







Variational Auto-Encoder 变分自编码器
严格来说,VAE 实现的是“文本重建”,它虽然也包含“编码器”和“解码器”两个部分,但和 NLP 中的 encoder-decoder 架构还是有所区别。最大的差异在于,VAE 发源于 CV,它天然地不具备“序列性”。
在 VAE 中,输入序列的每个词可以是相关的,也可以互相独立的,这取决于你使用什么样的编码器。但是,输出序列中的每个词,一定是互不依赖的。它们被各自建模,同时生成。为了便于理解,我们暂且将重建任务看成是对单个词的建模。这一过程可以用更广义的分布-采样概念来描述:
对于一个离散样本X,计算其概率分布,根据分布表达式进行采样,生成新的离散样本 X' 。令 X' 无限逼近 X。
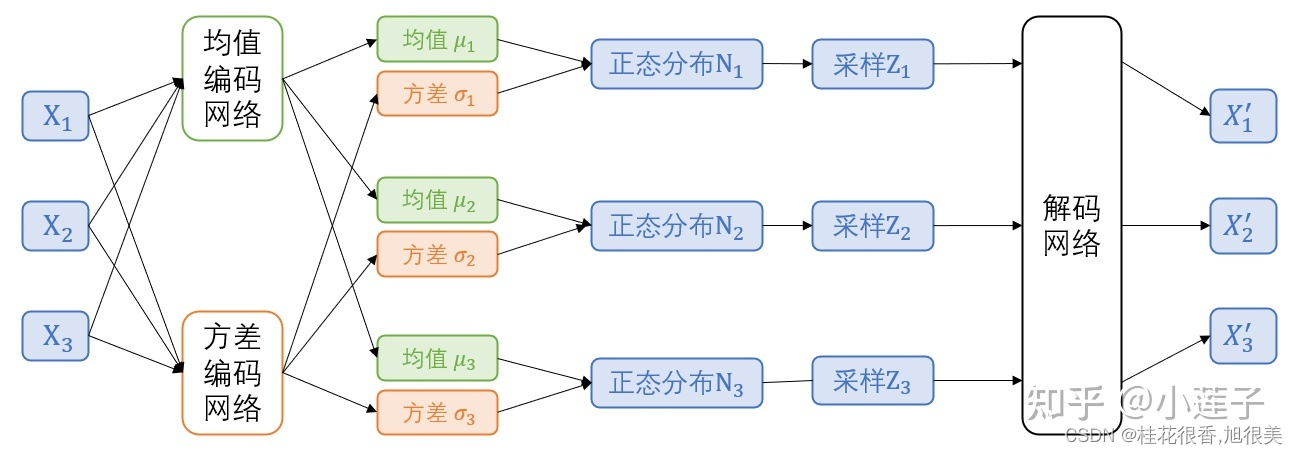
果用 encoder-decoder 的术语来说,“计算概率分布”即“编码”,“分布表达式”即隐层,“采样生成”即“解码”。这里有一个难点。X 是个离散变量,它很有可能服从某个奇奇怪怪的分布,根本就写不出具体的表达式,更别提根据表达式来采样了。因此,VAE 以正态分布作为搭桥,先将 X 变换到正态分布 N(X) 上,再根据公式进行采样得到 Z,对 Z 进行变换生成 X’。至于 X -> N(X) 和 Z -> X’,就直接扔进神经网络学出来。一个特定的正态分布,只由均值和方差决定。因此,X -> N(X) 的变换,实际使用了两个神经网络,分别估算均值 和方差 。
当输入的是 n 个词组成的句子时,在每个词位置都需要进行上述处理。也就是说,有 n 组正态分布,对应着 n 组均值和 n 组方差。
在前向计算过程中,每个 X 都是 embedding 向量,经编码产生的均值和方差也同样是向量(假设维度为dim)。那么,实际上生成了 dim 个正态分布,它们各自独立采样,组成维度为 dim 向量 Z。
从 Pytorch 示例代码中可以更直观地看到数据流向:
embed = F.relu(self.fc1(x)) # embedding.
# 编码部分.
u = self.fc21(embed) # 均值.
sigma = self.fc22(embed) # 方差.
# 重参数采样.
# 通过对标准正太分布叠加均值和方差来进行.
std = sigma.mul(0.5).exp_()
eps = torch.FloatTensor(std.size()).normal_()
eps = Variable(eps)
z = eps.mul(std).add_(u)
# 解码部分.
h = F.relu(self.fc3(z))
x_hat = F.sigmoid(self.fc4(h))
VAE 的优化目标分为两部分。第一部分是重建目标,即 X’ = X:
loss1 = nn.MSELoss(x_hat, x)
在不加入额外约束项时,模型可以很轻松地做到 100% 地还原 X,只要让方差全部为 0,均值取原值即可。显然,这样的模型是不具备真正生成能力的。因此,VAE 的优化目标还包含第二部分,使用 KL 散度把 Z(X) 拉向标准正太分布N(0, I)。可以理解为正则化项,或是对生成网络加噪。
KLD = u.pow(2).add_(sigma.exp()).mul_(-1).add_(1).add_(sigma)
loss2 = torch.sum(KLD).mul_(-0.5)
两个 loss 互相对抗,同步学习优化。
参考:
https://zhuanlan.zhihu.com/p/347339015















 7426
7426











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









