







 本文介绍了作者如何通过Python爬取大众点评前650家咖啡店的数据,面对字体反爬措施,作者详细阐述了获取字体文件、解码加密字体以及替换过程,最终成功提取所需信息。数据清洗后的分析将在后续文章中分享。
本文介绍了作者如何通过Python爬取大众点评前650家咖啡店的数据,面对字体反爬措施,作者详细阐述了获取字体文件、解码加密字体以及替换过程,最终成功提取所需信息。数据清洗后的分析将在后续文章中分享。
1. 本文就当时爬取的方法做解说,不代表现在大众点评的情况,所以数据也只是当时爬取下来的数据,现在肯定也有变化!
2. 如果大众点评现在更改反爬措施,请自行修改代码,谢谢理解!
趁着疫情期间不能出门,于是掌柜的就继续在家捯饬代码。之前看到有个写了关于成都火锅店的数据分析,掌柜的看完后觉得想弄个咖啡店(因为喜欢喝咖啡☕),说干就干。结果在开头就碰钉子,大众点评的反爬措施不得不说一句:“厉害👍!” 之所以这么说是因为发现他们家的数据是不开F12看着都正常,一开就是全是下面这样:
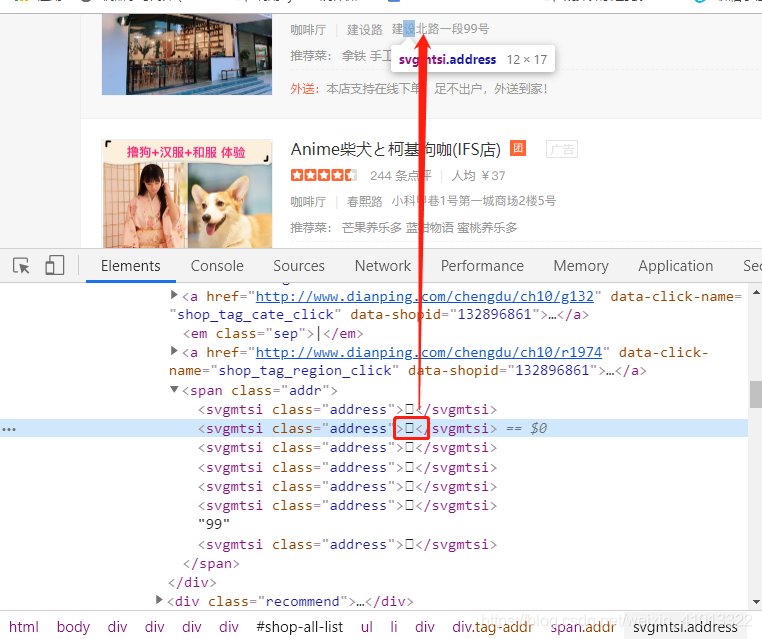
然后查看多个咖啡店的信息都是如此,后来搜索后知道这就所谓的字体反爬!!!大众点评采用的反爬措施就是每隔一段时间(可能一天或者半天)就会对网上的字体文件进行替换;而且这个字体文件还不止一种。。。就是说同一个页面里面address标签对应一个字体文件,tagName标签又对应另一个字体文件等。
所以解决的思路就是:首先需要先获取字体文件,再用字体文件对爬取的加密代码进行解密,最后将解密的代码与之前的代码进行替换,生成我们所需的正常可见文字信息。
- 第一步,获取点评网的字体文件;
打开大众点评网页,点击右键“检查”,看得如下页面,选择Source位置,就可以看到这个页面有哪些文件,然后我们要找的字体文件是在s3plus这两个链接,先点击下面com这个链接文件,可以看到所有标签分别对应哪个字体;接着点击上面net文件,找到今天大众点评所用字体文件。 这里是两个,右键选择在新的标签页打开,就可以下载下来。
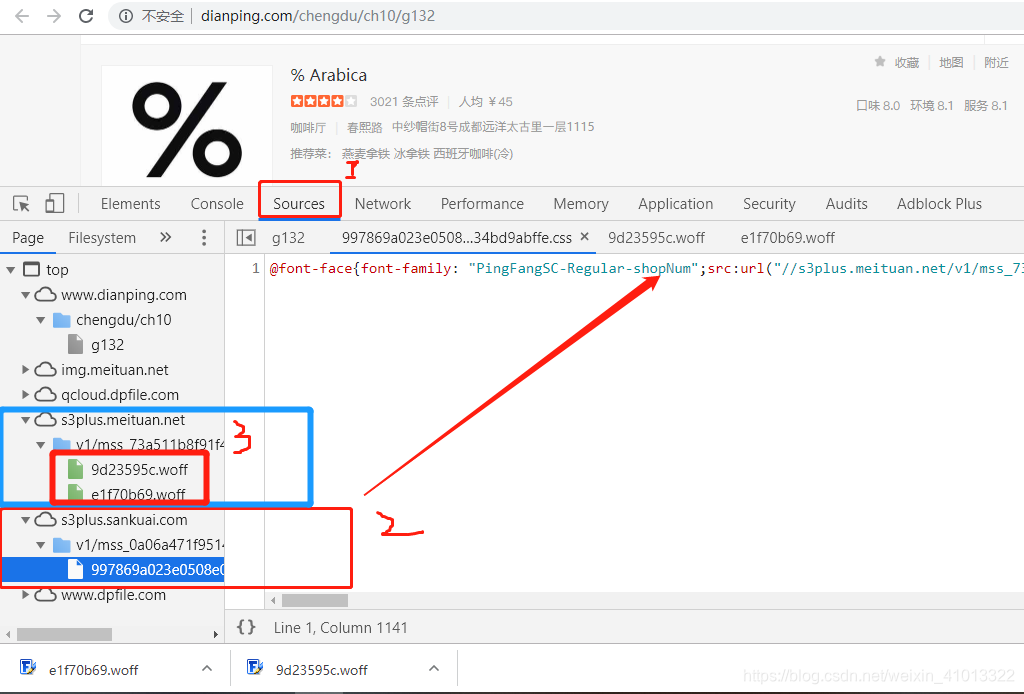

2. 第二步,观察字体文件的规律然后对加密字体进行解码。
首先我们需要一个叫FontCreator的软件来查看字体文件里面的字体信息。把刚刚的字体文件分别在FontCreator里面打开就是如下界面:
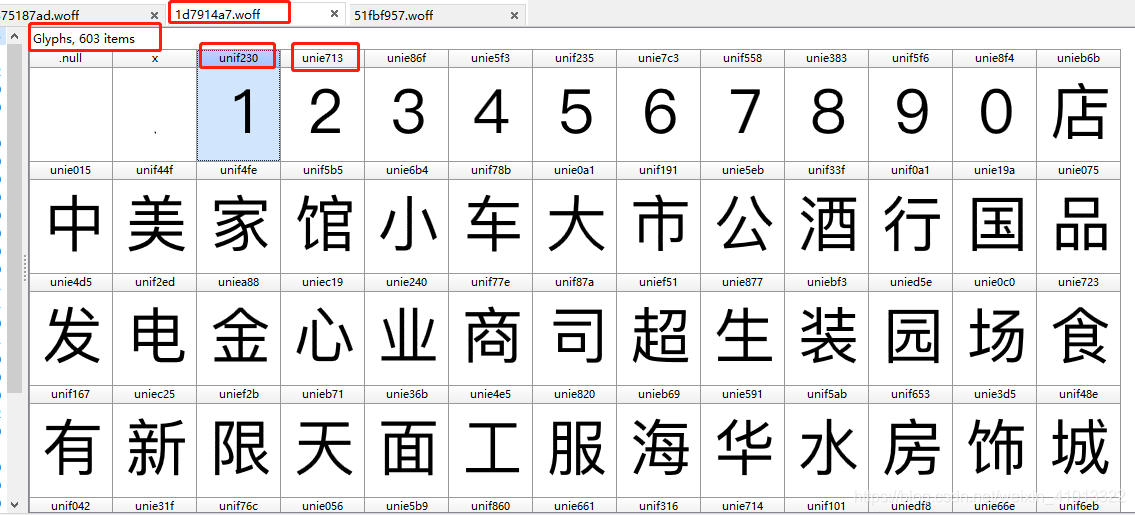
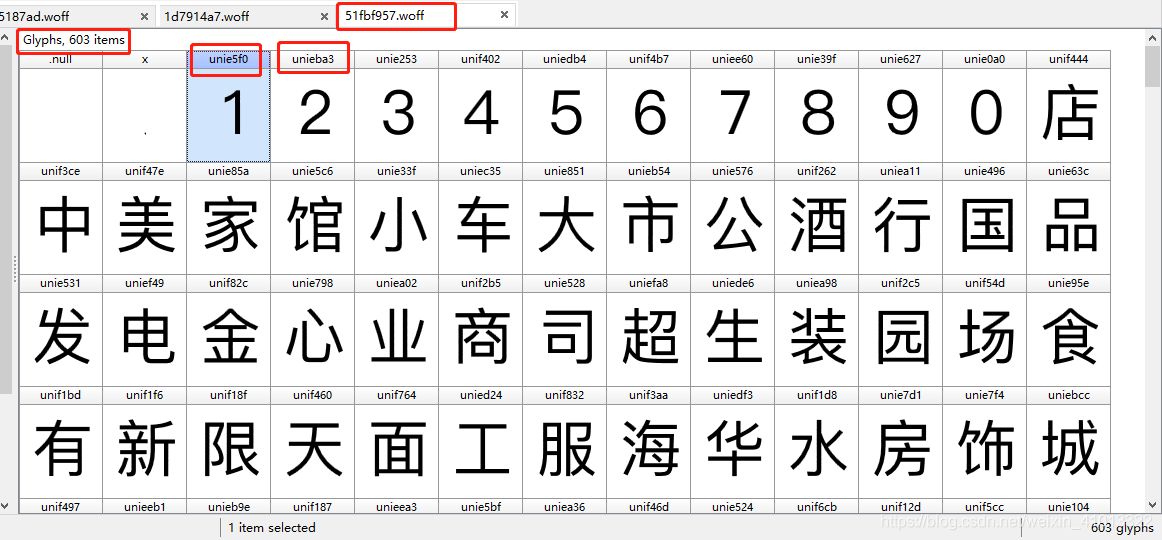
然后观察大众点评所使用的两个不同的字体文件,你就会发现虽然字体上面的编码不一样,但是每个字体文件里的字体内容是一样的。
所以就得到这样一个含有603个字体的文字列表:
texts = ['','','1','2','3','4','5','6','7','8',
'9','0','店','中','美','家','馆','小','车','大',
'市','公','酒','行','国','品','发','电','金','心',
'业','商','司','超','生','装','园','场','食','有',
'新','限','天','面','工','服','海','华','水','房',
'饰','城','乐','汽','香','部','利','子','老','艺',
'花','专','东','肉','菜','学','福','饭','人','百',
'餐','茶','务','通','味','所','山','区','门','药',
'银','农','龙','停','尚','安','广','鑫','一','容',
'动','南','具','源','兴','鲜','记','时','机','烤',
'文','康','信','果','阳','理','锅','宝','达','地',
'儿','衣','特','产','西','批','坊','州','牛','佳',
'化','五','米','修','爱','北','养','卖','建','材',
'三','会','鸡','室','红','站','德','王','光','名',
'丽','油','院','堂','烧','江','社','合','星','货',
'型','村','自','科','快','便','日','民','营','和',
'活','童','明','器','烟','育','宾','精','屋','经',
'居','庄','石','顺','林','尔','县','手','厅','销',
'用','好','客','火','雅','盛','体','旅','之','鞋',
'辣','作','粉','包','楼','校','鱼','平','彩','上',
'吧','保','永','万','物','教','吃','设','医','正',
'造','丰','健','点','汤','网','庆','技','斯','洗',
'料','配','汇','木','缘','加','麻','联','卫', 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 679
679

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









