






来源:新智元
【导读】TII开源全球第一个通用的大型Mamba架构模型Falcon Mamba 7B,性能与Transformer架构模型相媲美,在多个基准测试上的均分超过了Llama 3.1 8B和Mistral 7B。
今天,阿布扎比支持的技术创新研究所(TII) 开源了全球第一个通用的大型Mamba架构模型——Falcon Mamba 7B。
虽然之前Mistral已经发过Mamba架构的Codestral Mamba模型,但仅针对编码;Falcon Mamba则是通用模型,能够处理各种文本生成任务。
它是继Falcon 180B、Falcon 40B和Falcon 2之后TII的第四个开放模型,与Falcon系列之前的型号不同,Falcon Mamba 7B完全采用SSLM架构而不是传统的Transformer架构。

Mamba架构横空出世后,体现出了内存效率方面的显著优势,无需额外的内存需求即可生成大量文本。
如今,SSLM正在逐渐蚕食Transformer架构原本「大一统」的地位。
测评数据显示,Falcon Mamba 7B性能已经超越同尺寸级别的领先模型,例如Meta最新开源模型Llama 3.1 8B和Mistral 7B。
Falcon Mamba 7B将根据TII Falcon License 2.0发布,这是一个基于Apache 2.0的许可证,其中包括促进负责任地使用人工智能的使用政策。
Falcon Mamba 7B有什么特别之处?
虽然Transformer模型仍然主导着AI大模型领域,但研究人员指出,该架构在处理较长文本时可能会遇到困难。
Transformer的自注意力机制(Self-Attention)让模型可以关注输入序列中的所有位置,并为每个位置分配不同的注意力权重。
这使得模型能够更好地处理长距离的依赖关系,也就是说,对于句子中距离较远的单词,模型也能有效地捕获其关系。
这种通过比较文本中每个token来理解上下文的方式,需要更多的计算能力和内存来处理不断增长的上下文窗口。
如果资源没有相应扩展,推理速度会变慢,最终无法处理超过某个固定长度的文本。
为了解决这些难题,状态空间语言模型(SSLM)架构应运而生,该架构通过在处理单词时持续更新「状态」,已成为一种有前途的替代方案。它已经被一些组织部署,TII是最新的采用者。
这个全新的Falcon模型正是使用了CMU和普林斯顿大学的研究人员在2023年12月的一篇论文中最初提出的Mamba SSM架构。

论文地址:https://arxiv.org/pdf/2312.00752
该架构使用选择机制,使模型能够根据输入动态调整其参数。
通过这种方式,模型可以专注于或忽略特定输入,类似于Transformer中的注意力机制,但同时具备处理长文本序列(如整本书)的能力,而无需额外的内存或计算资源。
TII指出,这种方法使模型适用于企业级机器翻译、文本摘要、计算机视觉、音频处理以及估计和预测等任务。
首个通用大规模Mamba模型
上面提到,基于注意力机制的Transformer是当今所有最强大语言模型中占主导地位的架构。然而,由于计算和内存成本随着序列长度的增加而增加,注意力机制在处理长序列时存在根本限制。
各种替代架构,特别是SSLM,试图解决序列扩展限制,但性能不及最先进的Transformer。
Falcon Mamba模型在不损失性能的前提下,可以突破序列扩展限制。
Falcon Mamba基于去年12月提出的第一版Mamba架构,增加了RMS归一化层以确保在大规模训练中保持稳定性。
这种架构选择确保了Falcon Mamba模型:
- 可以在不增加任何内存存储的情况下处理任意长度的序列,特别是可以在单张A10 24GB GPU上运行;
- 无论上下文大小,生成新token所需的时间恒定。
模型训练
Falcon Mamba使用约5500GT(相当于5.5B token)的数据进行训练,主要由RefinedWeb数据组成,并添加了公共来源的高质量技术数据和代码数据。
在大部分训练中使用了恒定的学习率,随后进行了一个较短的学习率衰减阶段。
在最后阶段,还加入了一小部分高质量的精选数据,以进一步提升模型性能。
性能评估
使用lm-evaluation-harness包对新排行榜版本的所有基准测试进行模型评估,然后使用HuggingFace分数归一化处理评估结果。
如下图所示,Falcon Mamba 7B获得15.04的均分,超过Llama 3.1 8B 13.41分和Mistral 7B 14.50分。
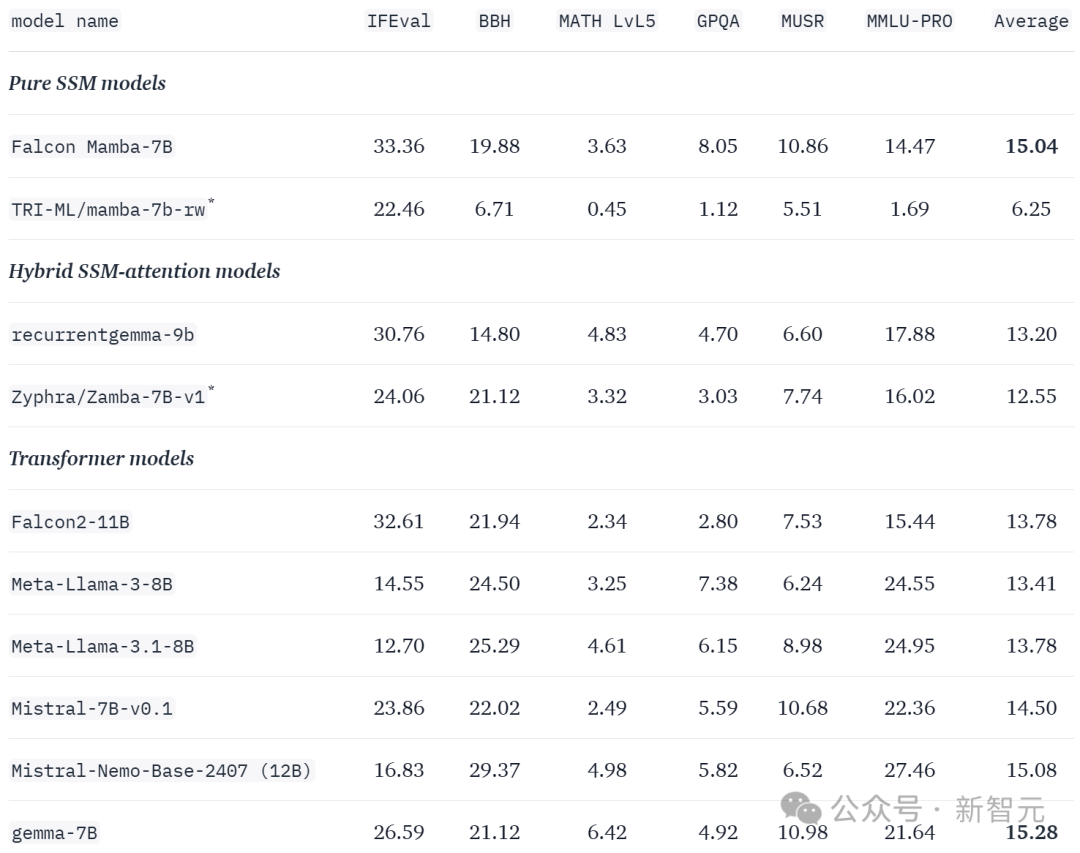
此外,还使用了lighteval对大语言模型排行榜第一版的基准测试进行评估。
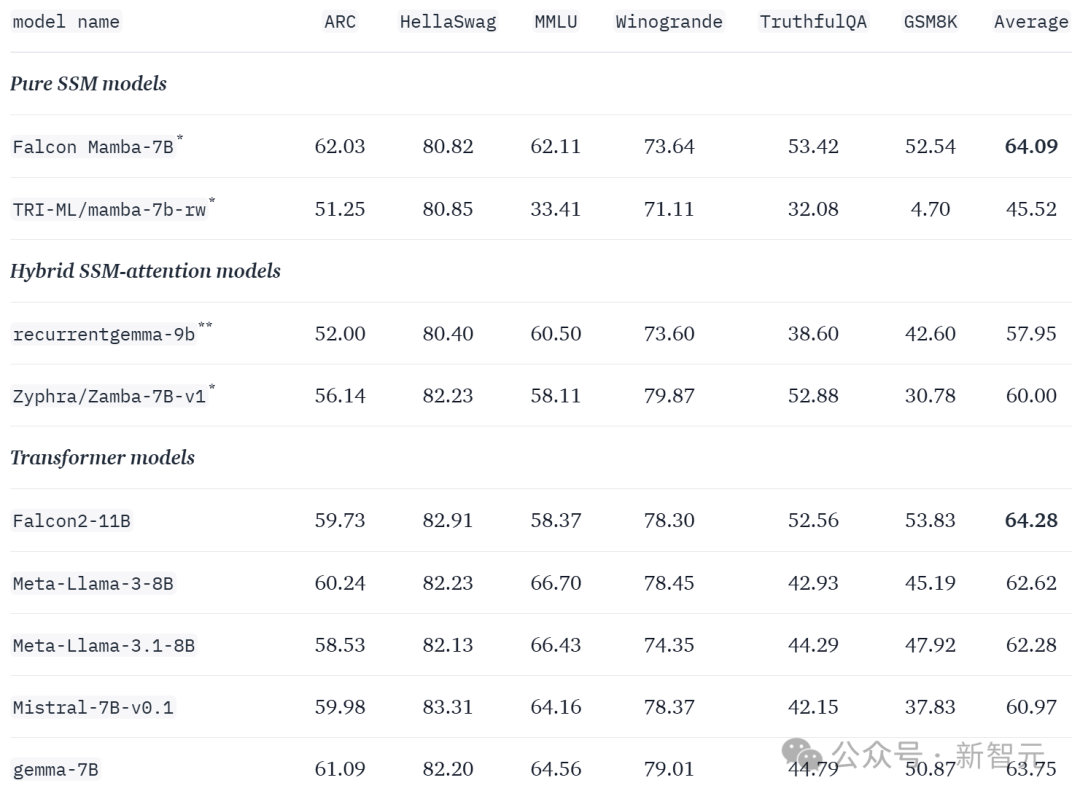
可以看到,Falcon Mamba 7B仅次于Transformer架构的Falcon 2 11B,分数仍然超过Gemma、Llama、Mistral等同等规模的知名模型。
处理大规模序列
理论上来说,SSM模型在处理大规模序列时具有效率优势。
为了验证模型的大规模序列处理能力,使用optimum-benchmark库,对Falcon Mamba和流行的Transformer模型在内存使用和生成吞吐量方面进行了比较。
为了公平比较,将所有Transformer模型的词汇大小调整为与Falcon Mamba一致,因为这对模型的内存需求有很大影响。
在查看结果之前,先讨论序列中提示词(预填充)和生成(解码)部分的区别。
预填充的细节对于SSM而言,比对于Transformer模型更为重要。
当Transformer生成下一个token时,它需要关注上下文中所有先前token的键和值,这意味着内存需求和生成时间都会随着上下文长度线性增长。
而SSM仅关注并存储其递归状态,因此在生成大规模序列时不需要额外的内存或时间。
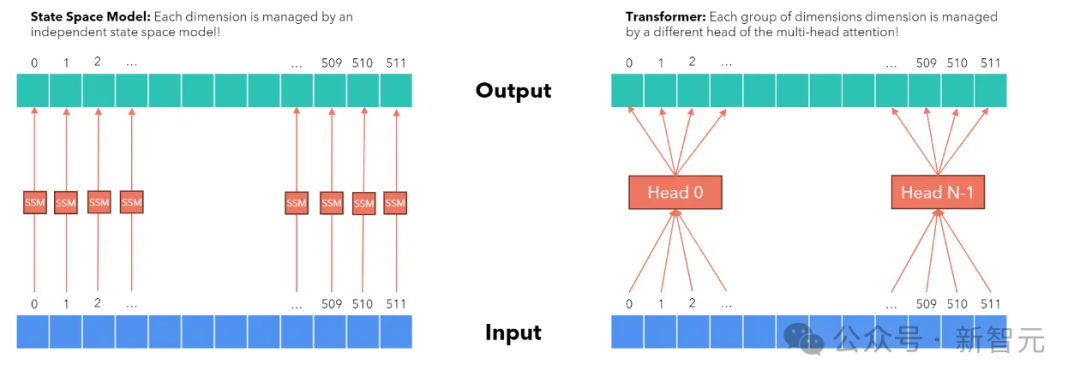
虽然这解释了SSM在解码阶段相对于Transformer的优势,但在预填充阶段需要使用新方法来充分利用SSM架构。
预填充的标准方法是并行处理整个提示词以充分利用GPU。这种方法在optimum-benchmark库中使用,我们称之为并行预填充。
并行预填充需要将提示词每个token的隐藏状态存储在内存中。对于Transformer,这额外的内存主要由存储的KV缓存占据。
对于SSM模型,不需要缓存,存储隐藏状态的内存成为唯一与提示词长度成比例的部分。
因此,内存需求将随提示词长度增长,SSM模型将失去处理任意长序列的能力,类似于Transformer。
并行预填充的替代方法是逐个处理token提示词,我们称之为顺序预填充。
类似于序列并行处理,它也可以大规模地处理提示词,而不是单个token,以更好地利用GPU。
虽然顺序预填充对Transformer意义不大,但它为SSM模型带来了处理任意长提示词的可能性。
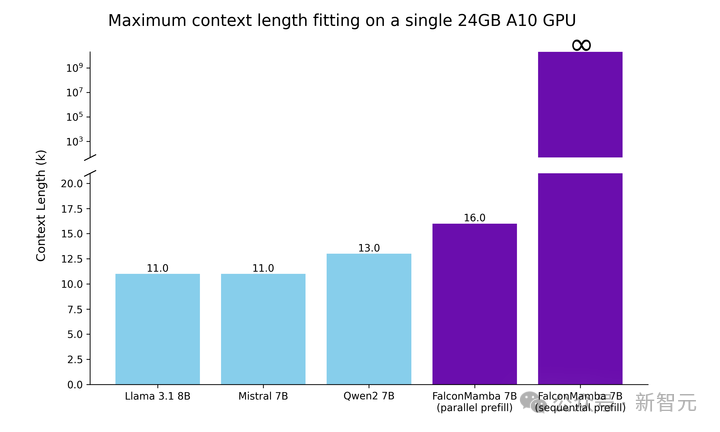
考虑到这些观点,实验首先测试了可以在单个24GB A10 GPU上适应的最大序列长度。
其中,批大小固定为1,使用float32精度。
即使在并行预填充中,Falcon Mamba也能适应比Transformer更大的序列,而在顺序预填充中发挥了全部潜力,可以处理任意长度的提示词。
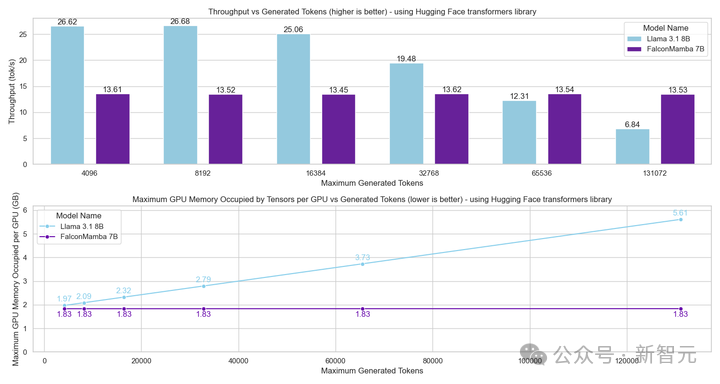
接下来,在提示词长度为1,生成token数量最多为130k的情况下测量生成吞吐量,使用批大小为1,并在H100 GPU上进行。
结果如图所示。可以观察到,Falcon Mamba在生成所有token时保持恒定的吞吐量,且GPU峰值内存没有增加。
而对于Transformer模型,随着生成token数量的增加,峰值内存增加,生成速度变慢。
如何使用?
Falcon Mamba架构将在HuggingFace transformers库的下一个版本(4.45.0以上)中提供。
使用Falcon Mamba 7B模型,需要安装最新版本的HuggingFace transformers,或从源代码安装库。
Falcon Mamba与HuggingFace提供的大多数API兼容,这些API已经比较熟悉,例如:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "tiiuae/falcon-mamba-7b"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype="auto", device_map="auto")
inputs = tokenizer("Hello world, today", return_tensors="pt").to(0)
output = model.generate(**inputs, max_new_tokens=100, do_sample=True)
print(tokenizer.decode(Output[0], skip_special_tokens=True))它还支持例如bitsandbytes库量化这样的功能,以便在GPU内存较小的情况下运行模型,例如:
此外,还推出了Falcon Mamba的指令微调版本,该版本经过额外50亿个token的监督微调(SFT),这种扩展训练提高了模型在执行指令任务时的精确性和有效性。
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
model_id = "tiiuae/falcon-mamba-7b"
tokenizer = AutoTokenizer.from_pretrained(model_id)
quantization_config = BitsAndBytesConfig(load_in_4bit=True)
model = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=quantization_config)
inputs = tokenizer("Hello world, today", return_tensors="pt").to(0)
output = model.generate(**inputs, max_new_tokens=100, do_sample=True)
print(tokenizer.decode(output[0], skip_special_tokens=True))可以通过演示体验该指令模型的功能,对于聊天模板,可以使用以下格式:
<|im_start|>user
prompt<|im_end|>
<|im_start|>assistant用户还可以直接使用基础模型和指令模型的4-bit转换版本,但要保证GPU与bitsandbytes库兼容,才能运行量化模型。
用户还可以通过torch.compile获得更快的推理速度,加载模型后,只需调用model = torch.compile(model)。
参考资料:
https://huggingface.co/blog/falconmamba
https://venturebeat.com/ai/falcon-mamba-7bs-powerful-new-ai-architecture-offers-alternative-to-transformer-models/
https://medium.com/@puneetthegde22/mamba-architecture-a-leap-forward-in-sequence-modeling-370dfcbfe44a
——The End——

分享
收藏
点赞
在看















 650
650

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









