







本文是关于参与openi活动使用的实验平台的教程,与华为云ModelArts的使用流程大体相近,亦有一定程度的参考价值。
目录
一、初次登录平台
平台管理员会为每个参与活动的同学分配一个账号,使用这个账号登录实验平台。

初次登录会提示更新密码,按提示更新密码。

更新密码后,进入平台首页。
- 点击左上角的三道杠,打开服务列表;
- 选择服务器地址,具体选择哪项请询问指导老师,此项一定注意要选择正确,否则不能正常使用;
- 选择“ModelArts”,进入实验平台。
(右上角提示点击图钉标志可收藏服务,便于下次使用。)

ModelArts界面如下,收藏的服务可在左边栏显示。

二、访问授权
初次登录账号需要进行一系列访问授权才能正常使用平台。具体操作步骤如下。
在ModelArts界面点击右上角用户名位置的下拉栏,选择“个人设置”。进入个人设置界面。

管理访问密钥 – 新建访问密钥

出现如下警告,点击“确认”后会下载一个csv文件。


Excel打开文件内容如下:
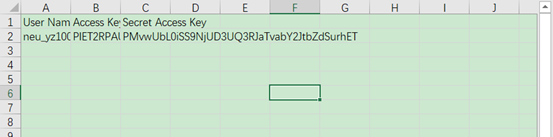
开始进行访问授权。
回到ModelArts界面,点击左侧边栏最下方的全局配置。

进入“全局配置界面”后,点击访问授权,在弹出的窗口内选择使用访问密钥,填入csv文件中的密钥后点击同意授权。

如有类似提示,点击确定即可。

回到ModelArts界面,在左侧边栏中选择训练管理–训练作业。景象一片祥和说明没有任何问题。

若存在如下错误,请重复上述授权步骤。

三、创建训练作业
创建训练作业之前需要先对桶进行必要的配置和对脚本进行必要的修改,然后将脚本、数据集等文件上传到桶中。之后再在ModelArts中创建作业。
3.1 桶(OBS)的配置
登录界面如下。
用户名:自定义;
服务器地址:112.95.163.82;(一般情况下是这个地址,如果出现问题请询问指导老师。)
访问密钥:之前访问授权时下载的CVS文件内容;
访问路径:空着即可。
点击登录。

登录成功后,点击创建桶,为自己创建一个存储文件的位置。
区域:如图;
桶ACL:因为是实验室内部使用,权限随便选就行;
桶名称:自定义。
点击确定创建成功。

通过拖拽的方式,可将脚本、数据集上传到桶里。

项目目录结构建议调整为如下形式,以避免出现 ModelNotFoundError 这样的错误,以及不必要文件的重复上传造成时间和资源的浪费。
OBS/PROJECT
├ dataset # 数据集
├ train_outputs # 训练结果(checkpoint)输出位置
├ eval_outputs # 验证结果输出位置
├ model_files # 代码目录
│ ├ src # model.py、loss.py等等......
│ │ └ [other files]
│ ├ train.py # 训练启动文件
│ └ eval.py # 验证启动文件
(注意:建议将存放脚本、数据集、训练结果的文件夹分为并列三个(如上图所示)。作业在准备阶段需要将这些文件从“桶”传入到“容器”中。如果将训练结果和脚本置于相同路径下,每次训练都会将之前的训练结果一同上传,造成不必要的时间浪费。)
3.2 调整脚本
(建议:如果对此步感到模糊,可以先看第三步创建作业,大概了解部署作业的步骤或许有助于理解本步骤工作。)
本文以Model_Zoo中HRNet为例。
在ModelArts中执行脚本时,先是在初始化过程中将脚本、数据集等相关文件从**桶(obs)上传到容器(container)**中,作业执行过程中都是从容器中读取文件信息。作业执行产生的文件,最终也要从容器存到桶中。
一般情况下,需要在桶于容器间传递的文件包括:数据集、预训练模型和输出的checkpoint文件。
- 添加必要的选项。
data_url和train_url是必须要添加的参数,分别表示数据和输出结果存放的位置。

- 设置moxing
moxing所做的工作便是桶与容器之间文件的传递。
详细步骤请参照下图。

59行确定是在云上训练;
60行引入moxing;
61、65、67、68行分别声明了该作业数据集、预训练模型、输出结果、训练数据列表文件在容器中的存储位置,均需要以“/cache”开头,其余内容自己定义。注意容器中的文件名后缀需要与桶里的一样,例如上图中“.ckpt”和“.lst”。
62、66、69行意为将文件从桶复制到容器。

193行意为训练结束,将训练结果从容器复制到桶中。
3.3 创建作业
建议:初次运行脚本,可先采用小数据集单卡调试以节省时间和资源。确保单卡正常运行之后再部署多卡作业。
进入ModelArts–训练管理–训练作业界面。在训练作业分栏下点击创建。

填写训练作业的必要信息。
- 算法来源处选择常用框架;
- AI引擎:选择Ascend相关的选项,然后选择合适的mindspore版本;

- 代码目录:点击选择按键,在自己创建的桶下导入脚本的存储路径。

- 启动文件:同上,在桶中找到需要执行的脚本,例如:train.py。
- 数据来源:选择数据存储位置,同上导入数据集在桶中的位置。

- 训练输出位置:用于存放脚本执行结果的路径,例如存放checkpoint文件的路径。操作同上。
- 运行参数:
运行参数指的便是我们在脚本中利用args设置的参数。
经过5、6两步,系统会为您自动添加train_url和data_url,分别指代训练输出和数据集的在桶中的存放位置。
其余参数根据脚本中的具体情况自行添加。(注意:路径参数应使用绝对路径,即obs://开头,例如图中的pretrained_ckpt参数。)

- 资源池:选择专属资源池,根据需求选择规格中卡的数量。

(可选择勾选保存作业参数,便于创建新作业时使用。)
一起准备就绪之后,点击右下角的立即创建。开始作业。


作业的状态会经历初始化–排队中–训练中–训练完成几个过程。出现问题时会呈训练失败的状态。
作业一般会在一分钟,五分钟,半小时这些时间点出现报错信息,一般十分钟内没有训练失败就没什么大问题了。可以美美地喝上一口茶。
训练过程中的日志信息及报错信息可在日志栏中查看。

可能出现的错误:
- 在部署训练作业过程中出现算法来源、资源池、桶等找不到的情况,请查看服务器位置是否选择正确、密钥是否匹配、授权是否成功;
- 若是在训练过程中出现File not found相关的错误,请检查moxing的路径配置是否正确。
四、Notebook:在线编辑器
Notebook是ModelArts中集成的脚本编辑器,可用于直接更改桶中存放的脚本文件。
具体使用步骤如下。
ModelArts界面,开发环境–Notebook–创建。

创建过程和创建作业的过程很相近,此处不再赘述。

启动成功后,打开即可。
五、网络调试经验汇总
神经网络模型、loss不收敛、不下降原因和解决办法
MindSpore官网:精度调优思路和方法
MindSpore官网:精度调优
欢迎在评论区分享相关好文!!!















 1863
1863











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









