







- 了解DMA 基本概念(参考此处)
1.DMA的前世
在最初的 PC 体系结构中,CPU 是唯一的总线主控器,也就是说,为了提取和存储 RAM 存储单元的数据,CPU 是唯一一个可以驱动地址/数据总线的硬件设备,那么 CPU 就需要承担全部的数据迁移工作,干扰正常的程序执行。随着更多的比如 PCI 总线的出现,如果提供合适的电路基础,每一个外围设备都是可以充当总线主控器,因此每一个设备都可以自主的控制 RAM 和 IO 设备之间的数据传输。这样,CPU 仅仅只需要设置 DMA 需要操作的源地址,目的地址以及数据长度之后,激活 DMA,它就可以自行将数据搬移;在完成传输之后,DMA 再发出一个中断请求通知 CPU 数据迁移完成,剩下的程序逻辑交由 CPU 管理。还有一个小细节,也不是什么时候都一定需要 DMA 的参与,在数据很小的情况下,CPU 自己完成数据迁移效率会比 DMA 更高,毕竟启动 DMA 和切换进程上下文都是需要时间的。
1.1.DMA 的原理和实现
DMA 的原理就是 CPU 将需要迁移的数据的位置告诉给 DMA,包括源地址,目的地址以及需要迁移的长度,然后启动 DMA 设备,DMA 设备收到命令之后,就去完成相应的操作,最后通过中断反馈给老板 CPU,结束。
在实现 DMA 传输时,是 DMA 控制器掌控着总线,也就是说,这里会有一个控制权转让的问题,我们当然知道,计算机中最大的 BOSS 就是 CPU,这个 DMA 暂时掌管的总线控制权当前也是 CPU 赋予的,在 DMA 完成传输之后,会通过中断通知 CPU 收回总线控制权。
一个完整的 DMA 传输过程必须经过 DMA 请求、DMA 响应、DMA 传输、DMA 结束这四个阶段。
- DMA 请求:CPU 对 DMA 控制器初始化,并向 I/O 接口发出操作命令,I/O 接口提出 DMA 请求
- DMA 响应:DMA 控制器对 DMA 请求判别优先级以及屏蔽位,向总线裁决逻辑提出总线请求,当 CPU 执行完成当前的总线周期之后即可释放总线控制权。此时,总线裁决逻辑输出总线应答,表示 DMA 已经就绪,通过 DMA 控制器通知 I/O 接口开始 DMA 传输。
- DMA 传输:在 DMA 控制器的引导下,在存储器和外设之间进行数据传送,在传送过程中不需要 CPU 的参与
- DMA 结束:当完成既定操作之后,DMA 控制器释放总线控制权,并向 I/O 接口发出结束信号,当 I/O 接口收到结束信号之后,一方面停止 I/O 设备的工作,另一方面向 CPU 提出中断请求,使 CPU 从不介入状态解脱,并执行一段检查本次 DMA 传输操作正确性的代码。最后带着本次操作的结果以及状态继续执行原来的程序。
相比CPU,memory和外设的速度是非常慢的,因而在memory和memory(或者memory和设备)之间搬运数据,非常浪费CPU的时间,造成CPU无法及时处理一些实时事件。因此,设计专门用来搬运数据的器件(DMA控制器),协助CPU进行数据搬运。如下图所示:

-
DMA Controller, 提供DMA服务, 它是Provider。
-
外设能够利用DMA搬移数据。如MMC,当它接收到数据时, 会把数据存储在自己的寄存器中,既可以通过CPU循环读取寄存器来获取这些数据(此时占用CPU时间); 也可以利用DMA把寄存器的数据搬移到内存, 当搬移一定的数量后,通知CPU,然后CPU再从内存中一次性读取(DMA搬移过程中,CPU可以干别的事情)。此时外设使用DMA控制器提供的服务,它们是Consumer。
-
另外,DMA Controller 在搬移数据时,对于内存有一些要求, 例如它要求物理地址连续等。因此这里还涉及到DMA Buffer分配的问题。
1.2.DMA controller mode
- In bus master mode, the DMA controller acquires the system bus (address, data, and control lines) from the CPU to perform the DMA transfers. Because the CPU releases the system bus for the duration of the transfer, the process is sometimes referred to as cycle stealing.
- In bus slave mode, the DMA controller is accessed by the CPU, which programs the DMA controller’s internal registers to set up DMA transfers. The internal registers consist of source and destination address registers and transfer count registers for each DMA channel, as well as control and status registers for initiating, monitoring, and sustaining the operation of the DMA controller.
1.3.DMA 控制器与 CPU 怎样分时使用内存
外围设备可以通过 DMA 控制器直接访问内存,与此同时,CPU 可以继续执行程序逻辑,通常采用以下三种方法实现 DMA 控制机与 CPU 分时使用内存:
- 停止 CPU 访问内存;
- 周期挪用;
- DMA 与 CPU 交替访问内存。
1.3.1.停止 CPU 访问内存
当外围设备要求传送一批数据时,由 DMA 控制器发一个停止信号给 CPU,要求 CPU 放弃对地址总线、数据总线和有关控制总线的使用权,DMA 控制器获得总线控制权之后,开始进行数据传输,在一批数据传输完毕之后,DMA 控制器通知 CPU 可以继续使用内存,并把总线控制权交还给 CPU。图(a)就是这样的一个传输图,很显然,在这种 DMA 传输过程中,CPU 基本处于不工作状态或者保持状态。
- 优点:控制简单,是用于数据传输率很高的设备进行成组的传输。
- 缺点:在 DMA 控制器访问内存阶段,内存效能没有充分发挥,相当一部分的内存周期是空闲的,这是因为外围设备传送两个数据之间的间隔一般大于内存存储间隔,即使是再告诉的 I/O 存储设备也是如此(就是内存读写速率比 SSD 等都快)。

1.3.2.周期挪用
当 I/O 设备没有 DMA 请求时,CPU 按照程序要求访问内存;一旦 I/O 设备有 DMA 请求,则由 I/O 设备挪用一个或者几个内存周期,这种传送方式如下图所示:
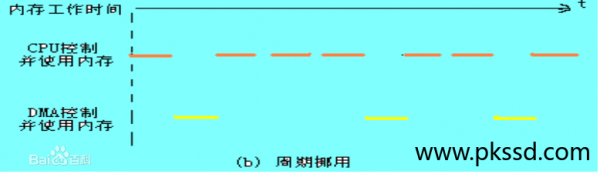
I/O 设备要求 DMA 传送时可能遇到两种情况:
第一种:此时 CPU 不需要访问内存,例如,CPU 正在执行乘法指令,由于乘法指令执行时间长,此时 I/O 访问与 CPU 访问之间没有冲突,则 I/O 设备挪用一两个内存周期是对 CPU 执行没有任何的影响。
第二种:I/O 设备要求访问内存时,CPU 也需要访问内存,这就产生了访问内存冲突,在这种情况下 I/O 设备优先访问,因为 I/O 访问有时间要求,前一个 I/O 数据必须在下一个访问请求来到之前存储完毕。显然,在这种情况下,I/O 设备挪用一两个内存周期,意味着 CPU 延缓了对指令的执行,或者更为明确的讲,在 CPU 执行访问指令的过程中插入了 DMA 请求。周期挪用内存的方式与停止 CPU 访问内存的方式对比,这种方式,既满足了 I/O 数据的传送,也发挥了 CPU 和内存的效率,是一种广泛采用的方法,但是 I/O 设备每一周期挪用都有申请总线控制权,建立总线控制权和归还总线控制权的过程,所以不适合传输小的数据。这种方式比较适用于 I/O 设备读写周期大于内存访问周期的情况。
1.3.3.DMA 和 CPU 交替访问内存
如果 CPU 的工作周期比内存的存储周期长很多,此时采用交替访问内存的方法可以使 DMA 传送和 CPU 同时发挥最高效率。这种传送方式的时间图如下:

此图是 DMA 和 CPU 交替访问内存的消息时间图,假设 CPU 的工作周期为 1.2us,内存的存储周期小于 0.6us,那么一个 CPU 周期可以分为 C1 和 C2 两个分周期,其中 C1 专供 DMA 控制器访问内存,C2 专供 CPU 访问内存。这种方式不需要总线使用权的申请、建立和归还的过程,总线的使用权是通过 C1 和 C2 分时机制决定的。CPU 和 DMA 控制器各自有自己的访问地址寄存器、数据寄存器和读写信号控制寄存器。在 C1 周期中,如果 DMA 控制器有访问请求,那么可以将地址和数据信号发送到总线上。在 C2 周期内,如果 CPU 有访问内存的请求,同样将请求的地址和数据信号发送到总线上。事实上,这是用 C1 C2 控制的一个多路转换器,这种总线控制权的转移几乎不需要什么时间,所以对于 DMA 来讲是很高效率的。
这种传送方式又称为“透明 DMA”方式,其由来是由于 DMA 传送对于 CPU 来讲是透明的,没有任何感觉。在透明 DMA 方式下 CPU 不需要停止主程序的运行,也不进入等待状态,是一种很高效率的工作方式,当然,相对应的硬件设计就会更加复杂。
以上是传统意义的 DMA:是一种完全由硬件执行 I/O 交换的工作方式。这种方式中,DMA 控制器和 CPU 完全接管对总线的控制,数据交换不经过 CPU,而直接在内存和 I/O 设备之间进行。DMA 工作时,由 DMA 控制器向内存发起地址和控制信号,进行地址修改,对传输的数据进行统计,并以中断的形式通知 CPU 数据传输完成。
1.4.DMA 导致的问题
DMA 不仅仅只会带来效率的提升,同样,它也会带来一些问题,最明显的就是缓存一致性问题。想象一下,现代的 CPU 都是自带一级缓存、二级缓存甚至是三级缓存,当 CPU 访问内存某个地址时,暂时先将新的值写入到缓存中,但是没有更新外部内存的数据,假设此时发生了 DMA 请求且操作的就是这一块在缓存中更新了而外部内存没有更新的内存地址,这样 DMA 读到的就是非最新数据;相同的,如果外部设备通过 DMA 将新值写入到内存中,但是 CPU 访问得到的确实缓存中的数据,这样也会导致拿到的不是最新的数据。


为了能够正确进行 DMA 操作,必须进行必要的 Cache 操作,Cache 的操作主要分为 invalidate(作废)和 writeback(回写),有时候也会二者一同使用。如果 DMA 使用了 Cache,那么 Cache 一致性问题是必须要考虑的,解决的最简单的办法就是禁止 DMA 目标地址范围的 Cache 功能,但是这样会牺牲掉一定的性能。因此,在 DMA 是否使用 cache 的问题上,可以根据 DMA 缓冲区的期望保留时间长短来决策。DMA 被区分为:一致性 DMA 映射和流式 DMA 映射。
-
一致性 DMA 映射:申请的缓存区会被以非缓存的形式映射,一致性映射具有很长的生命周期,在这段时间内占用映射寄存器,即使不再使用也不会释放,一般情况下,一致性 DMA 的生命周期会被设计为驱动的生命周期(也就是在 init 里面注册,在 exit 里面释放)。
-
流式 DMA 映射:实现比较复杂,表现特征为使用周期很短,它的实现中会主动保持缓存的一致性。在使用方法上,流式 DMA 还需要指定内核数据的流向,不然会导致不可预期的后果。不过很多的现代处理能能够自己来保证 CPU 和 DMA 控制器之间的 cache 一致性问题,比如 ARM 的 ACP 功能,这样像dma_map_single函数只是返回物理地址,而dma_unmap_single则什么都不做,这样极大的提升了系统性能。
1.4.1.流式 DMA映射 和一致性 DMA映射区别
一致性 DMA映射,采用的是系统预留的一段 DMA 内存用于 DMA 操作,这一段内核在系统启动阶段就已经预留完毕,比如 arm64 平台会在 dts 文件中写明系统预留的 DMA 内存段位于何处,并且会被标志为用于 dma 一致性内存申请,如果你有关注 DMA 的一致性映射操作 API 就会发现,一致性 DMA 不会去使用别的地方申请的内存,它都是通过dma_alloc_coherent自我申请内存,然后驱动自己填充数据,最后被提交给 DMA 控制器。
流式 DMA映射 ,它可以是随意的内存交给 DMA 进行处理,不需要从系统预留的 DMA 位置进行内存申请,任何普通的 kmalloc 申请的内存都能交给 DMA 控制器进行操作。
二者是如何做到缓存一致性的:
-
一致性 DMA ,在 DMA 内存申请的过程中,首先进行一个 ioremap_nocache 的映射,然后调用函数 dma_cache_wback_inv 保证缓存已经刷新到位之后,后面使用这一段内存时不存在一二级缓存;
-
流式 DMA ,不能直接禁止缓存,因为流式 DMA 可以使用系统中的任意地址范围的地址,CPU 总不能将系统所有的地址空间都禁止缓存,这不科学,那么为了实现缓存一致性,流式 DMA 需要不断的对缓存进行失效操作,告诉 CPU 这一段缓存是不可信的,必须从内存中重新获取。一致性 DMA 就是直接将缓存禁止,而流式 DMA 则是将缓存失效刷新。
2.内核DMA源码分析
2.1.struct device
888 struct device {
924 ...
925 const struct dma_map_ops *dma_ops;
926 u64 *dma_mask; /* dma mask (if dma'able device) */
927 u64 coherent_dma_mask;
932 unsigned long dma_pfn_offset;
933
934 struct device_dma_parameters *dma_parms;
936 struct list_head dma_pools; /* dma pools (if dma'ble) */
937
938 struct dma_coherent_mem *dma_mem; /* internal for coherent mem override */
940 #ifdef CONFIG_DMA_CMA
941 struct cma *cma_area; /* contiguous memory area for dma allocations */
943 #endif
- dma_mask:用于表示该设备的DMA的寻址能力;
- coherent_dma_mask:用于在一致性DMA映射时对内存地址的要求。
Note:
这两个域通过dma_set_mask() 和 dma_set_coherent_dma_mask()进行设置的。对于CPU来说,可以在设置struct dma_map_ops {}的时候, 设置set_dma_mask回调函数来限制DMA地址的请求范围。
2.2.DMA初始化
really_probe
->dma_configure(dev);
-> of_dma_configure
of_dma_configure:
136 if (!dev->coherent_dma_mask)
137 dev->coherent_dma_mask = DMA_BIT_MASK(32);
138 /*
139 * Set it to coherent_dma_mask by default if the architecture
140 * code has not set it.
141 */
142 if (!dev->dma_mask)
143 dev->dma_mask = &dev->coherent_dma_mask;
144
145 if (!size)
146 size = max(dev->coherent_dma_mask, dev->coherent_dma_mask + 1);
147
148 dev->dma_pfn_offset = offset;
169 arch_setup_dma_ops(dev, dma_addr, size, iommu, coherent);
如上所示:如果配置CONFIG_MMU,则调用arch_setup_dma_ops(dma-mapping.c)设置struct dma_map_ops。分三种情况设置。
- dev->dma_ops定义;
- iommu_coherent_ops 或者 iommu_ops;
- arm_coherent_dma_ops 或者 arm_dma_ops; (如果dts没有设置dma-coherent, 则调用 arm_dma_ops)
2.3.platform_device_register_full 注册platform_device时设置dma_mask:
504 struct platform_device *platform_device_register_full(
505 const struct platform_device_info *pdevinfo)
506 {
517 if (pdevinfo->dma_mask) {
518 /*
519 * This memory isn't freed when the device is put,
520 * I don't have a nice idea for that though. Conceptually
521 * dma_mask in struct device should not be a pointer.
522 * See http://thread.gmane.org/gmane.linux.kernel.pci/9081
523 */
524 pdev->dev.dma_mask =
525 kmalloc(sizeof(*pdev->dev.dma_mask), GFP_KERNEL);
526 if (!pdev->dev.dma_mask)
527 goto err;
528
529 *pdev->dev.dma_mask = pdevinfo->dma_mask;
530 pdev->dev.coherent_dma_mask = pdevinfo->dma_mask;
531 }
platform_device定义如下:
arch/arm/mach-pxa/devices.c:
767 struct platform_device pxa27x_device_ssp1 = {
768 .name = "pxa27x-ssp",
769 .id = 0,
770 .dev = {
771 .dma_mask = &pxa27x_ssp1_dma_mask,
772 .coherent_dma_mask = DMA_BIT_MASK(32),
773 },
774 .resource = pxa27x_resource_ssp1,
775 .num_resources = ARRAY_SIZE(pxa27x_resource_ssp1),
776 };
3.Basic conception
3.1.DMA channels
DMA channels are used by high speed devices and they allow them to communicate directly with the main memory (RAM) on our system. When DMA channels are used, CPU is not involved in the communication. Communication without the CPU is a benefit since CPU is busy with all sorts of different processing tasks. Sometimes we don’t want to wait the CPU, so we enable other devices on the system to access RAM directly. DMA channels can be used by sound cards, hard disk drives, CD/DVD-ROM drives, tape drives, etc.
一个DMA controller可以同时进行的DMA传输的个数是有限的,这称作DMA channels。它只是一个逻辑概念,因为鉴于总线访问的冲突, 以及内存一致性的考量, 这些Channels不可能真正的并行工作,而只能分时复用,DMA控制器充当仲裁角色。既然是分时复用,那么我们也可以基于某一个物理Channel,抽象出多个虚拟Channel,由软件负责仲裁,以决定在某一时刻由哪个虚拟Channel来使用物理Channel。
3.2.DMA request lines
DMA传输是由CPU发起的:CPU告诉DMA控制器,帮忙将xxx地方的数据搬到xxx地方。CPU发完指令之后,就去做其他事情了。而DMA控制器,除了负责怎么搬之外,还要决定何时开始数据搬运。
因为CPU发起DMA传输的时候,并不知道当前是否具备传输条件,例如source设备是否有数据、dest设备的FIFO是否空闲等等。只有设备知道什么时候开始传输,因此需要DMA传输的设备和DMA控制器之间,会有几条物理的连接线(即DMA request,DRQ),用于通知DMA控制器可以开始传输了。
DMA channel是Provider(提供传输服务),DMA request line是Consumer(消费传输服务)。在一个系统中DMA request line的数量通常比DMA channel的数量多,因为并不是每个request line在每一时刻都需要传输。
Dtsi:
#dma-requests = <75>;
#dma-channels = <32>;
3.3.传输参数
1).transfer size
A very simple DMA controller would only take into account a single parameter: the transfer size. At each clock cycle, it would transfer a byte of data from one buffer to another, until the transfer size has been reached.
That wouldn’t work well in the real world, since slave devices might require a specific number of bits to be transferred in a single cycle. For example, we may want to transfer as much data as the physical bus allows to maximize performances when doing a simple memory copy operation, but our audio device could have a narrower FIFO that requires data to be written exactly 16 or 24 bits at a time. This is why most if not all of the DMA controllers can adjust this, using a parameter called the transfer width.
The transfer size relates to the number of transfers to be performed, that is, for writes it refers to the Source Width transfers to perform when the DMA controller is the flow controller. For reads, transfer size refers to the number of transfers completed on the destination bus. If the DMA controller is NOT the flow controller then transfer size is not used. This means that writing to the DMACCx control register with the transfer size tells the DMA controller what source width transfers to be performed and reading from this register shows the number of destination width transfers have been completed.
Example 1:
32-bit Source / 8-bit Destination
Write TransferSize = 3 (words)
Then read TransferSize will increment from 0 to 12 (bytes) as the transfer progresses.
Example 2:
If SBSize (source burst size) = 0b111, 256 transfers,
SWidth = 0b010, 32-bit word and Destination is memory
Then the DMA controller will transfer 256 32-bit words from the source peripheral to memory when the source peripheral's DMACBREQ signal goes active.
在每一个时钟周期,DMA controller将1byte的数据从一个buffer搬到另一个buffer,直到搬完“transfer size”个bytes即可停止。
由于有些设备可能需要在一个时钟周期中,传输指定bit的数据,例如:
- memory之间传输数据,希望能以总线的最大宽度为单位(32-bit、64-bit等),以提升数据传输的效率;
- 在音频设备中,需要每次写入精确的16-bit或者24-bit的数据;
因此需要为DMA controller提供一个额外的参数transfer width。
内核宏定义如下:
enum dma_slave_buswidth {
DMA_SLAVE_BUSWIDTH_UNDEFINED = 0,
DMA_SLAVE_BUSWIDTH_1_BYTE = 1,
DMA_SLAVE_BUSWIDTH_2_BYTES = 2,
DMA_SLAVE_BUSWIDTH_3_BYTES = 3,
DMA_SLAVE_BUSWIDTH_4_BYTES = 4,
DMA_SLAVE_BUSWIDTH_8_BYTES = 8,
DMA_SLAVE_BUSWIDTH_16_BYTES = 16,
DMA_SLAVE_BUSWIDTH_32_BYTES = 32,
DMA_SLAVE_BUSWIDTH_64_BYTES = 64,
};
2).burst size
另外,当传输的源或者目的地是memory的时候,为了提高效率,DMA controller不愿意每一次传输都访问memory,而是在内部开一个buffer,将数据缓存在自己buffer中:
- memory是源时,一次从memory读出一批数据,保存在自己的buffer中,然后再一点点(以时钟为节拍),传输到目的地;
- memory是目的地时,先将源的数据传输到自己的buffer中,当累计一定量的数据之后,再一次性的写入memory。
这种场景下,DMA控制器内部可缓存的数据量的大小,称作burst size。
The burst size is the amount of data that is transferred when the DMACxBREQ signal goes active in the source/destination peripheral and is NOT related to the AHB HBURST signal (as this is often a source of confusion).
4).DMA transfer way
- block DMA方式
- Scatter-gather DMA方式
在DMA传输数据的过程中,要求源物理地址和目标物理地址必须是连续的。但是在某些计算机体系中,如IA架构,连续的存储器地址在物理上不一定是连续的,所以DMA传输要分成多次完成。
如果在传输完一块物理上连续的数据后引起一次中断,然后再由主机进行下一块物理上连续的数据传输,那么这种方式就为block DMA方式。
Scatter-gather DMA使用一个链表描述物理上不连续的存储空间,然后把链表首地址告诉DMA master。DMA master在传输完一块物理连续的数据后,不用发起中断,而是根据链表来传输下一块物理上连续的数据,直到传输完毕后再发起一次中断。
很显然,scatter-gather DMA方式比block DMA方式效率高。
When a block move operation occurs, traditional DMA controllers need a contiguous (nonsegmented) block of physical memory. On most systems, it is difficult to get nonsegmented memory returned from the operating system.
The MITE and NI-STC DMA controllers can take segmented memory and perform a move operation on this memory using “scatter-gather” DMA. In this method, the DMA controllers store the starting addresses of all the memory segments. After the move operation starts, the DMA controller automatically feeds the DMA controller the start address of the next segment after the previous segment of memory is completed. Using this method, you do not need a contiguous block of memory from the operating system. This makes DMA ideal for non deterministic operating systems.
refer to
- https://www.byteisland.com/dma-%E4%B8%8E-scatterlist-%E6%8A%80%E6%9C%AF%E7%AE%80%E4%BB%8B/















 3128
3128











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









