







FCN 全卷积网络
Fully Convolutional Networks for Semantic Segmentation
今天实验室停电,无聊把原来的一个分享PPT发上来
语义分割
语义分割是计算机视觉中的基本任务,也是计算机视觉的热点,在语义分割中我们需要将视觉输入分为不同的语义可解释类别,「语义Semantic Segmentation的可解释性」即分类类别在真实世界中是有意义的。
例如,我们可能需要区分图像中属于汽车的所有像素,并把这些像素涂成蓝色。与图像分类,语义分割使我们对图像有更加细致的了解。说白了,就是将图片上所有的像素点进行分类。


CNN与FCN
CNN这几年一直在驱动着图像识别领域的进步。无论是整张图片的分类,还是物体检测,关键点检测等都在CNN的帮助下得到了非常大的发展。

但是图像语义分割不同于以上任务,前面说了,需要预测一幅图像中所有像素点的类别,这是个空间密集型的预测任务。
传统用CNN进行语义分割的方法是“将像素周围一个小区域作为CNN输入,做训练和预测。这样做
- 存储开销大
- 计算效率低下,过多的重复计算
- 如何来确定区域大小,这也限制了感知区域的大小
而FCN能够对图像进行像素级的分类,与经典的CNN在卷积层之后使用全连接层得到固定长度的特征向量进行分类不同,FCN可以接受任意尺寸的输入图像,采用反卷积层对最后一个卷积层的feature map进行上采样,使它恢复到输入图像相同的尺寸,从而可以对每个像素都产生了一个预测, 同时保留了原始输入图像中的空间信息, 最后在上采样的特征图上进行逐像素分类,从而解决语义分割问题。

FCN的几大关键技术
卷积化
经典的CNN分类所使用的网络通常会在最后连接全连接层,它会将原来二维的矩阵压缩成一维的,从而丢失了空间信息,最后训练输出一个向量,这就是我们的分类标签。
而图像语义分割的输出则需要是个分割图,且不论尺寸大小,但是至少是二维的。所以,我们丢弃全连接层,换上卷积层,而这就是所谓的卷积化了。

上采样 Upsampling
上采样也就是对应于上图中最后生成heatmap的过程。
上面采用的网络经过5次卷积+池化后,图像尺寸依次缩小了 2、4、8、16、32倍,对最后一层做32倍上采样,就可以得到与原图一样的大小,现在我们需要将卷积层输出的图片大小还原成原始图片大小,在FCN中就设计了一种方式,叫做上采样,具体实现就是反卷积。

上采样图示
- 卷积
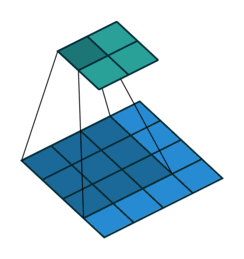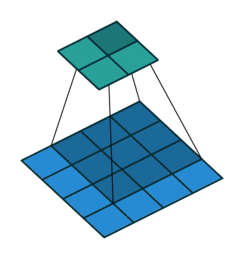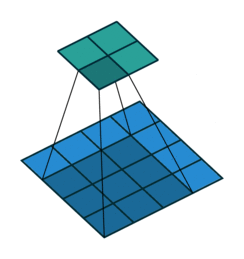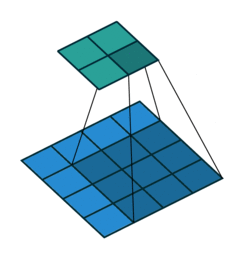
- 反卷积
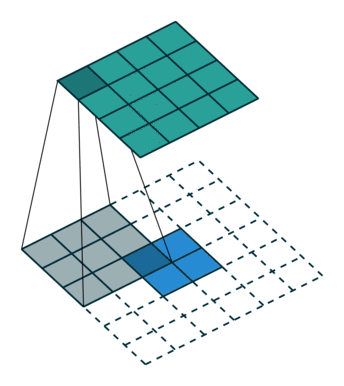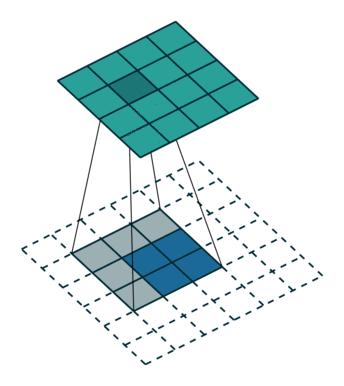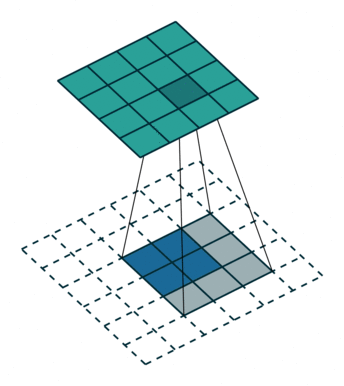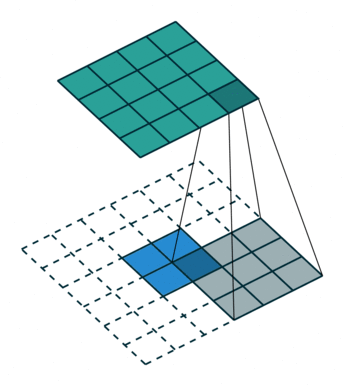
在文章中,作者发现直接做32倍反卷积,结果不精确,所以设计了一种方式来解决这个问题。
FCN结构设计

现在文章有1/32尺寸的heatMap,1/16尺寸的featureMap和1/8尺寸的featureMap,1/32尺寸的heatMap进行upsampling操作之后,因为这样的操作还原的图片仅仅是conv5中的卷积核中的特征,限于精度问题不能够很好地还原图像当中的特征,因此在这里向前迭代。把conv4中的卷积核对上一次upsampling之后的图进行反卷积补充细节(相当于一个差值过程),最后把conv3中的卷积核对刚才upsampling之后的图像进行再次反卷积补充细节,最后就完成了整个图像的还原。
效果
几个指标
- pixel accuracy
- mean accuracy
- mean IU: IU(region intersection over union)
- frequency weighted IU

















 8951
8951

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









