






作者:归来仍是少年@知乎
一、前言
自从chatgpt的爆火,也同时引发了国内大模型的热潮,像百度出了文心一言、阿里出了通义千问等,但是这些大模型并未开源,国内外开源的中等规模的模型有meta的LLaMA,斯坦福基于LLaMA微调的Alpaca,国内的chatglm,这种能够让一般的公司来做微调。现在国内一般微调比较多的模型应该是chatglm,chatglm刚出来的时候少资源情况下只能微调几层,微调效果不好,后续引入了p tuning v2的方法来少资源微调。同样还有另一种方法来微调,peft包中就集成Lora的方法,下面我会详细介绍下两种方法的区别。
二、p tuning v2
p tuning v2并不是一个新技术,而是之前用于少样本学习,少样本学习分为离散型模板和连续性模板,离散性模板主要是构建文字描述模板,而连续型模板则是插入连续型token构成的模板,之前文章中我也讲述了离散型和连续型两种prompt方法。
p tuning v2简单来说其实是soft prompt的一种改进,soft prompt是只作用在embedding层中,实际测试下来只作用在embedding层的话交互能力会变弱,而且冻结模型所有参数去学习插入token,改变量偏小使得效果有时候不太稳定,会差于微调。p tuning v2则不只是针对embedding层,而是将连续型token插入每一层,增大改变量和交互性。
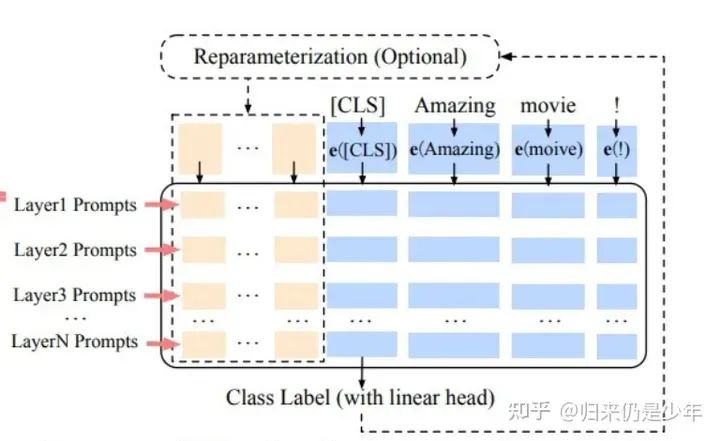
p-turning v2结构
soft prompt比较依靠模型参数量,在参数量超过10B的模型上,效果追上了fine-tune,但是p tuning v2因为每层插入了token,增大模型训练的改变量,更加适用于小一点的模型。
chatglm使用p tuning v2微调代码:
https://github.com/THUDM/ChatGLM-6B/tree/main/ptuning
三、Lora
Lora主要在模型中注入可训练模块,大模型在预训练完收敛之后模型包含许多进行矩阵乘法的稠密层,这些层通常是满秩的,在微调过程中其实改变量是比较小的,在矩阵乘法中表现为低秩的改变,注入可训练层的目的是想下游微调的低秩改变由可训练层来学习,冻结模型其他部分,大大减少模型训练参数。
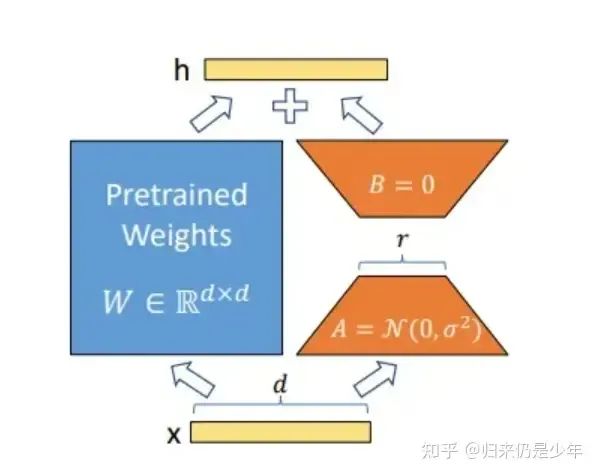
LoRA结构
这种方法有点类似于矩阵分解,可训练层维度和预训练模型层维度一致为d,先将维度d通过全连接层降维至r,再从r通过全连接层映射回d维度,r<<d,r是矩阵的秩,这样矩阵计算就从d x d变为d x r + r x d,参数量减少很多,上图对矩阵A使用随机高斯初始化,对矩阵B使用0进行初始化。
推理计算的时候,因为没有改变预训练权重,所以换不同的下游任务时,lora模型保存的权重也是可以相应加载进来的,通过矩阵分解的方法参数量减少了很多,且推理时可以并行,对于推理性能并没有增加多少负担,算是比较好的低资源微调方法。
Lora方法包实现:
https://github.com/huggingface/peft
四、总结
两者对于低资源微调大模型的共同点都是冻结大模型参数,通过小模块来学习微调产生的低秩改变。但目前存在的一些问题就是这两种训练方式很容易参数灾难性遗忘,因为模型在微调的时候整个模型层参数未改变,而少参数的学习模块微调时却是改变量巨大,容易给模型在推理时产生较大偏置,使得以前的回答能力被可学习模块带偏,在微调的时候也必须注意可学习模块不能过于拟合微调数据,否则会丧失原本的预训练知识能力,产生灾难性遗忘。
最好能够在微调语料中也加入通用学习语料一起微调,避免产生对微调语料极大的偏向,在instruct gpt论文中也提到在强化学习ppo的时候模型也会很容易对于ppo数据拟合,降低模型通用自然语言任务能力,所以在ppo loss中加入了SFT梯度和预训练梯度来缓解这种遗忘问题。

分享
收藏
点赞
在看
B
使用0进行初推理计算的时候,因为没有改变预训练权重,所以换不同的下游任务时,lora模型保存的权重也是可以相应加载进来的,通过矩阵分解的方法参数量减少了很多,且推理时可以并行,对于推理性能并没有增加多少负担,算是比较好的低资源微调方法















 1048
1048











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









