







第五章 分类:其他技术
5.6 组合方法
1. 构造组合分类器的原理和方法
- 基分类器需要互相独立,且比随机猜测要好。
- 构建组合分类器的方法:
- 通过处理训练数据集:根据抽样分布对原始数据重新采样
- 装袋(bagging)、提升(boosting)
- 通过处理输入特征:选择输入特征的子集来形成每个训练集
- 随机森林
- 通过处理类标号(变换为二类问题):
- 错误-纠正输出编码
- 通过处理学习算法
- 通过处理训练数据集:根据抽样分布对原始数据重新采样
- 组合方法对于不稳定的分类器效果较好(决策树、ANN)
2. 偏倚-方差分解
- 分析预测模型的预测误差的形式化方法
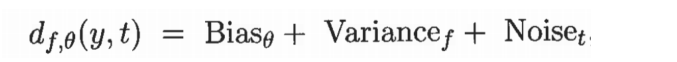
- 偏倚:分类器对它的决策边界性质所做的假定越强,分类器的偏倚就越大。
- 更下的树,假定越强
3. 组合方法技术
-
装袋
- 通过减少基分类器的方差来改善泛化误差
- 装袋有助于提升不稳定的基分类器
-
提升
- 迭代地改变训练样本的分布,提高误分类样本的权值,降低正确分类的样本的权重
- 通过聚集每个提升轮得到的基分类
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









