









 该博客介绍了如何利用Python的Scikit-Learn库构建决策树模型进行文本分类。首先,通过创建特征空间和标签,然后将数据划分为训练集和测试集。接着,使用CountVectorizer进行词袋模型转换,构建01矩阵。训练决策树模型并在训练集上评估准确率。最后,绘制决策树图形并展示重要词汇,以理解模型决策过程。
该博客介绍了如何利用Python的Scikit-Learn库构建决策树模型进行文本分类。首先,通过创建特征空间和标签,然后将数据划分为训练集和测试集。接着,使用CountVectorizer进行词袋模型转换,构建01矩阵。训练决策树模型并在训练集上评估准确率。最后,绘制决策树图形并展示重要词汇,以理解模型决策过程。
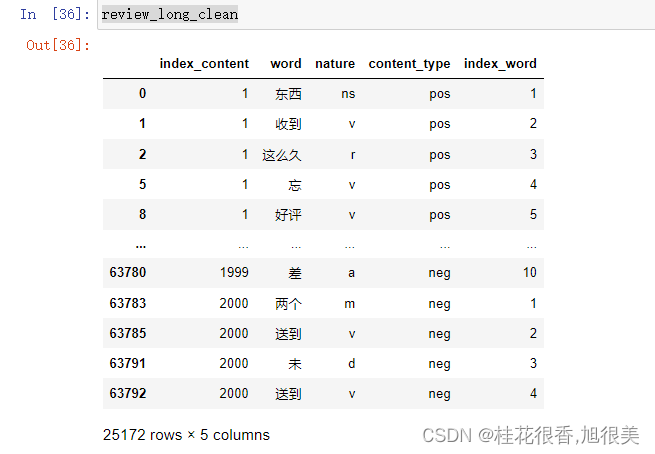
浏览下数据:
from sklearn import tree
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.metrics import classification_report
from sklearn.metrics import accuracy_score
import graphviz
#第一步:构造特征空间和标签
Y=[]
for ind in review_long_clean.index_content.unique():
y=[ word for word in review_long_clean.content_type[review_long_clean.index_content==ind].unique() ]
Y.append(y)
print(len(Y))
X=[]
for ind in review_long_clean.index_content.unique():
term=[ word for word in review_long_clean.word[review_long_clean.index_content==ind].values ]
X.append(' '.join(term))
print(len(X))
print(X[:2])
print(Y[:2])

#第二步:训练集、测试集划分
x_train,x_test,y_train,y_test=train_test_split(X,Y,test_size=0.2,random_state=7)
#第三步:词转向量,01矩阵
count_vec=CountVectorizer(binary=True)
#为了数据归一化(使特征数据方差为1,均值为0),需要计算特征数据的均值μ和方差σ^2
x_train=count_vec.fit_transform(x_train)#训练集训练(归一化)之后词转向量
x_test=count_vec.transform(x_test) # 测试集是训练集训练之后对测试集词转向量
#第四步:构建决策树
dtc=tree.DecisionTreeClassifier(max_depth=5)
dtc.fit(x_train,y_train)
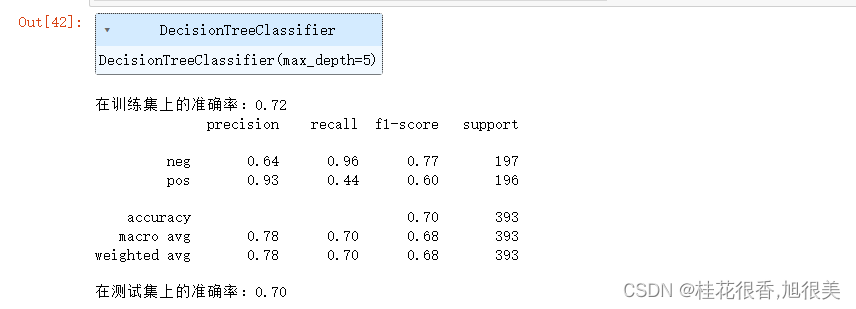
print('在训练集上的准确率:%.2f'% accuracy_score(y_train,dtc.predict(x_train)))
y_true=y_test
y_pred=dtc.predict(x_test)
print(classification_report(y_true,y_pred))
print('在测试集上的准确率:%.2f'% accuracy_score(y_true,y_pred))
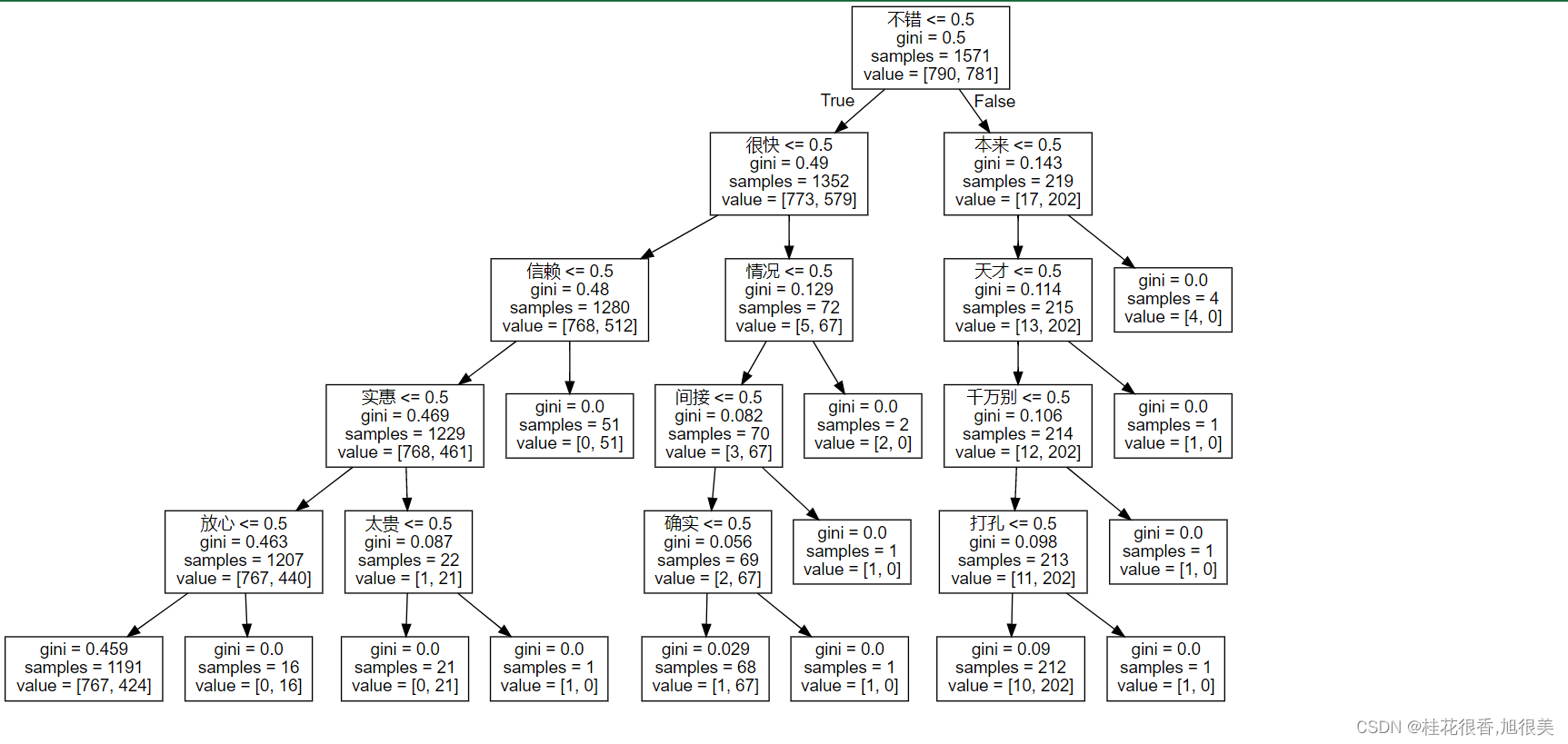
#第五步:画决策树,查看重要词汇
cwd=os.getcwd()
dot_data=tree.export_graphviz(dtc
,out_file=None
,feature_names=count_vec.get_feature_names())
graph=graphviz.Source(dot_data)
graph.format='svg'
graph.render(cwd+'/tree',view=True)
#graph

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









