






 深言科技与清华大学NLP实验室联合研发的LingoWhale-8B大语言模型已开源,拥有80亿参数,表现出色。模型在多项评估基准上达到领先,提供Huggingface接口和微调示例,但存在幻觉问题等挑战。
深言科技与清华大学NLP实验室联合研发的LingoWhale-8B大语言模型已开源,拥有80亿参数,表现出色。模型在多项评估基准上达到领先,提供Huggingface接口和微调示例,但存在幻觉问题等挑战。
来源:始智AI wisemoodel

深言科技与清华大学NLP实验室共同研发的语鲸LingoWhale-8B模型(下称LingoWhale-8B)已面向社会开源。LingoWhale-8B模型是拥有约80亿参数的中英双语大语言模型,在C-Eval、MMLU、CMMLU等多个权威的公开评测基准上,在10B以下开源模型中达到领先效果。LingoWhale-8B模型已由官方发布在始智AI wisemodel.cn社区,欢迎前往使用。(https://wisemodel.cn/models)
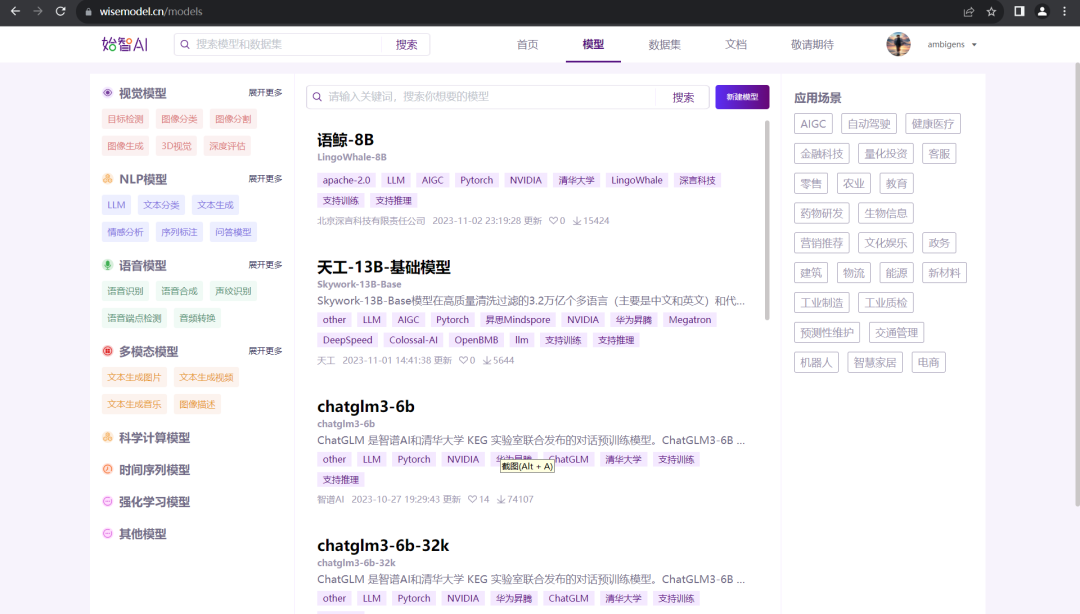
模型介绍
LingoWhale-8B是深言科技与清华大学NLP实验室共同推出的语鲸系列大模型中首个开源的中英双语大语言模型。
LingoWhale-8B模型在数万亿token的高质量中英数据上进行预训练,具有强大的基础能力,在多个公开评测基准上均达到领先效果。在预训练阶段,模型使用8K的上下文长度进行训练,能够完成更长上下文的理解和生成任务。LingoWhale-8B模型对学术研究完全开放,开发者通过邮件申请并获得官方商用许可后,即可免费商用。
在开源模型权重的同时,我们也提供了符合用户习惯的Huggingface推理接口以及LoRA等参数高效微调示例,便于开发者快速使用LingoWhale-8B模型。
受模型参数量影响,大模型固有的幻觉问题、数学计算能力相对较弱、生成内容有无法预见性等问题在LingoWhale-8B模型中仍然存在。请大家在使用前了解这些问题,评估可能存在的风险。后续版本的语鲸大模型将会针对此类问题进行持续优化。
测评结果
模型在以下公开评测基准上进行了测试:
C-Eval是一个中文基础模型评估基准,包含了13948个多项选择题,涵盖了52个不同的学科和四个难度级别。它旨在评估中文语言模型的能力。我们使用该数据集的dev集作为few-shot的来源,在test集上进行了5-shot测试。
MMLU是一个英文基础模型评估基准,涵盖了基本数学、美国历史、计算机科学、法律等多个领域,共包含57个任务。它用于评估语言模型在不同领域任务上的表现。我们对模型进行了5-shot测试。
CMMLU是一个中文评估基准,涵盖了从基础学科到高级专业水平的67个主题。它用于评估中文语言模型在知识和推理能力方面的表现。我们使用该数据集的dev集作为few-shot的来源,在test集上进行了5-shot测试。
Gaokao是一个以中国高考题目为数据集的评估基准。它旨在提供测评中文语言模型在语言理解能力和逻辑推理能力方面的能力。我们只保留了其中的四选一的选择题,随机划分后对模型进行了5-shot测试。
HumanEval是一个包含上百个编程问题的英文评估基准。它用于评估语言模型在程序理解与生成能力方面的表现。我们采用了zero-shot计算Pass@1的方法对模型进行了测试。
GSM8K是一个由高质量、语言多样化的小学数学应用题组成的数据集。它要求根据给定的场景选择最合理的方案,用于评估语言模型在数学应用方面的能力。我们对模型进行了8-shot测试。
BBH是一个从204项Big-Bench评测基准任务中选择出的表现较差的任务单独形成的评估基准。它用于评估大型语言模型在具有挑战性的任务上的表现。我们对模型进行了3-shot测试。
AGIEval是一项考察基础模型类人能力的基准测试,专门用于评估基础模型在人类认知和问题解决相关任务中的能力。我们只保留了其中的四选一的选择题,随机划分后对模型进行了5-shot测试。
这些评估基准提供了标准化的测试和度量,用于评估语言模型在不同任务和领域上的性能和能力。评测方法和测评结果如下表所示:

生成样例
1、计算:

LingoWhale-8B模型具有强大的数学运算能力。在以上示例中,LingoWhale-8B模型能够根据上文正确地列式并进行运算,包括函数求导、函数值计算、切线方程计算等操作,并最终得到结果。
2、代码生成

LingoWhale-8B具有强大的代码理解与生成能力,能够更好地生成代码并解决具体的问题。在本示例中,LingoWhale-8B模型生成了详细的python代码以及注释信息,帮助用户更好地理解并使用生成的代码。
3、逻辑与推理
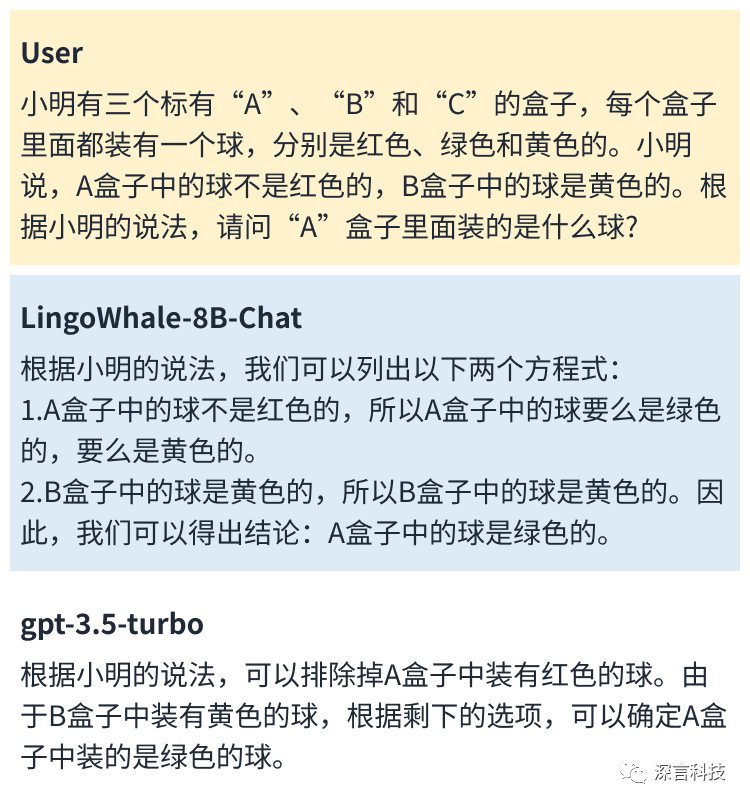
LingoWhale-8B模型具有解决复杂逻辑推理任务的能力。在以上的例子中,LingoWhale-8B将复杂的逻辑问题进行拆解,按步骤进行分析并解决问题。
4、上下文对话

在以上示例中,LingoWhale-8B模型表现出了较强的角色扮演、方案设计、长文本理解以及多轮对话能力,能够根据用户需求制定方案并组织结构化的输出,应对更加复杂的任务场景。
5、知识百科

经过在大规模高质量语料上的预训练,LingoWhale-8B模型掌握了多个领域的知识,包括科学、历史、文学、艺术等,能够理解并回答各种知识相关问题,提供准确详细的答案。在上面两个例子中,相较于GPT-3.5,LingoWhale-8B模型生成的结果更加准确详实。
深言科技(DeepLang AI)成立于2022年3月,孵化自清华大学自然语言处理实验室(THUNLP)和北京智源人工智能研究院(BAAI),旨在打造基于大规模预训练模型的新一代智能文本信息处理引擎,涵盖AIGC文本生成、信息抽取聚合、语义检索等功能,为数亿脑力劳动者和数千万信息密集型组织重塑信息处理全流程。
——The End——

分享
收藏
点赞
在看

















 4588
4588

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









