






论文分享
GenAINet通信大模型
作为通用化的人工智能模型,基础模型(Foundation models, FMs,大模型),促成了多种全新的生成型AI(Generative AI)应用。大模型领域的快速进展和迭代为下一代智能无线网络的愿景提供了重要的支撑。而联邦学习(Federated learning, FL)作为分布式网络智能的关键推动力,其与大模型之间的协同以及相互融合的探索仍处于初期阶段。新加坡科技设计大学 Tony Q.S. Quek教授团队,联合浙江大学,新加坡国立大学,对于在大模型和联邦学习在无线网络中的融合的可行性进行了概述,发表于IEEE Wireless Communications。该文章讨论了在未来智能网络中实现大模型和联邦学习融合的可行方案,并总结了相关的几大研究方向。(本推文内容由论文作者陈子晗博士提供)
The Role of Federated Learning in a Wireless World with Foundation Models
Zihan Chen1, Howard H. Yang2, Y.C. Tay3, Kai Fong Ernest Chong1, Tony Q.S. Quek1
1Singapore University of Technology and Design, Singapore
2Zhejiang University/University of Illinois Urbana-Champaign Institute, Zhejiang University, China
3National University of Singapore, Singapore
原文链接:
https://arxiv.org/abs/2310.04003
论文版权归属IEEE Wireless Communications期刊及IEEE版权方,本文分享仅用于技术交流,未经许可禁止用于商业用途。
本文首先强调了基础模型(FMs,下文称大模型)在人工智能(AI)领域的重要性。包括大语言模型(例如GPT系列、LLaMA系列)和大视觉模型(例如CLIP、SAM)在内的大模型,具有通用性强、易于适应多种下游任务的特点,其通常具备较小模型所没有的涌现能力(Emergent abilities),也为下一代智能无线网络的愿景提供了重要的支撑。作为一种保护隐私的分布式学习范式,联邦学习允许无线网络中的多个边缘用户在不暴露本地数据的情况下协同训练机器学习模型,也将在实现分布式网络智能的过程中的发挥关键作用。
在此背景下,本文强调了大模型和边缘联邦学习之间的相互融合的前景,一方面大模型的应用能够提升联邦学习系统的性能,而联邦学习也可以利用分散的数据和计算资源来协助大模型的训练。然而,大模型对于计算资源、存储和通信开销的极高要求也对支持部署边缘联邦学习系统的无线网络提出了挑战。基于以上两点,本文将重点探讨在无线网络环境中的联邦学习系统中部署大模型的可行性及其影响(To what extent are FMs suitable for FL-enabled wireless networks?)。本文随后进一步讨论了融合大模型和联邦学习的未来智能网络的新范式、研究方向和技术挑战。
一、大模型与联邦学习融合的挑战、机遇和网络架构
文章首先列举了在无线网络中大模型与联邦学习系统融合所面临的一些潜在的挑战:
1)高功耗: 训练和部署大模型的计算密集型特点,需要大量功耗和资源开销,对边缘设备和可持续部署带来了挑战。
2)大存储和内存需求: 大模型的部署需要大量的存储和内存开销,对于部署设备的硬件能力提出了很高的要求。
3)通信开销:通过无线网络传输大模型涉及大量通信开销。此开销影响上下行传输,可能导致网络拥堵和延迟增加。
4)延迟: FMs的整合必须满足下一代无线网络的严格延迟要求。高延迟会降低实时应用(如自动驾驶和智慧城市基础设施)的性能。
5)大模型的幻觉 (Hallucination of FMs): 大模型可能生成错误或无意义的输出,即模型幻觉。在需要准确可靠信息进行决策的场景中,例如支持自动驾驶、智能交通管理等关键决策系统中,大模型的幻觉现象可能会导致严重的错误决策,例如错误的路径规划或交通管理指令。
大模型与边缘联邦学习协同下的网络架构总结如下:
大模型与边缘联邦学习的协同:
在实际的边缘联邦学习系统中,系统异质性广泛存在于客户端和服务器的计算和通信能力中。因此,不可能采用“一刀切(one-size-fits-all)”的方案来部署和使用大模型。
对于计算和硬件资源充足的系统,每个客户端可以拥有一个通用或个性化的大模型。
对于资源受限的系统,可以在边缘服务器部署一个大模型,或者通过云供应商提供大模型服务(如付费API访问)。
通过边缘联邦学习训练/微调大模型:
在资源受限的无线网络中,传统的联邦学习在模型更新和聚合过程中可能因训练大模型所需的巨大计算和通信需求而很难得到部署。因此,混合的全局-本地(云-边缘)模型训练方案更为可取。该方案可以将高成本的计算任务(如大模型预训练)转移到服务器,并将低成本的计算任务(如微调fine-tuning和个性化personalization)保留在客户端,以减轻通信开销和对计算资源的超高需求。
我们同时可以在联邦学习系统中采取参数高效型(Parameter-efficient fine-tuning)的模型微调策略,实现低通信和计算开销的协同训练,以最小成本完成训练任务。
二、大模型与边缘联邦学习的协同与融合
本文提出了Foundation Model as a Service (FMaaS)的准则。如图1所示,在边缘联邦学习系统中,大模型的协同与融合类型可以总结为以下几种类型:
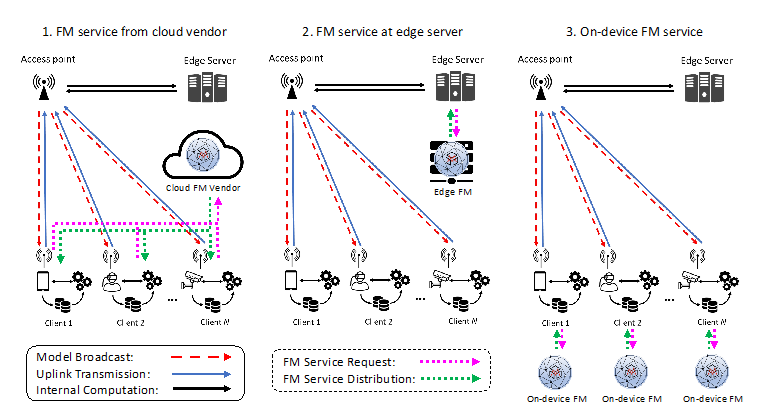
图1: 在边缘联邦学习系统中融合大模型服务的网络架构
1. FMs在边缘联邦学习训练预处理阶段的应用
1)数据增强:考虑现实世界中的数据类别不平衡问题,大模型可以通过生成数据来帮助模型训练。这种生成能力能够提高模型对于少数/尾部类别数据的表征能力,从而改善模型的总体性能。
2)数据合成:在服务不可用或中断的情况下,边缘服务器可以利用大模型生成合成数据。这些数据可以用于模型蒸馏,以提高模型的泛化性能和鲁棒性。
2. 大模型在边缘联邦学习训练阶段的应用
1)在传统的深度学习中,训练良好的模型可以作为teacher model,帮助训练小模型。在边缘联邦学习网络中,我们可以考虑将预训练(pre-trained)的大模型作为teacher model,通过知识蒸馏提升小模型的训练性能。
2)在具有强大硬件能力的边缘设备(如自动驾驶车辆)上,可以本地部署大模型,并通过迁移学习和知识蒸馏技术,利用大模型的知识来提升本地模型的性能。
3. 大模型在模型评估中的应用
预训练大模型可以作为性能评估的基准,帮助验证较小模型的表现。我们可以通过比较大模型和传统小模型的输出,实现对小模型的泛化性能和潜在的过拟合风险的评估。
三、基于边缘联邦学习的大模型微调与部署
本节探讨了在无线网络上使用联邦学习训练/微调大模型的应用场景和方法。随着大模型规模的不断扩大,在用尽所有公开可用的数据作为训练数据后,将不可避免地利用个人数据来帮助模型的训练和微调。由于使用个人数据固有的隐私问题,我们无法将多个来源的个人数据进行聚合来展开训练。因此,边缘联邦学习系统的部署非常适合于大模型在个人隐私数据上的训练/本地微调。可行方案如图2和下文所示。
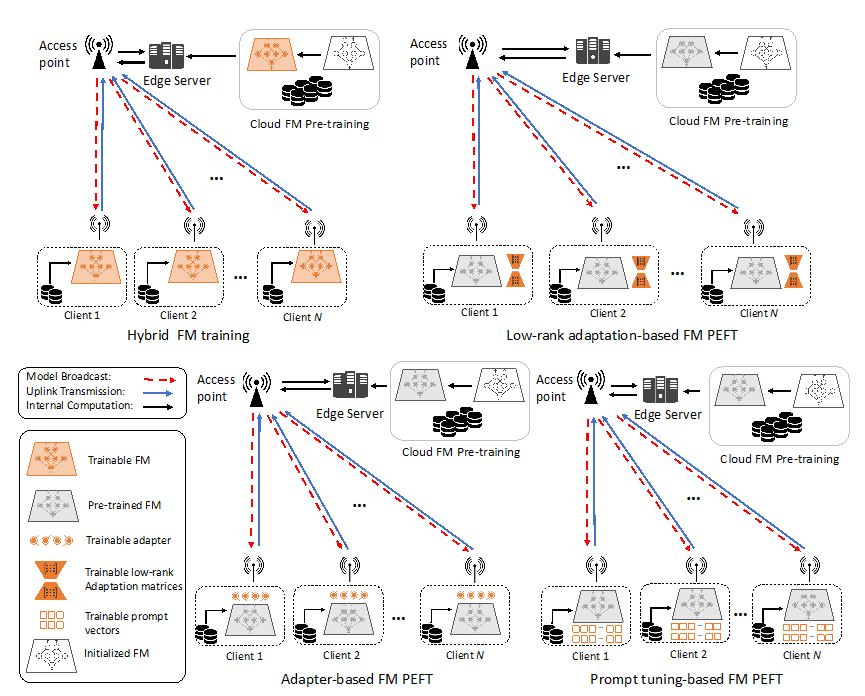
图2: 基于边缘联邦学习的大模型训练/微调方案
1. 混合训练方案
混合训练方案将大模型的云端预训练和本地微调相结合,分为两个阶段:第一阶段在云端或边缘服务器上进行集中预训练,第二阶段在分布式客户端上进行本地微调或个性化训练。
随后的本地微调阶段可以针对每个客户端的具体需求进行个性化调整,从而在保持隐私的同时提高模型性能。
2. 参高效型大模型微调
在训练大模型的过程中,更新所有参数可能会带来过高的计算和存储开销。参数高效型模型微调(Parameter-efficient fine-tuning, PEFT)通过仅更新部分参数(如adapter权重或prompt向量)来实现快速微调,从而显著降低训练成本,并同时降低了联邦学习过程的通信开销。
1)基于Adapter的模型微调:
此方案仅需要在预训练模型上引入额外的Adapter层。边缘设备在训练中仅更新Adapter中的少量参数,在模型聚合时,仅传输和更新Adapter权重,实现大幅减少需要通信和计算开销。
2)基于LoRA的模型微调:
此方案将可训练的低秩矩阵与冻结的预训练权重矩阵并行合并。相对于Adapter方案,该方案并不引入额外的推理时延,并在模型聚合时仅传输和更新低秩矩阵,同时降低通信和计算开销。
3)基于Prompt的微调:
该方案通过调整Prompt向量来提高大模型的性能,无需通过训练更新模型参数。相对于前两种方案,该方案的通信开销更低。

表1: 在联邦学习系统中基于不同PEFT方案的大模型微调在Wikitext上的性能对比
我们在联邦学习系统中对LLaMA-7B模型进行基于Adapter和LoRA微调的性能进行了比较。表1展示了在联邦学习系统中PEFT微调方法的有效性。我们可以通过模型量化策略(AWQ)进一步减少内存开销 (从13.6 GB 降低到 3.7 GB)和延迟,同时保持模型性能不变。
四、 未来研究方向展望
本节讨论了在大模型和联邦学习融合架构中需要进一步研究的问题。为了在无线网络中实现大模型和边缘联邦学习系统的有效融合,本文总结了以下几个关键研究方向:
1. 大模型服务请求和客户端参与的激励设计:
训练大模型成本高昂。在融合了大模型的边缘联邦学习网络中,大模型服务请求(如合成数据生成和预训练模型下载)可能需要适当的激励机制来推动大模型供应商(FM Vendor)提供服务。因此,如何激励大模型供应商提供大模型服务(FMaaS)仍然是一个待解决的问题。
2. 大模型服务质量(QoS)与计算资源的联合优化:
由于大模型训练对计算、存储和通信的巨大需求,在资源受限的无线网络中,我们需要做到在确保大模型服务质量的同时,高效利用有限的资源。未来的工作需要进一步探索联合优化方案,以平衡边缘联邦学习网络中大模型服务的QoS与资源利用。
3. 大模型服务的隐私和鲁棒性问题:
在AI相关任务和服务中,数据隐私和模型隐私的保护日益重要。在边缘联邦学习领域中,隐私保护和鲁棒性增强的相关方法已经被广泛研究。但在融合了大模型的无线网络中,这些方法的表现仍有待探索。因此,未来的工作需要进一步研究如何在保护隐私和增强鲁棒性的同时,确保大模型在无线网和边缘联邦学习系统中的性能。
4. 低延迟服务的任务调度:
在智能网络的设计和部署中,延迟是一个重要的因素。在联邦学习和大模型的协同工作网络中,不同的任务所引入的延迟的影响差异明显并且在系统设计中无法被忽略。随着大模型在未来无线网络中重要性的日渐提高,任务自适应调度协议将变得越来越重要,未来的工作需要在确保整体性能的稳定的同时实现可控的时延表现。
5. 传输大模型权重的通信协议设计:
在未来泛在智能网络中,大模型权重的传输将成为网络流量中不可忽视的一部分。目前,还没有专门针对大模型传输的编码和通信协议。未来需要开发高效的传输协议和编码技术,在实现高效通信的同时,考虑大模型架构的内在结构特性、大模型不同模块之间的数据流以及模型完整性。
五、结论
本文旨在探讨大模型和边缘联邦学习系统融合的可行性,并提出了实现未来智能网络的新范式,推动下一代智能无线网络的发展。本文希望通过这些探索,提供一个全面的视角,推动后续工作实现大模型和边缘联邦学习系统在无线网络中的有效融合和发展。

















 172
172

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









