







动态网页api分析实例:爬取dropbox上的pdf
今天老师让我下载一个网课里面的pdf材料,pdf的数目比较多,一部分pdf是放在dropbox上面的,看了一下是一个动态网页。想起来我的爬虫教程好久没填坑了,今天我就打算拿爬虫来完成这个任务,顺便写个教程,我今天选择的方式是分析api,下次再遇到动态网页写博客的时候,我就用js引擎(flag已经立下了)。废话不多说,下面开始。
任务
- 爬取的页面:https://aisecure.github.io/TEACHING/cs598.html
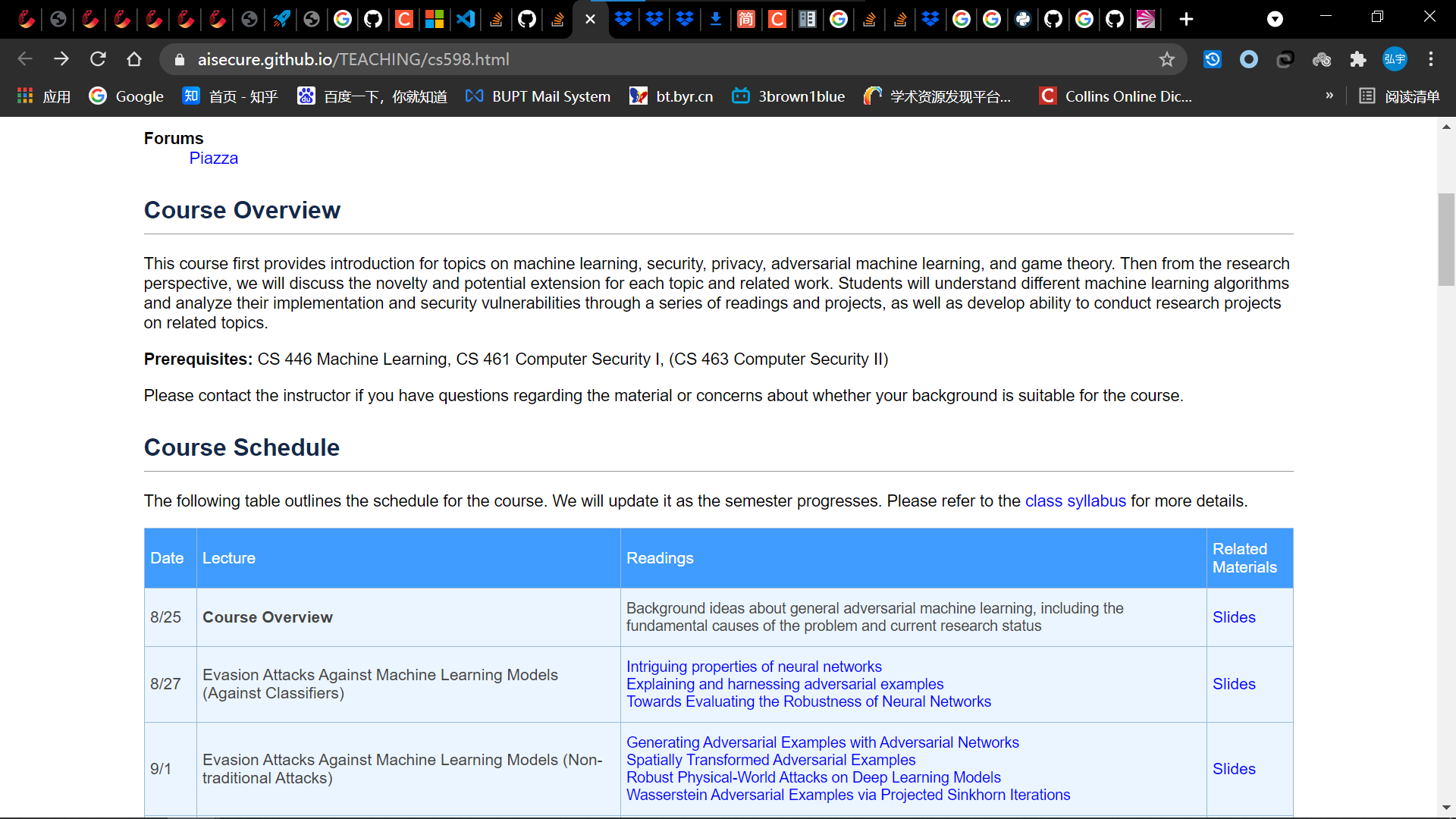
- 具体爬取要求,根据时间创建文件夹,然后把当天的所有pdf文件放在文件夹中;
分析
- 拿到任务后我首先分析了一下要爬取的文件:一类是论文,一类是幻灯片;论文比较好爬取,但是幻灯片是放在dropbox上面的,有一定难度;
- 这个主页面是一个静态的页面,没啥难度,拿到网页信息后对网页结构解析后搜索一下,就能拿到我们需要爬取内容。
- 其中论文部分的url比较好分析,直接从对应元素的href属性中拿到pdf的url:
- 大部分的论文是挂在了arxiv上,但是有的链接是直接指向pdf文件的,有的链接就没有,需要+’.pdf’;
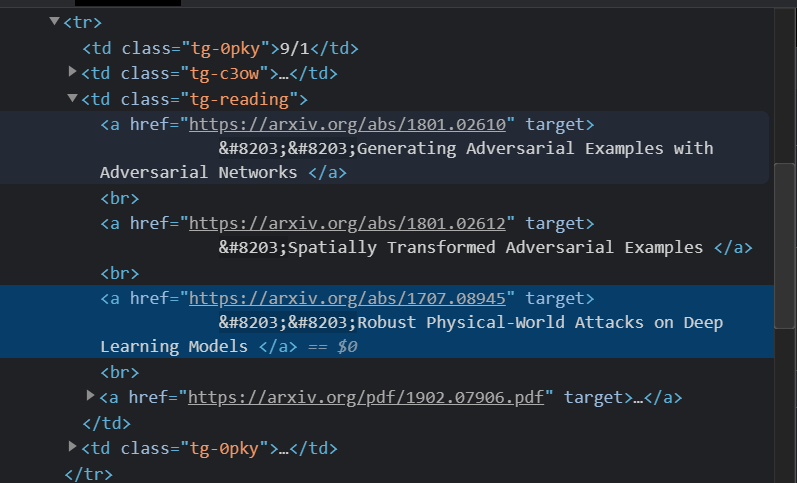
- 还有论文是在openreview上面的,把链接中的forum改成pdf就可以下载了;

- 其它的论文都通过链接可以直接下载;
- 大部分的论文是挂在了arxiv上,但是有的链接是直接指向pdf文件的,有的链接就没有,需要+’.pdf’;
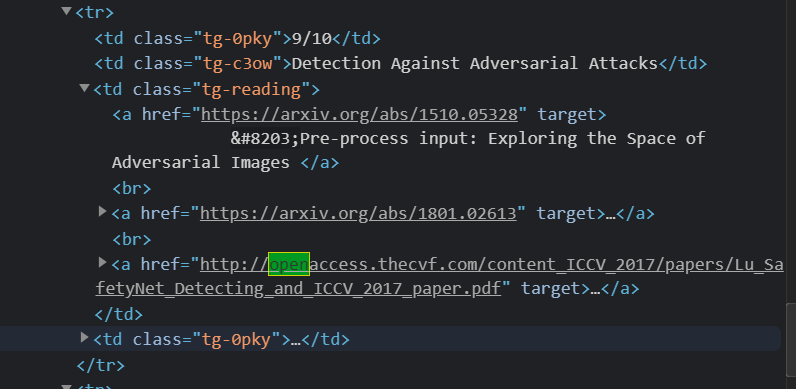
- dropbox上面的pdf文件的下载链接是放在动态网页上的的,所以需要费点周折。本次采用的方式是分析api。首先抓一波包,发现点击了立即下载的按钮后,有两个包比较重要
- 第一个包是下载pdf文件的包
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0JD9lSwC-1616418037476)(https://raw.githubusercontent.com/Richardhongyu/pic/main/20210322201751.png)]- 携带参数
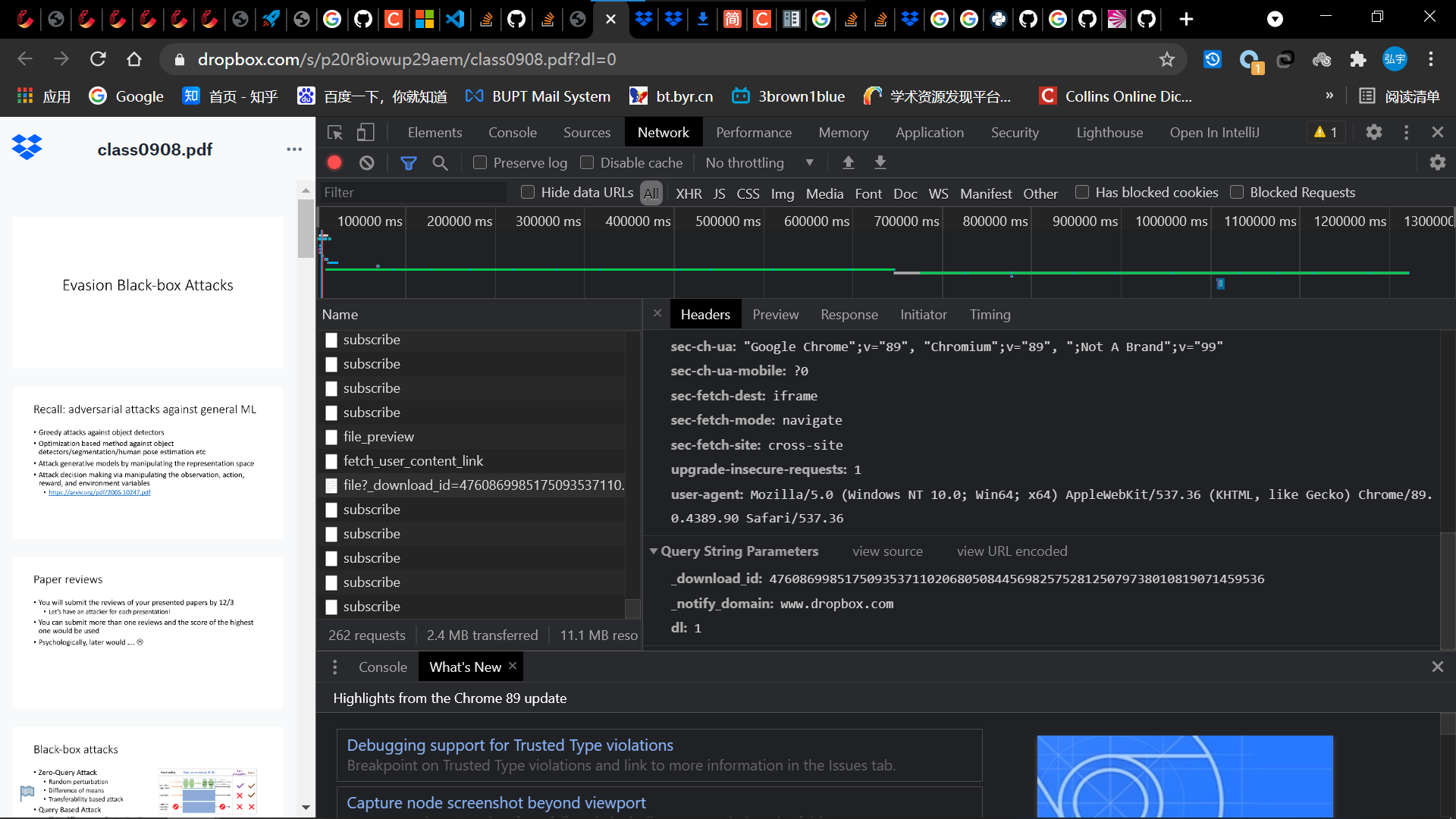
- 经过观察_download_id和request url两部分是根据下载的pdf变化的
- 携带参数
- 然后看到第二个包
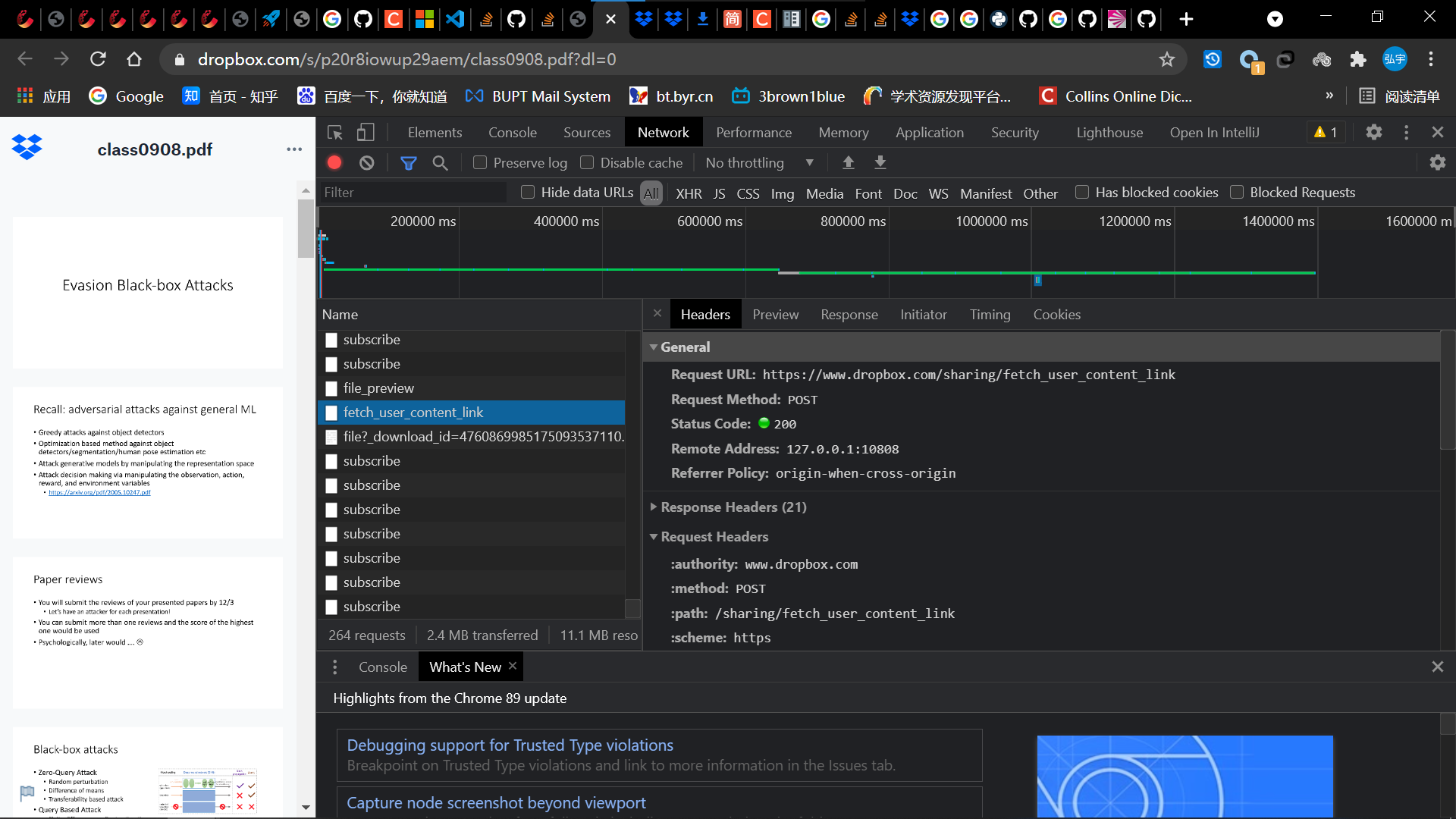
- 它的responce里面有下载链接的一部分,
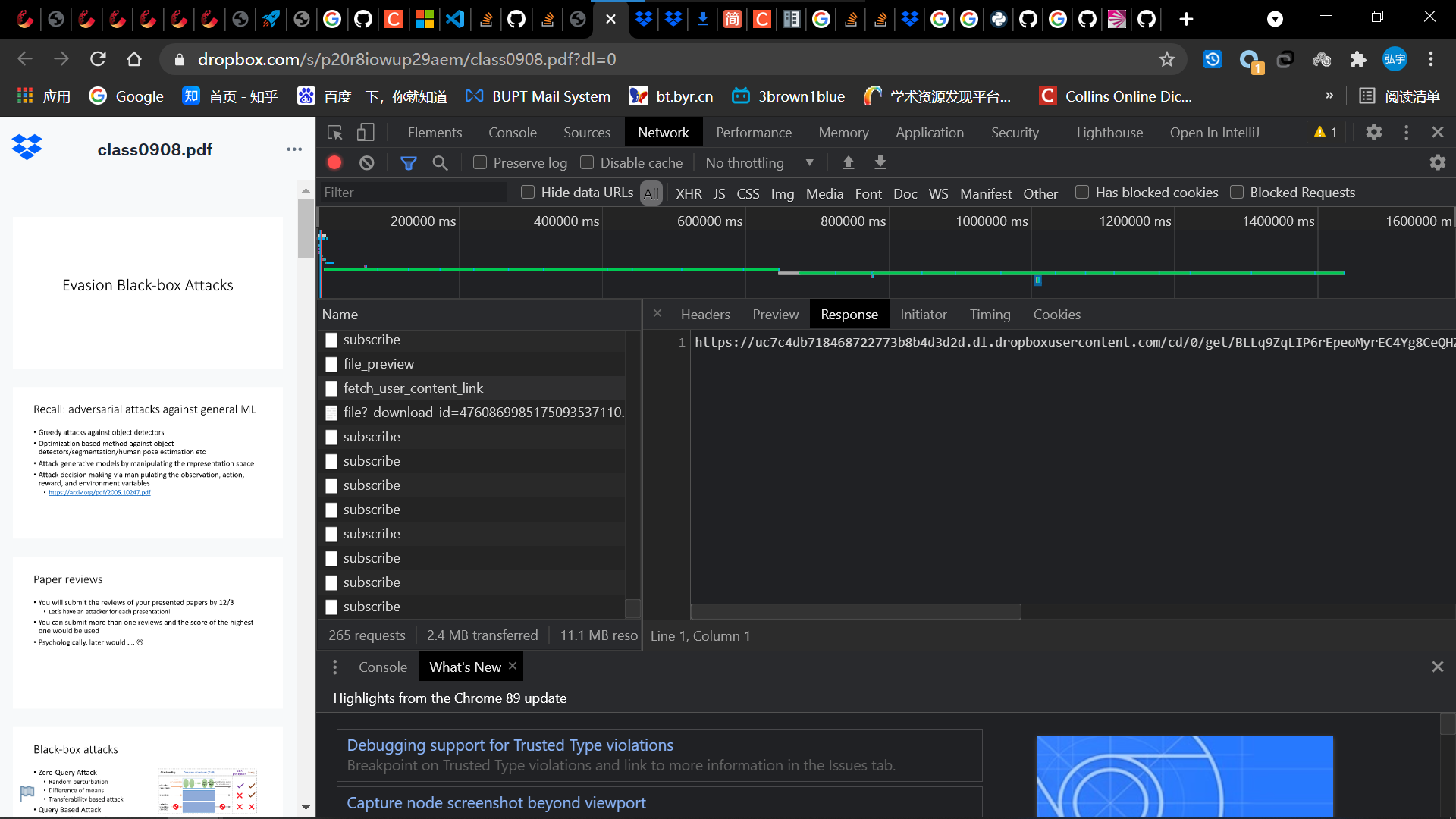
- 经过观察第一个包将第二个包的response和某些参数组合为它的request url,从而得到了pdf文件。
- 现在需要得到这个包的携带参数
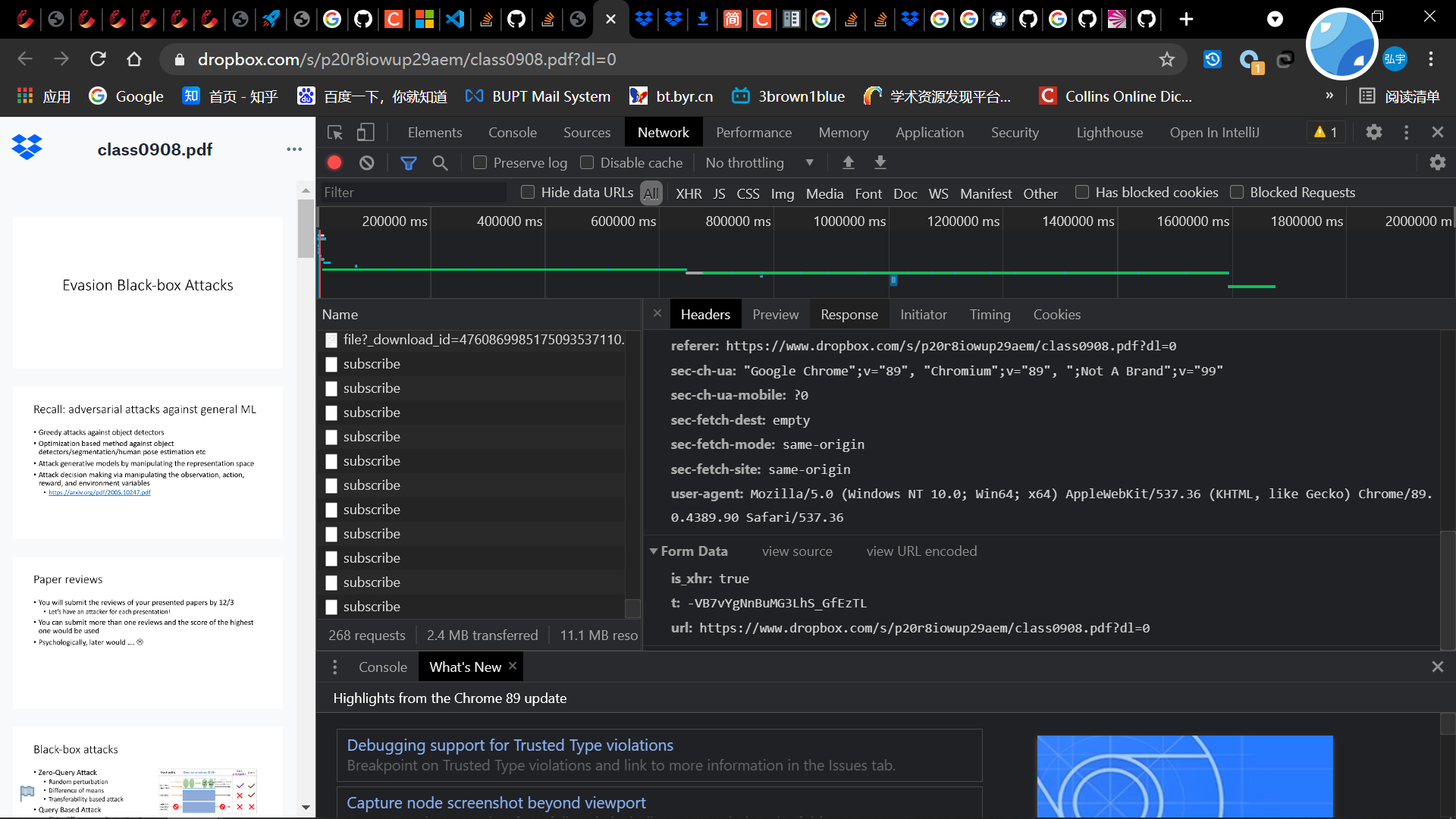
- 经过观察,第一个参数is_xhr和第二个参数t都是固定的,第三个参数和这个pdf的url,所以这个api就分析完了
- 它的responce里面有下载链接的一部分,
- 再返回来分析第一个包
- 现在第一个包就短_download_id未知了,推测是在js代码里面生成的,所以观察使用过的js函数
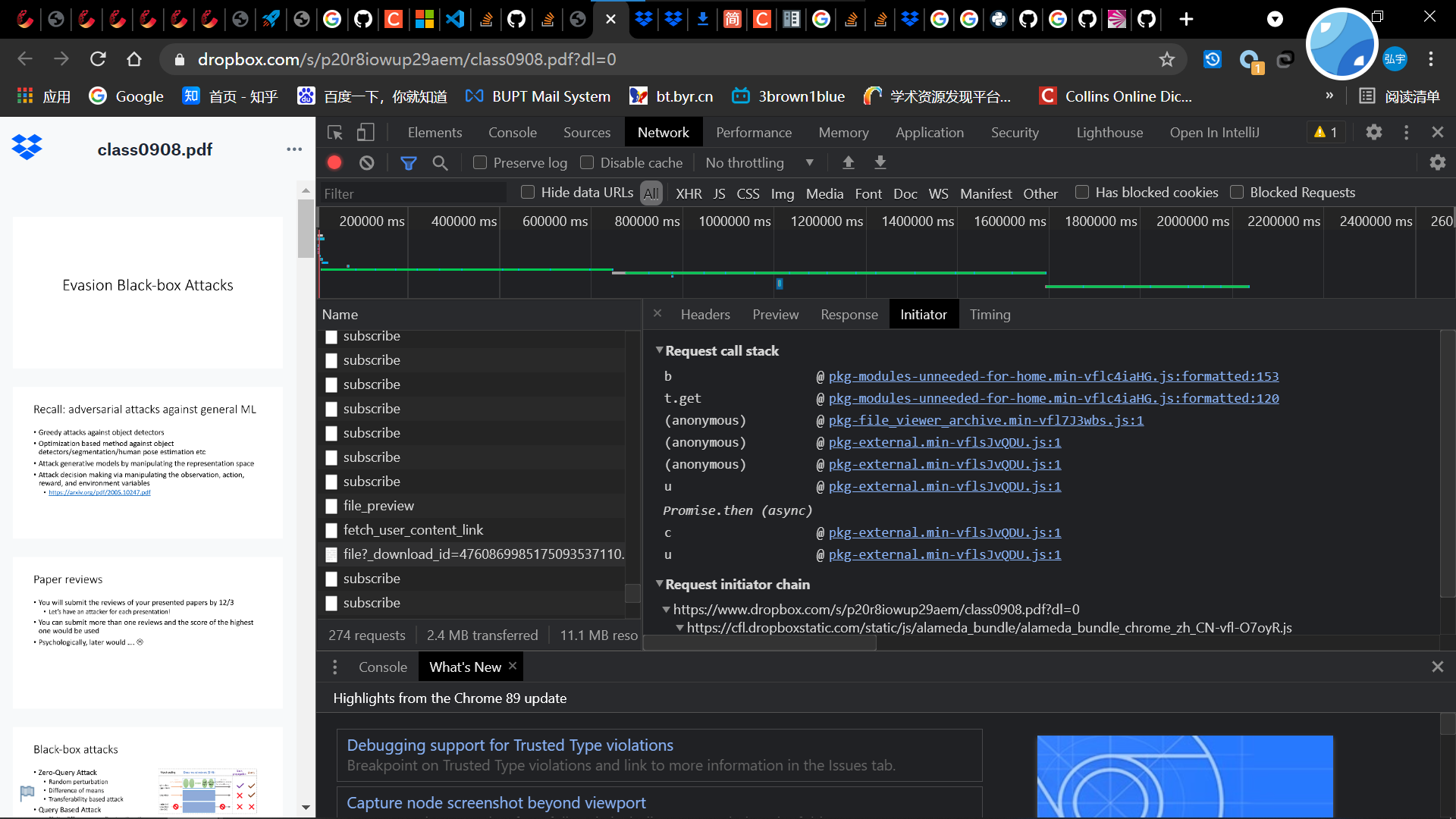
- 经过阅读和搜索找到了这个地方

- 原来就是个随机数。。。分析到这个地方,我尬住了,原来还以为有个加密函数的,没想到直接是随机数,那你加这玩意干啥。上网一查,原来是为了每次的url不一样避免缓存。
- 所以第一个包也就解决了,直接用一个固定的_download_id就可以
- 现在第一个包就短_download_id未知了,推测是在js代码里面生成的,所以观察使用过的js函数
- 第一个包是下载pdf文件的包
- 其中论文部分的url比较好分析,直接从对应元素的href属性中拿到pdf的url:
写代码和debug
-
注意事项
- 下面就是正常的写代码和debug环节了,这里列出了一些坑:
- 因为dropbox是国外的,需要挂代理
- 因为爬取的是pdf,需要用open方式保存到本地文件
- 在访问第一个包的时候,需要添加cookies,否则会有403错误
- 爬取过程中发现有的资源丢失了,所以做了异常处理
-
具体代码
import requests from bs4 import BeautifulSoup import os import re # use proxies to speed up proxies = { "http": "socks5://127.0.0.1:10808", "https": "socks5://127.0.0.1:10808", } data = requests.get("https://aisecure.github.io/TEACHING/cs598.html") soup = BeautifulSoup(data.content, 'html.parser') entries = soup.find_all("tr") entries = list(entries) for k, i in enumerate(entries[1:]): i = str(i) entry_data = BeautifulSoup(i, 'html.parser') date_and_sides = entry_data.find_all(class_="tg-0pky") readings = entry_data.find_all(class_="tg-reading") if date_and_sides!= []: date_list = str.split(date_and_sides[0].string, '/') print(date_list) month = date_list[0] day = date_list[1] if len(month)==1: month = '0'+month if len(day)==1: day = '0'+day month_day = month+day print(month_day) if len(date_and_sides) == 2: if not os.path.exists(month_day): os.mkdir(month_day) if readings!=[]:#readings readings = str(readings[0]) readings = BeautifulSoup(readings, 'html.parser') for link in readings.find_all('a'): pdf_link = link.get('href') if 'http' not in pdf_link: break elif 'openreview' in pdf_link: pdf_link = pdf_link.replace('forum', 'pdf') elif 'arxiv' in pdf_link and 'pdf' not in pdf_link: pdf_link = pdf_link + '.pdf' print(pdf_link) pdf_name = pdf_link.split('/')[-1] if '.pdf' not in pdf_name: pdf_name = pdf_name.split('=')[-1]+'.pdf' print(pdf_name) pdf_data = requests.get(pdf_link, proxies=proxies) f = open(month_day+'/'+pdf_name,'wb') f.write(pdf_data.content) f.close() slides = date_and_sides[1]#slides slides = str(slides) slides = BeautifulSoup(slides, 'html.parser') for link in slides.find_all('a'): pdf_link = link.get('href') print(pdf_link) if 'dropbox' in pdf_link and k!=9 and k!=10:#k==9, slide file is in google driver, we don't have access to it;10 file not exits url = 'https://www.dropbox.com/sharing/fetch_user_content_link' cookies = {'__Host-ss':'bcD4Chza3M', 'locale':'zh_CN', 'gvc':'MTQxMzI3NDU0NjU2NzAyODExNDM4MzQ3NTk2NDExMjgyNjc2MzI2', 't':'-VB7vYgNnBuMG3LhS_GfEzTL', '__Host-js_csrf':'-VB7vYgNnBuMG3LhS_GfEzTL', 'seen-sl-signup-modal':'VHJ1ZQ%3D%3D', 'seen-sl-download-modal':'VHJ1ZQ%3D%3D'} data={ 'is_xhr': 'true', 't': '-VB7vYgNnBuMG3LhS_GfEzTL', 'url': pdf_link } slide_data = requests.post(url, data=data, proxies = proxies, cookies = cookies) middle_url = str(slide_data.content) print(middle_url) middle_url = middle_url.split('?')[0] middle_url = middle_url[2:] data_2={ '_download_id':'013885563736029338651059959499724834269999834692877836324471532568', '_notify_domain':'www.dropbox.com', 'dl':'1' } pdf_data = requests.get(middle_url, data=data_2, proxies = proxies) pdf_name = pdf_link.split('/')[-1] pdf_name = pdf_name.split('?')[0] print(pdf_name) f = open(month_day+'/'+pdf_name,'wb') f.write(pdf_data.content) f.close() elif len(date_and_sides) == 1: if not os.path.exists(month_day): os.mkdir(month_day) if readings!=[]:#readings readings = str(readings[0]) readings = BeautifulSoup(readings, 'html.parser') for link in readings.find_all('a'): pdf_link = link.get('href') if 'http' not in pdf_link: break elif 'openreview' in pdf_link: pdf_link = pdf_link.replace('forum', 'pdf') elif 'arxiv' in pdf_link and 'pdf' not in pdf_link: pdf_link = pdf_link + '.pdf' print(pdf_link) pdf_name = pdf_link.split('/')[-1] if '.pdf' not in pdf_name: pdf_name = pdf_name.split('=')[-1]+'.pdf' print(pdf_name) pdf_data = requests.get(pdf_link, proxies=proxies) f = open(month_day+'/'+pdf_name,'wb') f.write(pdf_data.content) f.close() slides = date_and_sides[1]#slides slides = str(slides) slides = BeautifulSoup(slides, 'html.parser') for link in slides.find_all('a'): pdf_link = link.get('href') print(pdf_link) if 'dropbox' in pdf_link and k!=9 and k!=10:#k==9, slide file is in google driver, we don't have access to it;10 file not exits url = 'https://www.dropbox.com/sharing/fetch_user_content_link' cookies = {'__Host-ss':'bcD4Chza3M', 'locale':'zh_CN', 'gvc':'MTQxMzI3NDU0NjU2NzAyODExNDM4MzQ3NTk2NDExMjgyNjc2MzI2', 't':'-VB7vYgNnBuMG3LhS_GfEzTL', '__Host-js_csrf':'-VB7vYgNnBuMG3LhS_GfEzTL', 'seen-sl-signup-modal':'VHJ1ZQ%3D%3D', 'seen-sl-download-modal':'VHJ1ZQ%3D%3D'} data={ 'is_xhr': 'true', 't': '-VB7vYgNnBuMG3LhS_GfEzTL', 'url': pdf_link } slide_data = requests.post(url, data=data, proxies = proxies, cookies = cookies) middle_url = str(slide_data.content) print(middle_url) middle_url = middle_url.split('?')[0] middle_url = middle_url[2:] data_2={ '_download_id':'013885563736029338651059959499724834269999834692877836324471532568', '_notify_domain':'www.dropbox.com', 'dl':'1' } pdf_data = requests.get(middle_url, data=data_2, proxies = proxies) pdf_name = pdf_link.split('/')[-1] pdf_name = pdf_name.split('?')[0] print(pdf_name) f = open(month_day+'/'+pdf_name,'wb') f.write(pdf_data.content) f.close()















 765
765











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









