







目录
1.Loss function for Logistic Regression
2.Regularization in Logistic Regression
Calculating a Probability
Many problems require a probability estimate as output. Logistic regression is an extremely efficient mechanism for calculating probabilities. Practically speaking, you can use the returned probability in either of the following two ways:
-
"As is"
-
Converted to a binary category.
Let's consider how we might use the probability "as is." Suppose we create a logistic regression model to predict the probability that a dog will bark during the middle of the night. We'll call that probability:
p(bark | night)
If the logistic regression model predicts a p(bark | night) of 0.05, then over a year, the dog's owners should be startled awake approximately 18 times:
startled = p(bark | night) * nights
18 ~= 0.05 * 365
In many cases, you'll map the logistic regression output into the solution to a binary classification problem, in which the goal is to correctly predict one of two possible labels (e.g., "spam" or "not spam").
You might be wondering how a logistic regression model can ensure output that always falls between 0 and 1. As it happens, a sigmoid function, produces output having those same characteristics:
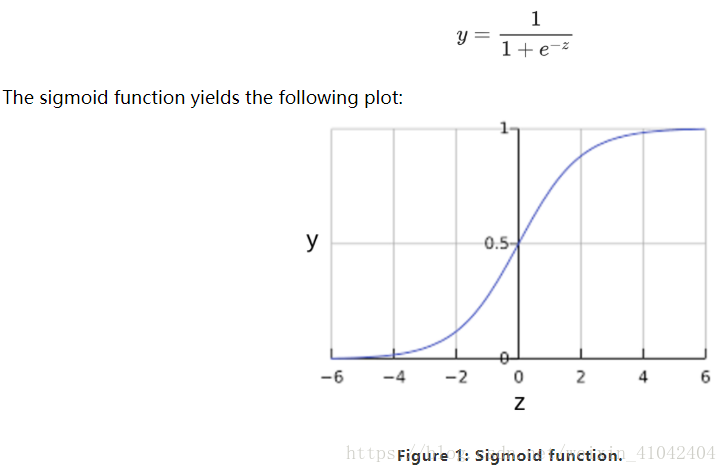
If z represents the output of th
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









