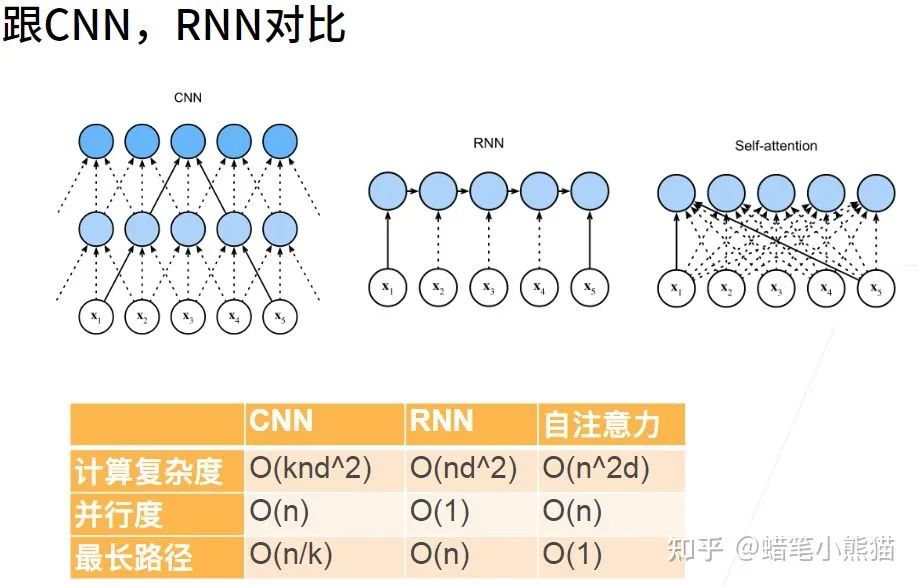
从上图沐神的课件可以看到,面对同样的长序列处理问题,self-attention既消除了RNN的并行度和遗忘问题,也消除了CNN的最长路径问题
然而self-attention的本质就是对每个token,计算这个token相对于这个句子其他所有token的特征再concat到一起,无视长度,输入有多长,特征就提多远
那么如果传入的不是句子,而是普通一维序列(也就是一个数组)呢?那就是对序列的每个点(数组的每个值),计算这个点与序列里其他点的所有特征,这也是Vision Transformer成功的原因,既然是对序列建模,我就把一张图片做成序列不就完了?一整张图片的像素矩阵直接平铺变成序列复杂度太大,那就切大块一点呗(反正CNN也是这种思想,卷积核获得的是局部特征,换个角度来说也是特定patch的特征),ViT就把一张图片做成了16个patch然后加上对应的position embedding(就是割成小方块变成token向量塞进去加上patch对应图片原始位置的标号)
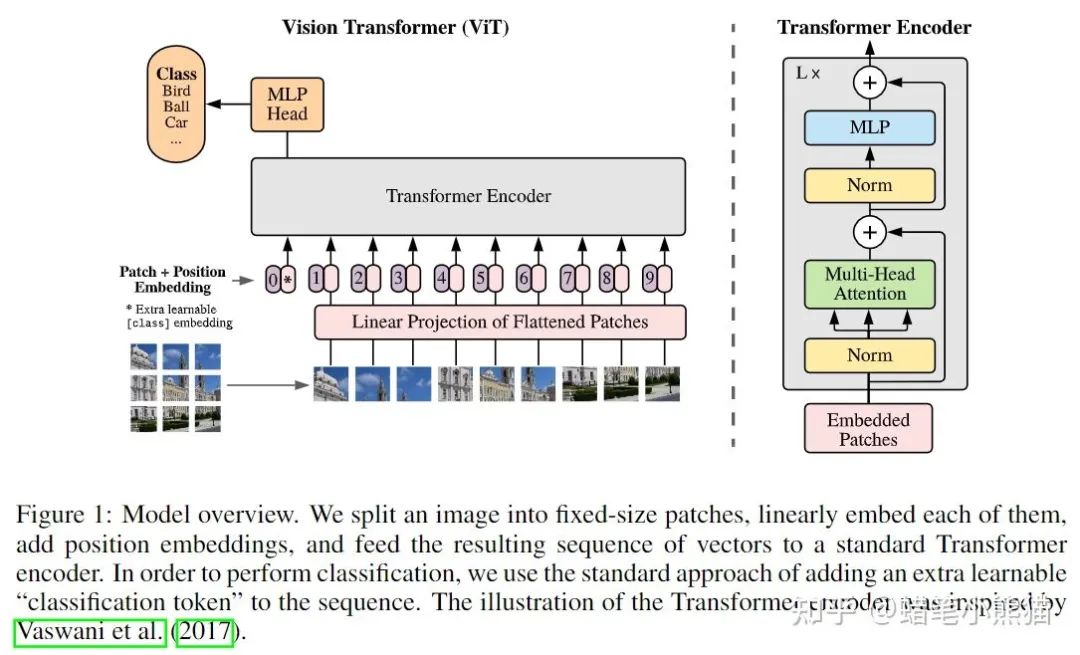
所以如果你用Transformer来当backbone的时候,你需要做的就只是把图片,文本,甚至表格信息等其他的所有模态信息全部flatten再concat或者相加成一维数组送进Transformer,然后期待强大的Self-Attention开始work就可以了,比如图片,你用CNN来提取特征得到了feature map,然后你再flatten成一维,和文本concat到一起就可以了
以下是几个大公司的多模态Transformer的例子:
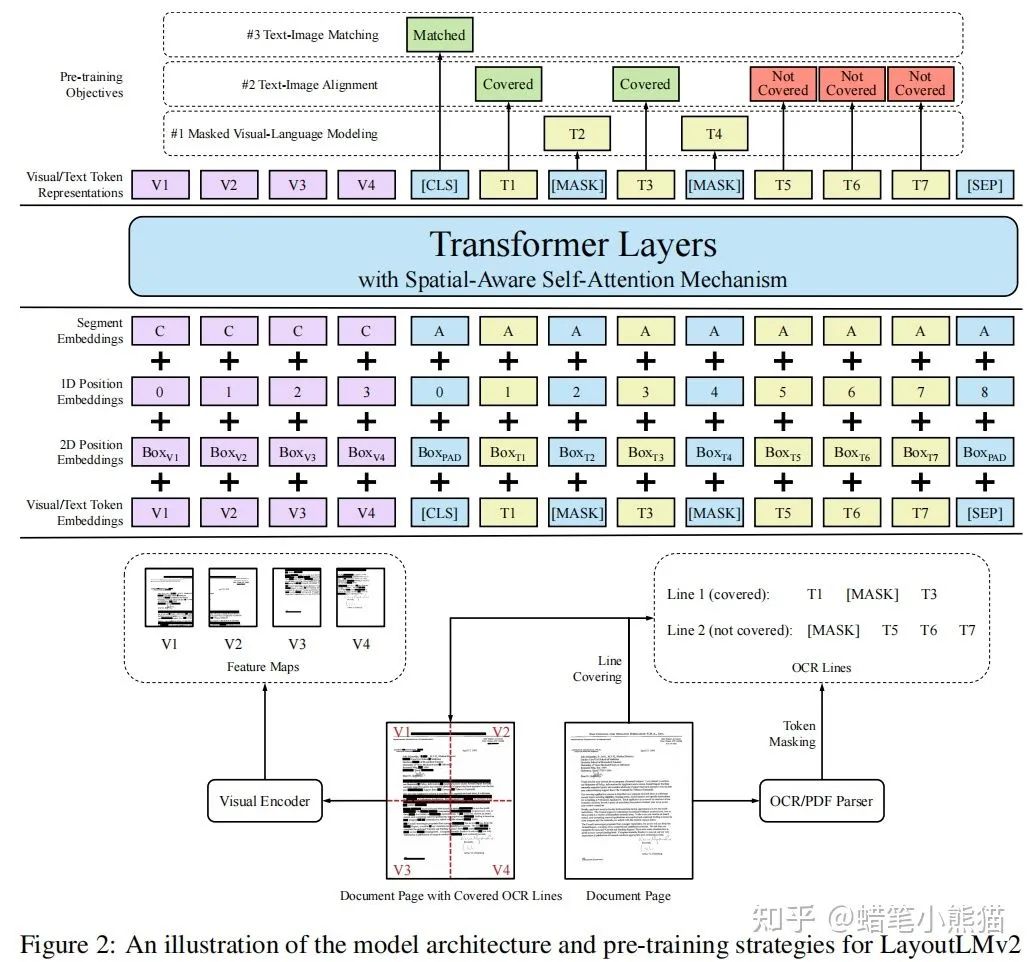
MSRA的LayoutLMv2,把layout信息的embedding和文本的embedding相加,然后再把image的embedding做concat送入Transformer
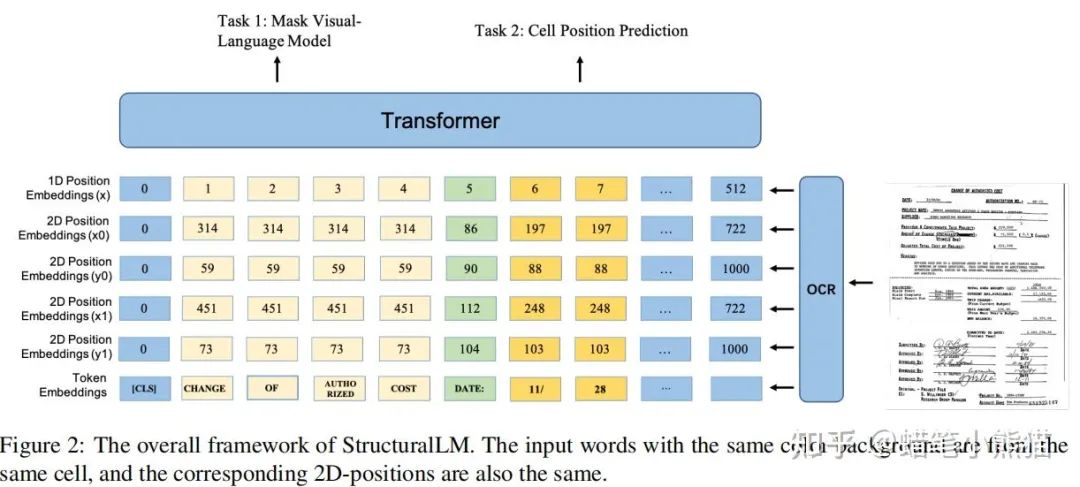
阿里达摩院的StructuralLM,将文本和layout的embedding相加送入Transformer

CMU的TABERT,将表格信息的embedding与文本信息的embedding相concate,还做了个Vertical Self-Attetion
多模态的Transfomer模型大抵如此,其实很暴力,你就想办法把特征提出来做成embedding塞进模型,接上下游任务,然后祈祷神奇的self-attention开始运作即可
参考文献:
Writing by Memorizing: Hierarchical Retrieval-based Medical Report Generation
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding
StructuralLM: Structural Pre-training for Form Understanding
TaBERT: Pretraining for Joint Understanding of Textual and Tabular Data
李沐:自注意力和位置编码 - 动手学深度学习

霍华德回答:
真的吗 ?真的吗?
有些任务transformer不见得是最优解吧!
transformer敢拿出来在youtube8m上和nextvlad比比吗?
终究还是要看任务目标吧!
多模态识别主要是挖掘不同模态之间的互补性,其核心在于怎么做图像和文本的融合。
多模态匹配的重点在于如何将图像和文本这两种模态特征进行对齐。
首先,transformer这个结构最先提出是用在机器翻译上的,它诞生之初就只是单一模态的模型。并且是经典的encoder decoder结构是设计来为sequence to sequence任务服务的。你很难看出他有什么针对多模态的特殊设计。
然后bert火了,成为了最强文本模型。然后多模态火了,为了不失去bert这个最强文本模型,同时把单一模态的bert扩展到多模态比较容易,就诞生了一批基于transformer的多模态模型。
但这些模型设计在我看来并不是最优,文本一侧是bert,图像一侧是resnet提特征,怎么看都比较别扭。最明显一点就是两侧的粒度都没有对齐,文本侧是token字或词,而图像侧是全局特征。比较好的建模方式,应该把图像的局部特征也转化为视觉词,形成一个类似SIFT时代码表的东西,这样文本词就可以和视觉词对齐。这样的模型就非常漂亮了。
显然有不少研究者也发现了这个问题。所以用ViT的方式来表征是视觉,把图片分割成16×16的patch来代表视觉词,此时粒度上就有了对齐的感觉了。但依然还比较粗糙,图片里各种大大小小的物体,不可能用一个固定大小的patch来准确捕捉所有语义。
到此为止,在transformer基础上进行了一系列改进,才使得transformer开始适合多模态任务,但依然有很多需要改进的点。但总体上来说,我对transformer多模态模型依然还是很乐观的。
来源:知乎
文章转载自知乎,著作权归属原作者,侵删
——The End——

推荐阅读
视觉Transformer BERT预训练新方式:中科大、MSRA等提出PeCo,优于MAE、BEiT


















 1428
1428

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









