







文章目录
前言
本系列内容力求将nvdla的内核态驱动整理清楚,如果有分析不对的请指出。
前面已经分析了一大块代码了,链接分别如下:
系列文章1:NVDLA内核态驱动代码整理一
系列文章2:NVDLA内核态驱动代码整理二
系列文章3:NVDLA内核态驱动代码整理三
欢迎阅读硬件信号和架构分析系列文章1:NVDLA硬件信号和架构设计整理一
本章是分析nvdla_core_callbacks.c代码第二部分。
由于仍然需要用到前面三篇文章下的结构体,因此此处贴出:
| 结构体 | 功能 |
|---|---|
nvdla_gem_object | 包含重要的变量,首先是drm_gem_object,用于drm存储管理和分配的结构体;其次是*kvaddr:这是一个指针成员,通常用于存储内核虚拟地址。这个地址指向内核中的数据缓冲区,该缓冲区可能包含了与图形或DMA相关的数据。这个成员可能被用于快速访问数据,而无需进行物理内存地址转换;最后是和dma相关的地址和属性 |
nvdla_mem_handle | 作为媒介联通用户态空间任务结构体nvdla_ioctl_submit_task和内核态空间任务结构体nvdla_task |
nvdla_ioctl_submit_task | 用户态空间任务结构体 |
nvdla_task | 内核态空间任务结构体 |
nvdla_device | 包含的信息是设备常用信息,比如中断、平台设备、drm设备等 |
nvdla_submit_args | 该结构体包含任务信息,用于用户态空间传入任务相关数据的参数,并通过该参数和nvdla_ioctl_submit_task交互,总体来说,任务粒度高于nvdla_ioctl_submit_task |
drm_file | 包含针对该file的每个文件描述符操作后的状态变量 |
drm_gem_object | 描述drm的存储分配对象,包含了该对象归属的设备drm_device和对象的大小size |
drm_device | 描述了drm设备结构体,包含了该总线设备的数据结构 |
sg_table | Scatter-Gather表,用于描述分散在物理内存中的连续数据块的位置和大小 |
drm_ioctl_desc | 定义drm的ioctl操作,可以自行添加自定义ioctl操作,但需要注意ioctl的flags |
drm_ioctl_flags | ioctl的flags说明 |
drm_driver | 包含驱动的常见定义变量 |
nvdla_config | 实现NVDLA IP Core的内部配置,包括atom_size、bdma_enable、rubik_enable、weight_compress_support |
一、nvdla_core_callbacks.c代码解读二
1. dla_debug、dla_info、dla_warn和dla_error函数
继续读代码,dla_debug、dla_info、dla_warn和dla_error四个用于处理一般信息的函数,都采用了可变参数的方式来接受消息字符串和参数,通常是通过<stdarg.h>标准库中的宏来实现的。
void dla_debug(const char *str, ...)
{
va_list args;
va_start(args, str);
vprintk(pr_fmt(str), args);
va_end(args);
}
void dla_info(const char *str, ...)
{
va_list args;
va_start(args, str);
vprintk(str, args);
va_end(args);
}
void dla_warn(const char *str, ...)
{
va_list args;
va_start(args, str);
vprintk(str, args);
va_end(args);
}
void dla_error(const char *str, ...)
{
va_list args;
va_start(args, str);
vprintk(str, args);
va_end(args);
}
这边扩展一下va_***:
(1)va_list是C语言中的一个宏定义,用于表示一个变长参数列表。它是一个指向变长参数列表的指针,可以通过宏va_start、va_arg和va_end对变长参数列表进行访问和操作。在函数中需要接收不定数量的参数时,可以使用va_list来处理这些参数。
(2)va_start:是一个宏定义,用于在使用可变参数函数时获取可变参数的起始地址。它的作用是初始化一个va_list类型的变量,使其指向可变参数列表的第一个参数。va_start宏需要两个参数,分别是一个va_list类型的变量和可变参数的最后一个固定参数的地址。
(3)va_arg:是一个宏,用于获取可变参数列表中的下一个参数值;
(4)va_end:是一个宏,用于结束使用 va_start 和 va_arg 宏定义的可变参数列表。它的作用是清理 va_list 类型变量,以便该变量可以被再次使用。
以上参考自可变参数的介绍。
这里选择使用vprintk函数而不是printk函数的原因是后者不支持可变参数。
2. dla_memset和dla_memcpy函数
继续读代码,dla_memset和dla_memcpy函数分别用于将内存块的内容设置为指定的值、将一个内存块的内容复制到另一个内存块中。
void *dla_memset(void *src, int ch, uint64_t len)
{
return memset(src, ch, len);
}
void *dla_memcpy(void *dest, const void *src, uint64_t len)
{
return memcpy(dest, src, len);
}
memset通常用于将内存块的内容设置为指定的值。接受三个参数:src是要设置的内存块的起始地址,ch是要设置的值,len是要设置的内存块的长度(以字节为单位)。这个函数将调用标准库函数memset来执行实际的内存设置操作,并返回指向src的指针。
memcpy通常用于将一个内存块的内容复制到另一个内存块中。接受三个参数:dest是目标内存块的起始地址,src是源内存块的起始地址,len是要复制的字节数。这个函数将调用标准库函数 memcpy来执行实际的内存复制操作,并返回指向dest的指针。
3. dla_get_time_us函数
继续读代码,dla_get_time_us函数通过调用ktime_get_ns()函数来获取当前时间的纳秒级时间戳,然后将纳秒级时间戳除以NSEC_PER_USEC来将时间转换为微秒,并返回一个int64_t类型的整数表示微秒级的时间戳。
int64_t dla_get_time_us(void)
{
return ktime_get_ns() / NSEC_PER_USEC;
}
4. dla_reg_write和dla_reg_read函数
继续读代码,dla_reg_write和dla_reg_read函数分别用于写和读寄存器
void dla_reg_write(void *driver_context, uint32_t addr, uint32_t reg)
{
struct nvdla_device *nvdla_dev =
(struct nvdla_device *)driver_context;
if (!nvdla_dev)
return;
writel(reg, nvdla_dev->base + addr);
}
uint32_t dla_reg_read(void *driver_context, uint32_t addr)
{
struct nvdla_device *nvdla_dev =
(struct nvdla_device *)driver_context;
if (!nvdla_dev)
return 0;
return readl(nvdla_dev->base + addr);
}
把nvdla_device重新找回来看看结构体:
/**
* @brief NVDLA device
*
* irq Interrupt number associated with this device
* ref Reference count for device
* base IO mapped base address for device
* nvdla_lock Spinlock used for synchronization
* drm DRM device instance
* task Pointer to task in execution
* config_data Pointer to the configuration data
* pdev Pointer to NVDLA platform device
* event_notifier Completion object used to wait for events from HW
* engine_context Private data passed from engine in dla_engine_init
*/
struct nvdla_device {
int32_t irq;
struct kref ref;
void __iomem *base;
spinlock_t nvdla_lock;
struct drm_device *drm;
struct nvdla_task *task;
struct nvdla_config *config_data;
struct platform_device *pdev;
struct completion event_notifier;
void *engine_context;
};
driver_context驱动上下文的可以指向nvdla_device,换句话来说,也可以理解这两个变量名之间的关系,就是nvdla_device提供了计算、存储等资源,而driver是运行在device上的管理程序,也可以理解成进程或者更细粒度的线程,进程和线程的上下文就是任意一个时刻下的资源状态。因此使用driver_context来指向nvdla_device是合理的。那么此处nvdla_device提供了_iomem的base地址,通过writel和readl函数可以实现写入、读出寄存器的功能。
注意此处还有一个engine_context,按照注释表达的意思应该是子模块的私有数据。
1、driver_context:指的就是nvdla_device,因为nvdla_device提供了计算、存储等资源抽象,
而driver就是个进程或者线程;
2、engine_context:指的就是具体的某个子模块比如bdma、conv、pdp、sdp等的私有数据,特指某个模块的特定上下文数据。
其中关于writel和readl的具体实现建议阅读:linux内核中linux中readl()和writel()函数
5. nvdla_engine_isr函数
继续读代码,nvdla_engine_isr函数负责完成上自旋锁、完成硬件子单元乒乓寄存器组的初始化、执行计算任务、解除等待队列中的锁、释放自旋锁。
static irqreturn_t nvdla_engine_isr(int32_t irq, void *data)
{
unsigned long flags;
struct nvdla_device *nvdla_dev = (struct nvdla_device *)data;
if (!nvdla_dev)
return IRQ_NONE;
spin_lock_irqsave(&nvdla_dev->nvdla_lock, flags);
dla_isr_handler(nvdla_dev->engine_context);
complete(&nvdla_dev->event_notifier);
spin_unlock_irqrestore(&nvdla_dev->nvdla_lock, flags);
return IRQ_HANDLED;
}
有一点值得注意,就是这里的传入参数data指针被强制赋予nvdla_device的结构体指针,和读写寄存器的情况一样,因为中断无法脱离硬件而单独存在。接下来逐个介绍重要的变量和函数。
5.1 irqreturn_t变量
/**
* enum irqreturn
* @IRQ_NONE interrupt was not from this device or was not handled
* @IRQ_HANDLED interrupt was handled by this device
* @IRQ_WAKE_THREAD handler requests to wake the handler thread
*/
enum irqreturn {
IRQ_NONE = (0 << 0),
IRQ_HANDLED = (1 << 0),
IRQ_WAKE_THREAD = (1 << 1),
};
typedef enum irqreturn irqreturn_t;
我们根据return IRQ_HANDLED;可以确定该返回中断可以被nvdla_device这个设备handle。
5.2 spin_lock_irqsave和spin_unlock_irqrestore函数(从内联汇编解释锁)
这俩适合放在一起,可以先看看内核提供的参考书是怎么说的:
The most basic primitive for locking is spinlock.
static DEFINE_SPINLOCK(xxx_lock);
unsigned long flags;
spin_lock_irqsave(&xxx_lock, flags);
... critical section here ..
spin_unlock_irqrestore(&xxx_lock, flags);
The above is always safe. It will disable interrupts _locally_, but the
spinlock itself will guarantee the global lock, so it will guarantee that
there is only one thread-of-control within the region(s) protected by that
lock. This works well even under UP also, so the code does _not_ need to
worry about UP vs SMP issues: the spinlocks work correctly under both.
自旋锁无疑是最基本的锁机制,怎么使用上述代码块中已给出示例。
逐个往前追溯spin_lock_irqsave和spin_unlock_irqrestore:
#define spin_lock_irqsave(lock, flags) \
do { \
raw_spin_lock_irqsave(spinlock_check(lock), flags); \
} while (0)
||
||
\/
#define raw_spin_lock_irqsave(lock, flags) \
do { \
typecheck(unsigned long, flags); \
_raw_spin_lock_irqsave(lock, flags); \
} while (0)
||
||
\/
#define _raw_spin_lock_irqsave(lock, flags) __LOCK_IRQSAVE(lock, flags)
||
||
\/
#define __LOCK_IRQSAVE(lock, flags) \
do { local_irq_save(flags); __LOCK(lock); } while (0)
||
||
\/
#define local_irq_save(flags) \
do { \
raw_local_irq_save(flags); \
trace_hardirqs_off(); \
} while (0)
||
||
\/
#define raw_local_irq_save(flags) \
do { \
typecheck(unsigned long, flags); \
flags = arch_local_irq_save(); \
} while (0)
||
||
\/
/*
* Save IRQ state and disable IRQs
*/
static inline long arch_local_irq_save(void)
{
unsigned long flags;
__asm__ __volatile__(" clri %0 \n" : "=r" (flags) : : "memory");
return flags;
}
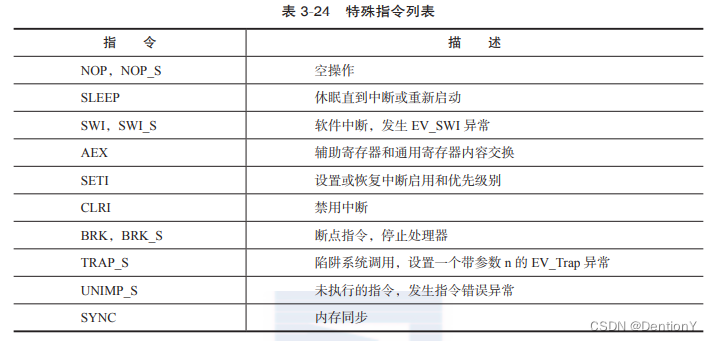
根据内联汇编的格式__asm__ __volatile__("Instruction List" : Output : Input : Clobber/Modify);很容易判断__asm__ __volatile__(" clri %0 \n" : "=r" (flags) : : "memory")是在读取CLRI指令的值并赋予flags变量,CLRI是什么?其实就是Clear Interrupt,禁用中断的特殊指令。
简单来说,就是现在NVDLA需要执行任务,那么首先需要使用nvdla_device的专属锁&nvdla_dev->nvdla_lock对critical region上锁,与此同时,上锁这件事情得通告其余进程不要来打断,所以需要clri指令配合,禁止中断。
贴一张图片:

接下来是spin_unlock_irqrestore函数,追溯情况如下:
static __always_inline void spin_unlock_irqrestore(spinlock_t *lock, unsigned long flags)
{
raw_spin_unlock_irqrestore(&lock->rlock, flags);
}
||
||
\/
#define raw_spin_unlock_irqrestore(lock, flags) \
do { \
typecheck(unsigned long, flags); \
_raw_spin_unlock_irqrestore(lock, flags); \
} while (0)
||
||
\/
#define _raw_spin_unlock_irqrestore(lock, flags) \
__UNLOCK_IRQRESTORE(lock, flags)
||
||
\/
#define __UNLOCK_IRQRESTORE(lock, flags) \
do { local_irq_restore(flags); __UNLOCK(lock); } while (0)
||
||
\/
#define local_irq_restore(flags) do { raw_local_irq_restore(flags); } while (0)
||
||
\/
#define raw_local_irq_restore(flags) \
do { \
typecheck(unsigned long, flags); \
arch_local_irq_restore(flags); \
} while (0)
||
||
\/
/*
* restore saved IRQ state
*/
static inline void arch_local_irq_restore(unsigned long flags)
{
__asm__ __volatile__(" seti %0 \n" : : "r" (flags) : "memory");
}
最后是__asm__ __volatile__(" seti %0 \n" : : "r" (flags) : "memory");与seti指令相关,用于设置或者恢复中断启用和优先级。
简单来说,就是现在NVDLA任务执行完成,那么首先需要使用nvdla_device的专属锁&nvdla_dev->nvdla_lock对critical region临界区释放锁,与此同时,释放锁这件事情也就意味着临界区可以允许其余进程来使用相关资源,所以需要seti指令配合,恢复中断启用和优先级。
5.3 dla_isr_handler函数
该函数定义在engine_isr.c中(太开心了,这个.c文件只有这一个函数),dla_isr_handler(nvdla_dev->engine_context);这一行代码调用了dla_isr_handler函数,该函数用于处理与NVDLA引擎相关的中断事件。它接受nvdla_dev->engine_context作为参数,该参数通常包含了与引擎相关的上下文信息,以便进行特定的处理。代码定义如下:
int32_t dla_isr_handler(void *engine_data)
{
uint32_t mask;
uint32_t reg;
struct dla_processor *processor = NULL;
struct dla_processor_group *group;
struct dla_engine *engine = (struct dla_engine *)engine_data;
mask = glb_reg_read(S_INTR_MASK);
reg = glb_reg_read(S_INTR_STATUS);
dla_trace("Enter: dla_isr_handler, reg:%x, mask:%x\n", reg, mask);
if (reg & MASK(GLB_S_INTR_STATUS_0, CACC_DONE_STATUS0)) {
processor = &engine->processors[DLA_OP_CONV];
group = &processor->groups[0];
group->events |= (1 << DLA_EVENT_OP_COMPLETED);
}
if (reg & MASK(GLB_S_INTR_STATUS_0, CACC_DONE_STATUS1)) {
processor = &engine->processors[DLA_OP_CONV];
group = &processor->groups[1];
group->events |= (1 << DLA_EVENT_OP_COMPLETED);
}
if (reg & MASK(GLB_S_INTR_STATUS_0, SDP_DONE_STATUS0)) {
processor = &engine->processors[DLA_OP_SDP];
group = &processor->groups[0];
group->events |= (1 << DLA_EVENT_OP_COMPLETED);
}
if (reg & MASK(GLB_S_INTR_STATUS_0, SDP_DONE_STATUS1)) {
processor = &engine->processors[DLA_OP_SDP];
group = &processor->groups[1];
group->events |= (1 << DLA_EVENT_OP_COMPLETED);
}
if (reg & MASK(GLB_S_INTR_STATUS_0, CDP_DONE_STATUS0)) {
processor = &engine->processors[DLA_OP_CDP];
group = &processor->groups[0];
group->events |= (1 << DLA_EVENT_OP_COMPLETED);
}
if (reg & MASK(GLB_S_INTR_STATUS_0, CDP_DONE_STATUS1)) {
processor = &engine->processors[DLA_OP_CDP];
group = &processor->groups[1];
group->events |= (1 << DLA_EVENT_OP_COMPLETED);
}
if (reg & MASK(GLB_S_INTR_STATUS_0, RUBIK_DONE_STATUS0)) {
processor = &engine->processors[DLA_OP_RUBIK];
group = &processor->groups[0];
group->events |= (1 << DLA_EVENT_OP_COMPLETED);
}
if (reg & MASK(GLB_S_INTR_STATUS_0, RUBIK_DONE_STATUS1)) {
processor = &engine->processors[DLA_OP_RUBIK];
group = &processor->groups[1];
group->events |= (1 << DLA_EVENT_OP_COMPLETED);
}
if (reg & MASK(GLB_S_INTR_STATUS_0, PDP_DONE_STATUS0)) {
processor = &engine->processors[DLA_OP_PDP];
group = &processor->groups[0];
group->events |= (1 << DLA_EVENT_OP_COMPLETED);
}
if (reg & MASK(GLB_S_INTR_STATUS_0, PDP_DONE_STATUS1)) {
processor = &engine->processors[DLA_OP_PDP];
group = &processor->groups[1];
group->events |= (1 << DLA_EVENT_OP_COMPLETED);
}
if (reg & MASK(GLB_S_INTR_STATUS_0, BDMA_DONE_STATUS0)) {
processor = &engine->processors[DLA_OP_BDMA];
group = &processor->groups[0];
group->events |= (1 << DLA_EVENT_OP_COMPLETED);
}
if (reg & MASK(GLB_S_INTR_STATUS_0, BDMA_DONE_STATUS1)) {
processor = &engine->processors[DLA_OP_BDMA];
group = &processor->groups[1];
group->events |= (1 << DLA_EVENT_OP_COMPLETED);
}
if (reg & MASK(GLB_S_INTR_STATUS_0, CDMA_DAT_DONE_STATUS0)) {
processor = &engine->processors[DLA_OP_CONV];
group = &processor->groups[0];
group->events |= (1 << DLA_EVENT_CDMA_DT_DONE);
}
if (reg & MASK(GLB_S_INTR_STATUS_0, CDMA_DAT_DONE_STATUS1)) {
processor = &engine->processors[DLA_OP_CONV];
group = &processor->groups[1];
group->events |= (1 << DLA_EVENT_CDMA_DT_DONE);
}
if (reg & MASK(GLB_S_INTR_STATUS_0, CDMA_WT_DONE_STATUS0)) {
processor = &engine->processors[DLA_OP_CONV];
group = &processor->groups[0];
group->events |= (1 << DLA_EVENT_CDMA_WT_DONE);
}
if (reg & MASK(GLB_S_INTR_STATUS_0, CDMA_WT_DONE_STATUS1)) {
processor = &engine->processors[DLA_OP_CONV];
group = &processor->groups[1];
group->events |= (1 << DLA_EVENT_CDMA_WT_DONE);
}
glb_reg_write(S_INTR_STATUS, reg);
mask = glb_reg_read(S_INTR_MASK);
reg = glb_reg_read(S_INTR_STATUS);
dla_trace("Exit: dla_isr_handler, reg:%x, mask:%x\n", reg, mask);
RETURN(0);
}
这里需要对相关结构体和函数进行展开:
5.3.1 dla_processor结构体
struct dla_processor {
const char *name;
uint8_t op_type;
uint8_t consumer_ptr;
uint8_t roi_index;
uint8_t group_status;
uint8_t rdma_status;
uint8_t last_group;
struct dla_common_op_desc *tail_op;
struct dla_processor_group groups[DLA_NUM_GROUPS];
union dla_stat_container *stat_data_desc;
int32_t (*is_ready)(struct dla_processor *processor,
struct dla_processor_group *group);
int32_t (*enable)(struct dla_processor_group *group);
int32_t (*program)(struct dla_processor_group *group);
void (*set_producer)(int32_t group_id, int32_t rdma_id);
void (*dump_config)(struct dla_processor_group *group);
void (*rdma_check)(struct dla_processor_group *group);
void (*get_stat_data)(struct dla_processor *processor,
struct dla_processor_group *group);
void (*dump_stat)(struct dla_processor *processor);
};
dla_processor结构体是dla_processor_group和dla_engine的桥梁。
5.3.2 dla_processor_group结构体
struct dla_processor_group {
uint8_t id;
uint8_t rdma_id;
uint8_t active;
uint8_t events;
uint8_t roi_index;
uint8_t is_rdma_needed;
uint8_t pending;
int32_t lut_index;
uint8_t programming;
uint64_t start_time;
struct dla_common_op_desc *op_desc;
struct dla_common_op_desc *consumers[DLA_OP_NUM];
struct dla_common_op_desc *fused_parent;
union dla_operation_container *operation_desc;
union dla_surface_container *surface_desc;
};
dla_processor_group结构体最重要的是作为乒乓寄存器组而存在,完成设备启动的初始配置,比如id和active,注意根据NVDLA硬件信号和架构设计整理一关于乒乓寄存器组的描述会帮助理解这个结构体的设计思路。另外该结构体也包含了dla_operation_container和dla_surface_container的union,专门用于指向特定的硬件计算子模块比如bdma、conv、sdp等的操作类型和image surface。关于dla_common_op_desc结构体如下:
struct dla_common_op_desc {
int16_t index; /* set by ucode */
int8_t roi_index;
uint8_t op_type;
uint8_t dependency_count;
uint8_t reserved0[3];
struct dla_consumer consumers[DLA_OP_NUM];
struct dla_consumer fused_parent;
} __packed __aligned(4);
5.3.3 dla_engine结构体
struct dla_engine {
struct dla_task *task;
struct dla_config *config_data;
struct dla_network_desc *network;
struct dla_processor processors[DLA_OP_NUM];
uint16_t num_proc_hwl;
int32_t status;
uint32_t stat_enable;
void *driver_context;
};
dla_engine结构体的作用只有一个,那就是串东西,把用于设置乒乓寄存器组配置寄存器、producer和consumer_ptr的dla_processor,设置mac阵列大小、是否使能rubik、bdma与weight_compress的dla_config,dla_task和dla_network_desc给串起来,可以说是一家之主了。当然了,还有一个最重要的*driver_context,这个要把nvdla_device给映射起来,以便于访问nvdla设备的硬件资源抽象从而支持读取和写入寄存器、获取专属锁来申请访问临界区。
这里的dla_network_desc、dla_task结构体如下,dla_network_desc囊括了运行网络的全部信息,我们可以很明显注意到几个信息,operation_desc_index、surface_desc_index和dependency_graph_index,分别是操作、image surface和依赖图(也就是常见元操作)的索引:
/**
* Network descriptor
*
* Contains all information to execute a network
*
* @op_head: Index of first operation of each type in operations list
* @num_rois: Number of ROIs
* @num_operations: Number of operations in one list
* @num_luts: Number of LUTs
*/
struct dla_network_desc {
int16_t operation_desc_index;
int16_t surface_desc_index;
int16_t dependency_graph_index;
int16_t lut_data_index;
int16_t roi_array_index;
int16_t surface_index;
int16_t stat_list_index;
int16_t reserved1;
int16_t op_head[DLA_OP_NUM];
uint16_t num_rois;
uint16_t num_operations;
uint16_t num_luts;
uint16_t num_addresses;
int16_t input_layer;
uint8_t dynamic_roi;
uint8_t reserved0;
} __packed __aligned(4);
dla_task结构体如下:
// # dla_task结构体
struct dla_task {
/* platform specific data to communicate with portability layer */
void *task_data;
/* task state */
uint32_t state;
/* Task base address */
uint64_t base;
/* start address of a list of dla_operation_container */
uint64_t operation_desc_addr;
/* start address of a list of dla_surface_container */
uint64_t surface_desc_addr;
/* start address of a list of dla_common_op_desc */
uint64_t dependency_graph_addr;
/* start address of a list of dla_lut_param */
uint64_t lut_data_addr;
/*
* start address of a list of dla_roi_desc,
* the first one is dla_roi_array_desc
* valid when network.dynamic_roi is true
*/
uint64_t roi_array_addr;
/* start address of a list of dla_surface_container */
uint64_t surface_addr;
/* start address of a list of dla_stat_container */
uint64_t stat_data_addr;
} __packed __aligned(256);
关于dla_engine进一步的定义如下:
static struct dla_engine engine = {
.processors[DLA_OP_BDMA] = {
.name = "BDMA",
.op_type = DLA_OP_BDMA,
.program = dla_bdma_program,
.enable = dla_bdma_enable,
.set_producer = dla_bdma_set_producer,
.is_ready = dla_bdma_is_ready,
.dump_config = dla_bdma_dump_config,
.rdma_check = dla_bdma_rdma_check,
.get_stat_data = dla_bdma_stat_data,
.dump_stat = dla_bdma_dump_stat,
.consumer_ptr = 0,
.roi_index = 0,
.group_status = 0,
.rdma_status = 0,
.last_group = 1,
.groups[0] = {
.id = 0,
.rdma_id = 0,
.active = 0,
.events = 0,
.roi_index = 0,
.is_rdma_needed = 0,
.lut_index = -1,
.operation_desc = &operation_desc[DLA_OP_BDMA][0],
.surface_desc = &surface_desc[DLA_OP_BDMA][0],
},
.groups[1] = {
.id = 1,
.rdma_id = 0,
.active = 0,
.events = 0,
.roi_index = 0,
.is_rdma_needed = 0,
.lut_index = -1,
.operation_desc = &operation_desc[DLA_OP_BDMA][1],
.surface_desc = &surface_desc[DLA_OP_BDMA][1],
},
},
.processors[DLA_OP_CONV] = {
.name = "Convolution",
.op_type = DLA_OP_CONV,
.program = dla_conv_program,
.enable = dla_conv_enable,
.set_producer = dla_conv_set_producer,
.is_ready = dla_conv_is_ready,
.dump_config = dla_conv_dump_config,
.rdma_check = dla_conv_rdma_check,
.get_stat_data = dla_conv_stat_data,
.dump_stat = dla_conv_dump_stat,
.consumer_ptr = 0,
.roi_index = 0,
.group_status = 0,
.rdma_status = 0,
.last_group = 1,
.groups[0] = {
.id = 0,
.rdma_id = 0,
.active = 0,
.events = 0,
.roi_index = 0,
.is_rdma_needed = 0,
.lut_index = -1,
.operation_desc = &operation_desc[DLA_OP_CONV][0],
.surface_desc = &surface_desc[DLA_OP_CONV][0],
},
.groups[1] = {
.id = 1,
.rdma_id = 0,
.active = 0,
.events = 0,
.roi_index = 0,
.is_rdma_needed = 0,
.lut_index = -1,
.operation_desc = &operation_desc[DLA_OP_CONV][1],
.surface_desc = &surface_desc[DLA_OP_CONV][1],
},
},
.processors[DLA_OP_SDP] = {
.name = "SDP",
.op_type = DLA_OP_SDP,
.program = dla_sdp_program,
.enable = dla_sdp_enable,
.set_producer = dla_sdp_set_producer,
.is_ready = dla_sdp_is_ready,
.dump_config = dla_sdp_dump_config,
.rdma_check = dla_sdp_rdma_check,
.get_stat_data = dla_sdp_stat_data,
.dump_stat = dla_sdp_dump_stat,
.consumer_ptr = 0,
.roi_index = 0,
.group_status = 0,
.rdma_status = 0,
.last_group = 1,
.groups[0] = {
.id = 0,
.rdma_id = 0,
.active = 0,
.events = 0,
.roi_index = 0,
.is_rdma_needed = 0,
.lut_index = -1,
.operation_desc = &operation_desc[DLA_OP_SDP][0],
.surface_desc = &surface_desc[DLA_OP_SDP][0],
},
.groups[1] = {
.id = 1,
.rdma_id = 0,
.active = 0,
.events = 0,
.roi_index = 0,
.is_rdma_needed = 0,
.lut_index = -1,
.operation_desc = &operation_desc[DLA_OP_SDP][1],
.surface_desc = &surface_desc[DLA_OP_SDP][1],
},
},
.processors[DLA_OP_PDP] = {
.name = "PDP",
.op_type = DLA_OP_PDP,
.program = dla_pdp_program,
.enable = dla_pdp_enable,
.set_producer = dla_pdp_set_producer,
.is_ready = dla_pdp_is_ready,
.dump_config = dla_pdp_dump_config,
.rdma_check = dla_pdp_rdma_check,
.get_stat_data = dla_pdp_stat_data,
.dump_stat = dla_pdp_dump_stat,
.consumer_ptr = 0,
.roi_index = 0,
.group_status = 0,
.rdma_status = 0,
.last_group = 1,
.groups[0] = {
.id = 0,
.rdma_id = 0,
.active = 0,
.events = 0,
.roi_index = 0,
.is_rdma_needed = 0,
.lut_index = -1,
.operation_desc = &operation_desc[DLA_OP_PDP][0],
.surface_desc = &surface_desc[DLA_OP_PDP][0],
},
.groups[1] = {
.id = 1,
.rdma_id = 0,
.active = 0,
.events = 0,
.roi_index = 0,
.is_rdma_needed = 0,
.lut_index = -1,
.operation_desc = &operation_desc[DLA_OP_PDP][1],
.surface_desc = &surface_desc[DLA_OP_PDP][1],
},
},
.processors[DLA_OP_CDP] = {
.name = "CDP",
.op_type = DLA_OP_CDP,
.program = dla_cdp_program,
.enable = dla_cdp_enable,
.set_producer = dla_cdp_set_producer,
.is_ready = dla_cdp_is_ready,
.dump_config = dla_cdp_dump_config,
.rdma_check = dla_cdp_rdma_check,
.get_stat_data = dla_cdp_stat_data,
.dump_stat = dla_cdp_dump_stat,
.consumer_ptr = 0,
.roi_index = 0,
.group_status = 0,
.rdma_status = 0,
.last_group = 1,
.groups[0] = {
.id = 0,
.rdma_id = 0,
.active = 0,
.events = 0,
.roi_index = 0,
.is_rdma_needed = 0,
.lut_index = -1,
.operation_desc = &operation_desc[DLA_OP_CDP][0],
.surface_desc = &surface_desc[DLA_OP_CDP][0],
},
.groups[1] = {
.id = 1,
.rdma_id = 0,
.active = 0,
.events = 0,
.roi_index = 0,
.is_rdma_needed = 0,
.lut_index = -1,
.operation_desc = &operation_desc[DLA_OP_CDP][1],
.surface_desc = &surface_desc[DLA_OP_CDP][1],
},
},
.processors[DLA_OP_RUBIK] = {
.name = "RUBIK",
.op_type = DLA_OP_RUBIK,
.program = dla_rubik_program,
.enable = dla_rubik_enable,
.set_producer = dla_rubik_set_producer,
.is_ready = dla_rubik_is_ready,
.dump_config = dla_rubik_dump_config,
.rdma_check = dla_rubik_rdma_check,
.get_stat_data = dla_rubik_stat_data,
.dump_stat = dla_rubik_dump_stat,
.consumer_ptr = 0,
.roi_index = 0,
.group_status = 0,
.rdma_status = 0,
.last_group = 1,
.groups[0] = {
.id = 0,
.rdma_id = 0,
.active = 0,
.events = 0,
.roi_index = 0,
.is_rdma_needed = 0,
.lut_index = -1,
.operation_desc = &operation_desc[DLA_OP_RUBIK][0],
.surface_desc = &surface_desc[DLA_OP_RUBIK][0],
},
.groups[1] = {
.id = 1,
.rdma_id = 0,
.active = 0,
.events = 0,
.roi_index = 0,
.is_rdma_needed = 0,
.lut_index = -1,
.operation_desc = &operation_desc[DLA_OP_RUBIK][1],
.surface_desc = &surface_desc[DLA_OP_RUBIK][1],
},
},
};
我们随便拿一块出来看:
.processors[DLA_OP_BDMA] = {
.name = "BDMA",
.op_type = DLA_OP_BDMA,
.program = dla_bdma_program,
.enable = dla_bdma_enable,
.set_producer = dla_bdma_set_producer,
.is_ready = dla_bdma_is_ready,
.dump_config = dla_bdma_dump_config,
.rdma_check = dla_bdma_rdma_check,
.get_stat_data = dla_bdma_stat_data,
.dump_stat = dla_bdma_dump_stat,
.consumer_ptr = 0,
.roi_index = 0,
.group_status = 0,
.rdma_status = 0,
.last_group = 1,
.groups[0] = {
.id = 0,
.rdma_id = 0,
.active = 0,
.events = 0,
.roi_index = 0,
.is_rdma_needed = 0,
.lut_index = -1,
.operation_desc = &operation_desc[DLA_OP_BDMA][0],
.surface_desc = &surface_desc[DLA_OP_BDMA][0],
},
.groups[1] = {
.id = 1,
.rdma_id = 0,
.active = 0,
.events = 0,
.roi_index = 0,
.is_rdma_needed = 0,
.lut_index = -1,
.operation_desc = &operation_desc[DLA_OP_BDMA][1],
.surface_desc = &surface_desc[DLA_OP_BDMA][1],
},
},
这一块是完成了struct dla_processor processors[DLA_OP_NUM];的赋值,如果读过这篇博客NVDLA硬件信号和架构设计整理一,我们可以很直观地意识到这段赋值是在初始化配置乒乓寄存器组,也就是groups1和groups2。另外有几个感兴趣的变量,set_producer和consumer_ptr,我把NVDLA硬件信号和架构设计整理一总结好的话搬出来:
Producer Register是为了决定哪个Ping-Pong Register Groups被CSB接口访问,Consumer
Register是为了指明数据通路是由哪个寄存器组决定的。CONSUMER指针是一个只读寄存器,CPU可以检查该
寄存器以确定数据路径选择了哪个乒乓组,而PRODUSER指针完全由CPU控制,并且在对硬件层编程之前应该
设置使用哪一个寄存器组。
然后再接着看id为0的寄存器组的操作类型operation_desc和输入数据surface_desc(关于surface的解释见NVDLA硬件信号和架构设计整理一):
.operation_desc = &operation_desc[DLA_OP_BDMA][0],
.surface_desc = &surface_desc[DLA_OP_BDMA][0],
往前追溯一下:
static union dla_operation_container operation_desc[DLA_OP_NUM][DLA_NUM_GROUPS];
static union dla_surface_container surface_desc[DLA_OP_NUM][DLA_NUM_GROUPS];
// # 来源engine_data.c
||
||
\/
相关宏的定义: // # 来源dla_interface.h
/**
* @ingroup Processors
* @name DLA Processors
* Processor modules in DLA engine. Each processor has it's
* own operation a.k.a. HW layer. Network is formed using
* graph of these operations
* @{
*/
#define DLA_OP_BDMA 0
#define DLA_OP_CONV 1
#define DLA_OP_SDP 2
#define DLA_OP_PDP 3
#define DLA_OP_CDP 4
#define DLA_OP_RUBIK 5
/** @} */
/**
* @ingroup Processors
* @name Maximum number of processors
* @brief DLA ash 6 processors
* @{
*/
#define DLA_OP_NUM 6
/** @} */
/**
* @ingroup Processors
* @name Number of groups
* @brief Each processor has 2 groups of registers
* @{
*/
#define DLA_NUM_GROUPS 2
||
||
\/
相关union的定义: // # 来源dla_interface.h
union dla_surface_container {
struct dla_bdma_surface_desc bdma_surface;
struct dla_conv_surface_desc conv_surface;
struct dla_sdp_surface_desc sdp_surface;
struct dla_pdp_surface_desc pdp_surface;
struct dla_cdp_surface_desc cdp_surface;
struct dla_rubik_surface_desc rubik_surface;
};
union dla_operation_container {
struct dla_bdma_op_desc bdma_op;
struct dla_conv_op_desc conv_op;
struct dla_sdp_op_desc sdp_op;
struct dla_pdp_op_desc pdp_op;
struct dla_cdp_op_desc cdp_op;
struct dla_rubik_op_desc rubik_op;
};
||
||
\/
我们挑bdma相关的操作结构体和surface结构体看: // # 来源 dla_interface.h
/**
* @ingroup BDMA
* @name Maximum BDMA transfers
* @brief BDMA supports multiple transfers in operation. This indicates
* maximum number of transfers possible in one operation.
* @{
*/
#define NUM_MAX_BDMA_OPS 20
/** @} */
struct dla_bdma_transfer_desc {
int16_t source_address;
int16_t destination_address;
uint32_t line_size;
uint32_t line_repeat;
uint32_t source_line;
uint32_t destination_line;
uint32_t surface_repeat;
uint32_t source_surface;
uint32_t destination_surface;
} __packed __aligned(4);
struct dla_bdma_surface_desc {
uint8_t source_type;
uint8_t destination_type;
uint16_t num_transfers;
struct dla_bdma_transfer_desc transfers[NUM_MAX_BDMA_OPS];
} __packed __aligned(4);
struct dla_bdma_op_desc {
uint16_t num_transfers;
uint16_t reserved0;
} __packed __aligned(4);
struct dla_bdma_stat_desc {
uint32_t read_stall;
uint32_t write_stall;
uint32_t runtime;
} __packed __aligned(4);
关于Groups的定义验证了硬件的说法。先看dla_bdma_stat_desc结构体,这个结构体是为了看bdma的状态,有三种状态:read-stall、write_stall和runtime。再看bdma的surface描述,需要确定source_type和destination_type,以及数据传输的num_transfers,还需要颇为详细的传输细节,相关变量在dla_bdma_transfer_desc结构体中定义。然后看看bdma的op描述,dma的作用就是传输数据,因此num_transfers成为关键的指标。我们也可以拿经典的conv来看看op描述,如下:
struct dla_data_cube {
uint16_t type; /* dla_mem_type */
int16_t address; /* offset to the actual IOVA in task.address_list */
uint32_t offset; /* offset within address */
uint32_t size;
/* cube dimensions */
uint16_t width;
uint16_t height;
uint16_t channel;
uint16_t reserved0;
/* stride information */
uint32_t line_stride;
uint32_t surf_stride;
/* For Rubik only */
uint32_t plane_stride;
} __packed __aligned(4);
#define PIXEL_OVERRIDE_UINT 0
#define PIXEL_OVERRIDE_INT 1
struct dla_conv_surface_desc {
/* Data cube */
struct dla_data_cube weight_data;
struct dla_data_cube wmb_data;
struct dla_data_cube wgs_data;
struct dla_data_cube src_data;
struct dla_data_cube dst_data;
/**
* u_addr = input_data.source_addr + offset_u
* this field should be set when YUV is not interleave format
*
*/
int64_t offset_u;
/* line stride for 2nd plane, must be 32bytes aligned */
uint32_t in_line_uv_stride;
} __packed __aligned(4);
struct dla_conv_op_desc {
/* Performance parameters */
/* dla_conv_mode */
uint8_t conv_mode;
uint8_t data_reuse;
uint8_t weight_reuse;
uint8_t skip_data_rls;
uint8_t skip_weight_rls;
uint8_t reserved0;
uint16_t entry_per_slice;
/* dla_data_format */
uint8_t data_format;
/* dla_pixel_mapping */
uint8_t pixel_mapping;
/* number of free slices before fetch */
uint16_t fetch_grain;
uint8_t reserved_b[8];
/* batch_num */
uint8_t batch;
/* dla_weight_format */
uint8_t weight_format;
uint8_t data_bank;
uint8_t weight_bank;
/* the offset in bytes of each data cube in a batch */
uint32_t batch_stride;
uint8_t post_extension;
uint8_t pixel_override;
/* number of slices need to be released */
uint16_t release;
/* The input cube dimension for CSC */
uint16_t input_width_csc;
uint16_t input_height_csc;
uint16_t input_channel_csc;
uint16_t kernel_width_csc;
uint16_t kernel_height_csc;
uint16_t kernel_channel_csc;
/* The input cube dimension for CMAC */
uint16_t input_width_cmac;
uint16_t input_height_cmac;
/* actual size in bytes */
uint32_t bytes_per_kernel;
/* Algorithm parameters */
int16_t mean_ry; /* mean value for red in RGB or Y in YUV */
int16_t mean_gu; /* mean value for green in RGB or U in YUV */
int16_t mean_bv; /* mean value for blue in RGB or V in YUV */
int16_t mean_ax;
uint8_t mean_format; /* dla_mean_format */
uint8_t conv_stride_x;
uint8_t conv_stride_y;
uint8_t pad_x_left;
uint8_t pad_x_right;
uint8_t pad_y_top;
uint8_t pad_y_bottom;
uint8_t dilation_x;
uint8_t dilation_y;
uint8_t reserved2[2];
/* Precision parameters */
uint8_t pra_truncate;
uint8_t in_precision;
/* The output precision from CONV, it's the MAC processing precison */
uint8_t out_precision;
int16_t pad_val;
/* input converter parameters */
struct dla_cvt_param in_cvt;
/* output converter parameters, support truncate only */
struct dla_cvt_param out_cvt;
} __packed __aligned(4);
有CNN基础的大概能看明白这里的结构体在描述什么,略去不提。
5.3.4 glb_reg_read和glb_reg_write函数
具体的使用场景是
dla_isr_handler(nvdla_dev->engine_context);
||
\/
glb_reg_write(S_INTR_STATUS, reg);
mask = glb_reg_read(S_INTR_MASK);
reg = glb_reg_read(S_INTR_STATUS);
// 这里的环境是 struct dla_processor *processor = NULL;
// struct dla_processor_group *group;
// struct dla_engine *engine = (struct dla_engine *)engine_data;
可以追溯一下两个函数的定义:
#define glb_reg_read(reg) reg_read(GLB_REG(reg))
#define glb_reg_write(reg, val) reg_write(GLB_REG(reg), val)
||
||
\/
# 这两个函数的定义在`engine_data.c`中找到:
uint32_t reg_read(uint32_t addr)
{
// 调用 dla_reg_read 函数来读取引擎驱动程序上下文中指定地址 addr 处的寄存器值,并将其返回。
return dla_reg_read(engine.driver_context, addr);
}
void reg_write(uint32_t addr, uint32_t reg)
{
// 调用 dla_reg_write 函数来将指定的寄存器地址 addr 和数据值 reg 写入引擎驱动程序上下文中。
dla_reg_write(engine.driver_context, addr, reg);
}
// 这里的原型定义是void dla_reg_write(void *driver_context, uint32_t addr, uint32_t reg)
// struct nvdla_device *nvdla_dev = (struct nvdla_device *)driver_context;
这里之所以可以使用engine.xxx的原因是engine是静态变量。
static struct dla_engine engine = {
.processors[DLA_OP_BDMA] = {
......
我们可以往前翻翻函数体内的两个函数定义,这里面的engine.driver_context指的就是nvdla_device结构体,而从engine.driver_context的表达来看,应该是构成了dla_engine(实例化为engine) => driver_context(实例化为nvdla_device)、nvdla_device(实例化为nvdla_dev) => engine_context(实例化为engine_data)、engine_context => dla_engine(实例化为engine,见dla_isr_handler函数定义)三条链,又是一个三件套:
1、`dla_engine(实例化为engine)` => `driver_context(实例化为nvdla_device)`
2、`nvdla_device(实例化为nvdla_dev)` => `engine_context(实例化为engine_data,见dla_isr_handler函数定义)`
3、`engine_context ` => `dla_engine(实例化为engine,见dla_isr_handler函数定义)`
5.4 complete函数
complete函数用于唤醒等待中断事件完成的进程或线程。这通常用于实现异步通知机制,以便用户空间或其他内核组件可以等待某个事件的完成。代码中的操作是complete(&nvdla_dev->event_notifier);,其中event_notifier是completion结构体变量,看看内核是怎么定义的,在kernel/sched/completion.c:
/**
* complete: - signals a single thread waiting on this completion
* @x: holds the state of this particular completion
*
* This will wake up a single thread waiting on this completion. Threads will be
* awakened in the same order in which they were queued.
*
* See also complete_all(), wait_for_completion() and related routines.
*
* If this function wakes up a task, it executes a full memory barrier before
* accessing the task state.
*/
void complete(struct completion *x)
{
unsigned long flags;
spin_lock_irqsave(&x->wait.lock, flags);
if (x->done != UINT_MAX)
x->done++;
__wake_up_locked(&x->wait, TASK_NORMAL, 1);
spin_unlock_irqrestore(&x->wait.lock, flags);
}
EXPORT_SYMBOL(complete);
// 顺带看一看completion结构体
/*
* struct completion - structure used to maintain state for a "completion"
*
* This is the opaque structure used to maintain the state for a "completion".
* Completions currently use a FIFO to queue threads that have to wait for
* the "completion" event.
*
* See also: complete(), wait_for_completion() (and friends _timeout,
* _interruptible, _interruptible_timeout, and _killable), init_completion(),
* reinit_completion(), and macros DECLARE_COMPLETION(),
* DECLARE_COMPLETION_ONSTACK().
*/
struct completion {
unsigned int done;
wait_queue_head_t wait;
};
// 其中,有两个成员变量,done代表信号量是否已满足,wait是一个链表的头,链表定义为swait_queue_head
||
||
\/
struct swait_queue_head {
raw_spinlock_t lock;
struct list_head task_list;
};
// 链表swait_queue_head有一个spinlock锁,在操作链表前需要先获取该锁。
关于这里的解释我参考了Linux Kernel Complete,注意completion函数完成了四个操作:
1)获取传入completiom的等待队列锁,获取该锁的目的在于控制对等待队列增删的并发,并保存当前的中断状态。
2)将x->done++。
3)调用swake_up_locked()函数,将x->wait链表中的等待队列的任务唤醒。
4)释放等待队列锁。
二、nvdla_core_callbacks.c代码内函数整理二
| 函数原型 | 功能 |
|---|---|
dla_debug、dla_info、dla_warn和dla_error函数 | 处理一般信息的函数,都采用了可变参数的方式来接受消息字符串和参数,通常是通过<stdarg.h>标准库中的宏来实现的。 |
dla_memset和dla_memcpy函数 | dla_memset和dla_memcpy函数分别用于将内存块的内容设置为指定的值、将一个内存块的内容复制到另一个内存块中 |
dla_get_time_us函数 | dla_get_time_us函数通过调用ktime_get_ns()函数来获取当前时间的纳秒级时间戳,然后将纳秒级时间戳除以NSEC_PER_USEC来将时间转换为微秒,并返回一个int64_t类型的整数表示微秒级的时间戳。 |
dla_reg_write和dla_reg_read函数 | dla_reg_write和dla_reg_read函数分别用于写和读寄存器 |
nvdla_engine_isr函数 | nvdla_engine_isr函数负责完成上自旋锁、完成硬件子单元乒乓寄存器组的初始化、执行计算任务、解除等待队列中的锁、释放自旋锁。 |
spin_lock_irqsave和spin_unlock_irqrestore函数 | 上自旋锁和释放自旋锁,前者:首先需要使用nvdla_device的专属锁&nvdla_dev->nvdla_lock对critical region上锁,与此同时,上锁这件事情得通告其余进程不要来打断,所以需要clri指令配合,禁止中断。 后者:首先需要使用nvdla_device的专属锁&nvdla_dev->nvdla_lock对critical region临界区释放锁,与此同时,释放锁这件事情也就意味着临界区可以允许其余进程来使用相关资源,所以需要seti指令配合,恢复中断启用和优先级。 |
dla_isr_handler函数 | dla_isr_handler函数,该函数用于处理与NVDLA引擎相关的中断事件。它接受nvdla_dev->engine_context作为参数,该参数通常包含了与引擎相关的上下文信息,以便进行特定的处理。 |
glb_reg_read和glb_reg_write函数 | 调用dla_reg_write和dla_reg_read函数分别用于写和读寄存器,顺带挖出来一个三件套:dla_engine(实例化为engine) => driver_context(实例化为nvdla_device)、nvdla_device(实例化为nvdla_dev) => engine_context(实例化为engine_data)、engine_context => dla_engine(实例化为engine,见dla_isr_handler函数定义)三条链 |
completion函数 | complete函数用于唤醒等待中断事件完成的进程或线程。这通常用于实现异步通知机制,以便用户空间或其他内核组件可以等待某个事件的完成。依次完成:获取传入completiom的等待队列锁,获取该锁的目的在于控制对等待队列增删的并发,并保存当前的中断状态;将x->done++;调用swake_up_locked()函数,将x->wait链表中的等待队列的任务唤醒;释放等待队列锁。 |
三、nvdla_core_callbacks.c代码结构体整理二
| 结构体 | 功能 |
|---|---|
dla_processor | dla_processor结构体是dla_processor_group和dla_engine的桥梁。 |
dla_processor_group | dla_processor_group结构体最重要的是作为乒乓寄存器组而存在,完成设备启动的初始配置,比如id和active,注意根据NVDLA硬件信号和架构设计整理一关于乒乓寄存器组的描述会帮助理解这个结构体的设计思路。另外该结构体也包含了dla_operation_container和dla_surface_container的union,专门用于指向特定的硬件计算子模块比如bdma、conv、sdp等的操作类型和image surface。 |
dla_engine | dla_engine结构体的作用只有一个,那就是串东西,把用于设置乒乓寄存器组配置寄存器、producer和consumer_ptr的dla_processor,设置mac阵列大小、是否使能rubik、bdma与weight_compress的dla_config,dla_task和dla_network_desc给串起来,可以说是一家之主了。当然了,还有一个最重要的*driver_context,这个要把nvdla_device给映射起来,以便于访问nvdla设备的硬件资源抽象从而支持读取和写入寄存器、获取专属锁来申请访问临界区。 |
dla_network_desc | dla_network_desc囊括了运行网络的全部信息,我们可以很明显注意到几个信息,operation_desc_index、surface_desc_index和dependency_graph_index,分别是操作、image surface和依赖图(也就是常见元操作)的索引 |
dla_task | dla_task结构体包含dla任务的common数据 |
dla_bdma_transfer_desc | bdma的传输细节 |
dla_bdma_surface_desc | bdma的surface描述,需要确定source_type和destination_type,以及数据传输的num_transfers,还需要颇为详细的传输细节,相关变量在dla_bdma_transfer_desc结构体中定义。 |
dla_bdma_op_desc | bdma的op描述,dma的作用就是传输数据,因此num_transfers成为关键的指标。 |
dla_bdma_stat_desc | dla_bdma_stat_desc结构体——这个结构体是为了看bdma的状态,有三种状态:read-stall、write_stall和runtime。 |
completion | 有两个成员变量,done代表信号量是否已满足,wait是一个链表的头 |
swait_queue_head | 链表swait_queue_head有一个spinlock,在操作链表前需要先获取该锁 |
总结
本章重点围绕dla_isr_handler函数展开介绍,介绍内容包括nvdla_device专属自旋锁去申请锁住临界区和使用专属自旋锁去释放临界区,对dla_isr_handler函数函数结合硬件抽象信息进行深入剖析。同时也对其余辅助函数进行了介绍。本章介绍的结构体偏多,但这些结构体是硬件抽象最为集中的部分。
















 1129
1129











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











