







 本文详细介绍了Linux内核中CPU时间的统计方式,包括tick统计和上下文切换统计。在tick统计中,通过周期性时钟中断检测CPU上的进程并更新其使用时间。在上下文切换统计中,利用内核的vtime_accounting机制在进程切换时进行时间记录。统计结果最终写入/proc/stat文件,供如top命令等使用。文章还探讨了不同内核配置选项对统计方式的影响。
本文详细介绍了Linux内核中CPU时间的统计方式,包括tick统计和上下文切换统计。在tick统计中,通过周期性时钟中断检测CPU上的进程并更新其使用时间。在上下文切换统计中,利用内核的vtime_accounting机制在进程切换时进行时间记录。统计结果最终写入/proc/stat文件,供如top命令等使用。文章还探讨了不同内核配置选项对统计方式的影响。
统计子系统
这篇文章主要参考了[1-4]的内容
不同的任务时间统计方式
-
相关数据结构
-
在include/kernel/kernel_stat.h中定义了数据结构来变表示每个CPU的使用情况
-
这个数据结构一定要和进程调度过程中红黑树那个数据结构区分开来,虽然两个数据结构都会在tick中加以更新,但是更新的函数截然不同
-
-
tick统计
-
问题
-
tick统计是在周期性时钟中断时,检测目前的CPU上是在跑什么程序,然后将这个tick的时间归到这个程序中,但是这样很容易被人利用,如果程序在每一个tick前恰好让出CPU,则不会被tick统计到[2-3]。
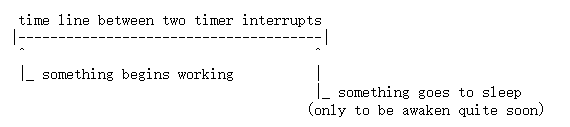
-
-
统计过程
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rTugj46u-1630926489497)(https://raw.githubusercontent.com/Richardhongyu/pic/main/20210815081426.png)]
-
目前在Linux内核中会通过一个周期性时钟中断来判断正在执行的进程的属性,进而完成统计任务,这个CPU的时钟中断间隔我们称之为tick;
-
目前统计CPU使用情况的算法是在每一次周期性时钟中断时,将中断时执行的任务认为是这个tick内CPU执行的任务,进而来统计CPU利用情况,简单来说就是通过抽样的算法来统计,具体过程如下
-
首先每一个CPU在内核初始化时都会创建一个结构体,来统计CPU的使用情况,代码;
enum cpu_usage_stat { CPUTIME_USER, CPUTIME_NICE, CPUTIME_SYSTEM, CPUTIME_SOFTIRQ, CPUTIME_IRQ, CPUTIME_IDLE, CPUTIME_IOWAIT, CPUTIME_STEAL, CPUTIME_GUEST, CPUTIME_GUEST_NICE, NR_STATS, }; -
在每一个tick的中断过程中,我们会对当前的使用情况进行统计,代码;
void account_process_tick(struct task_struct *p, int user_tick) { u64 cputime, steal; if (vtime_accounting_enabled_this_cpu()) return; if (sched_clock_irqtime) { irqtime_account_process_tick(p, user_tick, 1); return; } cputime = TICK_NSEC; //统计steal字段 steal = steal_account_process_time(ULONG_MAX); if (steal >= cputime) return; cputime -= steal; //重点在这里,根据当前执行的进程情况,分别统计 //如果执行的是用户态代码 if (user_tick) account_user_time(p, cputime); //如果执行的是系统态代码 else if ((p != this_rq()->idle) || (irq_count() != HARDIRQ_OFFSET)) account_system_time(p, HARDIRQ_OFFSET, cputime); //如果CPU处于空闲状态 else account_idle_time(cputime); } -
如果是用户态
void account_user_time(struct task_struct *p, u64 cputime) { int index; /* Add user time to process. */ p->utime += cputime; account_group_user_time(p, cputime); //统计到user还是nice字段 index = (task_nice(p) > 0) ? CPUTIME_NICE : CPUTIME_USER; /* Add user time to cpustat. */ task_group_account_field(p, index, cputime); /* Account for user time used */ acct_account_cputime(p); } -
如果是系统态
void account_system_time(struct task_struct *p, int hardirq_offset, u64 cputime) { int index; // 统计guest和guest_nice字段 if ((p->flags & PF_VCPU) && (irq_count() - hardirq_offset == 0)) { account_guest_time(p, cputime); return; } //如果处于执行硬中断上下文的过程中,统计到hi字段 if (hardirq_count() - hardirq_offset) index = CPUTIME_IRQ; //如果处于执行软中断上下文的过程中,统计到si字段 else if (in_serving_softirq()) index = CPUTIME_SOFTIRQ; //执行system代码,统计到system字段 else index = CPUTIME_SYSTEM; account_system_index_time(p, cputime, index); } -
如果是空闲情况
void account_idle_time(u64 cputime) { u64 *cpustat = kcpustat_this_cpu->cpustat; struct rq *rq = this_rq(); // IO操作,统计到iowait字段 if (atomic_read(&rq->nr_iowait) > 0) cpustat[CPUTIME_IOWAIT] += cputime; // 空闲,统计到idle字段 else cpustat[CPUTIME_IDLE] += cputime; } -
这些数据是保存在内存中的,最终会在被访问时写入到/proc/stat文件中,代码;
-
创建/proc/stat文件;
static int __init proc_stat_init(void) { proc_create("stat", 0, NULL, &stat_proc_ops); return 0; } -
操作/proc/stat文件;
static const struct proc_ops stat_proc_ops = { .proc_flags = PROC_ENTRY_PERMANENT, .proc_open = stat_open, .proc_read_iter = seq_read_iter, .proc_lseek = seq_lseek, .proc_release = single_release, }; -
在stat_open函数中,我们打开了/proc/stat文件,并且利用show_stat函数完成了信息的写入;
static int stat_open(struct inode *inode, struct file *file) { unsigned int size = 1024 + 128 * num_online_cpus(); /* minimum size to display an interrupt count : 2 bytes */ size += 2 * nr_irqs; return single_open_size(file, show_stat, NULL, size); } -
show_stat文件
static int show_stat(struct seq_file *p, void *v) { int i, j; u64 user, nice, system, idle, iowait, irq, softirq, steal; u64 guest, guest_nice; u64 sum = 0; u64 sum_softirq = 0; unsigned int per_softirq_sums[NR_SOFTIRQS] = {0}; struct timespec64 boottime; user = nice = system = idle = iowait = irq = softirq = steal = 0; guest = guest_nice = 0; getboottime64(&boottime); //这个地方是统计了所有CPU的数据,也就是/proc/stat中第一行的结果 for_each_possible_cpu(i) { struct kernel_cpustat kcpustat; u64 *cpustat = kcpustat.cpustat; kcpustat_cpu_fetch(&kcpustat, i); user += cpustat[CPUTIME_USER]; nice += cpustat[CPUTIME_NICE]; system += cpustat[CPUTIME_SYSTEM]; idle += get_idle_time(&kcpustat, i); iowait += get_iowait_time(&kcpustat, i); irq += cpustat[CPUTIME_IRQ]; softirq += cpustat[CPUTIME_SOFTIRQ]; steal += cpustat[CPUTIME_STEAL]; guest += cpustat[CPUTIME_GUEST]; guest_nice += cpustat[CPUTIME_GUEST_NICE]; sum += kstat_cpu_irqs_sum(i); sum += arch_irq_stat_cpu(i); for (j = 0; j < NR_SOFTIRQS; j++) { unsigned int softirq_stat = kstat_softirqs_cpu(j, i); per_softirq_sums[j] += softirq_stat; sum_softirq += softirq_stat; } } sum += arch_irq_stat(); seq_put_decimal_ull(p, "cpu ", nsec_to_clock_t(user)); seq_put_decimal_ull(p, " ", nsec_to_clock_t(nice)); seq_put_decimal_ull(p, " ", nsec_to_clock_t(system)); seq_put_decimal_ull(p, " ", nsec_to_clock_t(idle)); seq_put_decimal_ull(p, " ", nsec_to_clock_t(iowait)); seq_put_decimal_ull(p, " ", nsec_to_clock_t(irq)); seq_put_decimal_ull(p, " ", nsec_to_clock_t(softirq)); seq_put_decimal_ull(p, " ", nsec_to_clock_t(steal)); seq_put_decimal_ull(p, " ", nsec_to_clock_t(guest)); seq_put_decimal_ull(p, " ", nsec_to_clock_t(guest_nice)); seq_putc(p, '\n'); //这个地方是分别统计各个CPU的数据 for_each_online_cpu(i) { struct kernel_cpustat kcpustat; u64 *cpustat = kcpustat.cpustat; kcpustat_cpu_fetch(&kcpustat, i); /* Copy values here to work around gcc-2.95.3, gcc-2.96 */ user = cpustat[CPUTIME_USER]; nice = cpustat[CPUTIME_NICE]; system = cpustat[CPUTIME_SYSTEM]; idle = get_idle_time(&kcpustat, i); iowait = get_iowait_time(&kcpustat, i); irq = cpustat[CPUTIME_IRQ]; softirq = cpustat[CPUTIME_SOFTIRQ]; steal = cpustat[CPUTIME_STEAL]; guest = cpustat[CPUTIME_GUEST]; guest_nice = cpustat[CPUTIME_GUEST_NICE]; seq_printf(p, "cpu%d", i); seq_put_decimal_ull(p, " ", nsec_to_clock_t(user)); seq_put_decimal_ull(p, " ", nsec_to_clock_t(nice)); seq_put_decimal_ull(p, " ", nsec_to_clock_t(system)); seq_put_decimal_ull(p, " ", nsec_to_clock_t(idle)); seq_put_decimal_ull(p, " ", nsec_to_clock_t(iowait)); seq_put_decimal_ull(p, " ", nsec_to_clock_t(irq)); seq_put_decimal_ull(p, " ", nsec_to_clock_t(softirq)); seq_put_decimal_ull(p, " ", nsec_to_clock_t(steal)); seq_put_decimal_ull(p, " ", nsec_to_clock_t(guest)); seq_put_decimal_ull(p, " ", nsec_to_clock_t(guest_nice)); seq_putc(p, '\n'); } seq_put_decimal_ull(p, "intr ", (unsigned long long)sum); show_all_irqs(p); seq_printf(p, "\nctxt %llu\n" "btime %llu\n" "processes %lu\n" "procs_running %lu\n" "procs_blocked %lu\n", nr_context_switches(), (unsigned long long)boottime.tv_sec, total_forks, nr_running(), nr_iowait()); seq_put_decimal_ull(p, "softirq ", (unsigned long long)sum_softirq); for (i = 0; i < NR_SOFTIRQS; i++) seq_put_decimal_ull(p, " ", per_softirq_sums[i]); seq_putc(p, '\n'); return 0; }
-
-
最后看一下上面这些函数是如何完成调用的;
-
首先是操作系统启动,在内核中注册了来统计CPU状态的结构体;
-
接着在每一个tick完成时的时钟中断里,统计了CPU的使用情况;
-
然后在程序读取时,将这些信息更新到/proc/stat文件中;
-
最后,top命令再开始利用这些数据完成计算CPU的利用率;
t o t a l t i m e = u s e r t i m e + s y s t e m t i m e + n i c e t i m e + i d e l t i m e + i o w a i t t i m e + h i t i m e + s i t i m e + s e a l t t i m e + g u e s t t i m e + g n i c e t i m e total_{time}=user_{time}+system_{time}+nice_{time}+idel_{time}+iowait_{time}+hi_{time}+si_{time}+sealt_{time}+guest_{time}+gnice_{time} totaltime=usertime+systemtime+nicetime+ideltime+iowaittime+hitime+sitime+sealttime+guesttime+gnicetime
R a t e C P U = u s e r t i m e t o t a l t i m e Rate_{CPU}=\frac{user_{time}}{total_{time}} RateCPU=totaltimeusertime
-
-
-
注意,这里的CPU统计和我们在调度过程中见到的update_curr不一样,两者更新的数据结构不同,后者是来更新红黑树上的时间,进而达到对进程排序的目的
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xhZYsRGX-1630926489500)(https://raw.githubusercontent.com/Richardhongyu/pic/main/20210815081407.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cxcsOihC-1630926489504)(https://raw.githubusercontent.com/Richardhongyu/pic/main/20210815082141.png)]
- 看到这里就应该能明白我们一开始提出的CFS在文档中说,它的调度是正常的原因了,它不是只在tick间隔更新CPU时间。
-
-
上下文切换统计
-
用上下文解决这个问题的好处与缺点
- 受到CFS的启发,一个很自然的想法是通过在上下文切换的时候完成统计工作
-
相关的编译选项
-
我们需要通过重新编译内核的方式,让进程在上下文切换时统计时间,相关内核选项有三类;
-
第一个是时钟计时的选项;
-
需要调节这个选项,给CPU时间统计方式做铺垫;
-
选项可选为
-
HZ_PERIODIC 周期性中断
config HZ_PERIODIC bool "Periodic timer ticks (constant rate, no dynticks)" help This option keeps the tick running periodically at a constant rate, even when the CPU doesn't need it. -
NO_HZ_IDLE 在CPU处于空闲状态时不产生不必要的周期性时钟中断
config NO_HZ_IDLE bool "Idle dynticks system (tickless idle)" depends on !ARCH_USES_GETTIMEOFFSET && GENERIC_CLOCKEVENTS select NO_HZ_COMMON help This option enables a tickless idle system: timer interrupts will only trigger on an as-needed basis when the system is idle. This is usually interesting for energy saving. Most of the time you want to say Y here.- 注意:这种情况下需要保证启动参数“nohz=on”;
-
NO_HZ_FULL 完全无周期性时钟中断
config NO_HZ_FULL bool "Full dynticks system (tickless)" # NO_HZ_COMMON dependency depends on !ARCH_USES_GETTIMEOFFSET && GENERIC_CLOCKEVENTS # We need at least one periodic CPU for timekeeping depends on SMP depends on HAVE_CONTEXT_TRACKING # VIRT_CPU_ACCOUNTING_GEN dependency depends on HAVE_VIRT_CPU_ACCOUNTING_GEN select NO_HZ_COMMON select RCU_NOCB_CPU select VIRT_CPU_ACCOUNTING_GEN select IRQ_WORK select CPU_ISOLATION help Adaptively try to shutdown the tick whenever possible, even when the CPU is running tasks. Typically this requires running a single task on the CPU. Chances for running tickless are maximized when the task mostly runs in userspace and has few kernel activity. You need to fill up the nohz_full boot parameter with the desired range of dynticks CPUs. This is implemented at the expense of some overhead in user <-> kernel transitions: syscalls, exceptions and interrupts. Even when it's dynamically off. Say N.- 注意:需要设置“nohz_full”来控制各个CPU的计时情况,不能将所有的CPU设置为完全无周期性时钟中断;
-
-
-
第二个是CPU时间统计方式;
-
选项可选为
-
TICK_CPU_ACCOUNTING 配合tick进行计时
config TICK_CPU_ACCOUNTING bool "Simple tick based cputime accounting" depends on !S390 && !NO_HZ_FULL help This is the basic tick based cputime accounting that maintains statistics about user, system and idle time spent on per jiffies granularity. If unsure, say Y. -
VIRT_CPU_ACCOUNTING_NATIVE 读取了CPU计数器进行统计
config VIRT_CPU_ACCOUNTING_NATIVE bool "Deterministic task and CPU time accounting" depends on HAVE_VIRT_CPU_ACCOUNTING && !NO_HZ_FULL select VIRT_CPU_ACCOUNTING help Select this option to enable more accurate task and CPU time accounting. This is done by reading a CPU counter on each kernel entry and exit and on transitions within the kernel between system, softirq and hardirq state, so there is a small performance impact. In the case of s390 or IBM POWER > 5, this also enables accounting of stolen time on logically-partitioned systems. -
VIRT_CPU_ACCOUNTING_GEN 利用上下文切换进行统计
config VIRT_CPU_ACCOUNTING_GEN bool "Full dynticks CPU time accounting" depends on HAVE_CONTEXT_TRACKING depends on HAVE_VIRT_CPU_ACCOUNTING_GEN depends on GENERIC_CLOCKEVENTS select VIRT_CPU_ACCOUNTING select CONTEXT_TRACKING help Select this option to enable task and CPU time accounting on full dynticks systems. This accounting is implemented by watching every kernel-user boundaries using the context tracking subsystem. The accounting is thus performed at the expense of some significant overhead. For now this is only useful if you are working on the full dynticks subsystem development. If unsure, say N.
-
-
这里给出这些选项在内核编译时的说明;
-
-
第三个是中断计时;
-
IRQ_TIME_ACCOUNTING
config IRQ_TIME_ACCOUNTING bool "Fine granularity task level IRQ time accounting" depends on HAVE_IRQ_TIME_ACCOUNTING && !VIRT_CPU_ACCOUNTING_NATIVE help Select this option to enable fine granularity task irq time accounting. This is done by reading a timestamp on each transitions between softirq and hardirq state, so there can be a small performance impact. If in doubt, say N here. -
这里给出这个选项在内核编译时的说明;
-
可以通过打开这个选项来统计中断的时间,原理是利用中断前后的时间戳来进行统计;
-
-
-
统计过程
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZKW1K2ZK-1630926489507)(https://raw.githubusercontent.com/Richardhongyu/pic/main/20210815094227.png)]
-
我们从上下文切换切入,从这个content_switch函数来看这件事情
-
首先是在程序调度过程中,调用了context_switch函数
/* * context_switch - switch to the new MM and the new thread's register state. */ static __always_inline struct rq * context_switch(struct rq *rq, struct task_struct *prev, struct task_struct *next, struct rq_flags *rf) { prepare_task_switch(rq, prev, next); /* * For paravirt, this is coupled with an exit in switch_to to * combine the page table reload and the switch backend into * one hypercall. */ arch_start_context_switch(prev); /* * kernel -> kernel lazy + transfer active * user -> kernel lazy + mmgrab() active * * kernel -> user switch + mmdrop() active * user -> user switch */ if (!next->mm) { // to kernel enter_lazy_tlb(prev->active_mm, next); next->active_mm = prev->active_mm; if (prev->mm) // from user mmgrab(prev->active_mm); else prev->active_mm = NULL; } else { // to user membarrier_switch_mm(rq, prev->active_mm, next->mm); /* * sys_membarrier() requires an smp_mb() between setting * rq->curr / membarrier_switch_mm() and returning to userspace. * * The below provides this either through switch_mm(), or in * case 'prev->active_mm == next->mm' through * finish_task_switch()'s mmdrop(). */ switch_mm_irqs_off(prev->active_mm, next->mm, next); if (!prev->mm) { // from kernel /* will mmdrop() in finish_task_switch(). */ rq->prev_mm = prev->active_mm; prev->active_mm = NULL; } } rq->clock_update_flags &= ~(RQCF_ACT_SKIP|RQCF_REQ_SKIP); prepare_lock_switch(rq, next, rf); /* Here we just switch the register state and the stack. */ switch_to(prev, next, prev); barrier(); return finish_task_switch(prev); } -
可以看到context_switch中的结尾,有一个finish_task_switch函数来给上下文切换打扫战场
/** * finish_task_switch - clean up after a task-switch * @prev: the thread we just switched away from. * * finish_task_switch must be called after the context switch, paired * with a prepare_task_switch call before the context switch. * finish_task_switch will reconcile locking set up by prepare_task_switch, * and do any other architecture-specific cleanup actions. * * Note that we may have delayed dropping an mm in context_switch(). If * so, we finish that here outside of the runqueue lock. (Doing it * with the lock held can cause deadlocks; see schedule() for * details.) * * The context switch have flipped the stack from under us and restored the * local variables which were saved when this task called schedule() in the * past. prev == current is still correct but we need to recalculate this_rq * because prev may have moved to another CPU. */ static struct rq *finish_task_switch(struct task_struct *prev) __releases(rq->lock) { struct rq *rq = this_rq(); struct mm_struct *mm = rq->prev_mm; long prev_state; /* * The previous task will have left us with a preempt_count of 2 * because it left us after: * * schedule() * preempt_disable(); // 1 * __schedule() * raw_spin_lock_irq(&rq->lock) // 2 * * Also, see FORK_PREEMPT_COUNT. */ if (WARN_ONCE(preempt_count() != 2*PREEMPT_DISABLE_OFFSET, "corrupted preempt_count: %s/%d/0x%x\n", current->comm, current->pid, preempt_count())) preempt_count_set(FORK_PREEMPT_COUNT); rq->prev_mm = NULL; /* * A task struct has one reference for the use as "current". * If a task dies, then it sets TASK_DEAD in tsk->state and calls * schedule one last time. The schedule call will never return, and * the scheduled task must drop that reference. * * We must observe prev->state before clearing prev->on_cpu (in * finish_task), otherwise a concurrent wakeup can get prev * running on another CPU and we could rave with its RUNNING -> DEAD * transition, resulting in a double drop. */ prev_state = prev->state; vtime_task_switch(prev); perf_event_task_sched_in(prev, current); finish_task(prev); finish_lock_switch(rq); finish_arch_post_lock_switch(); kcov_finish_switch(current); fire_sched_in_preempt_notifiers(current); /* * When switching through a kernel thread, the loop in * membarrier_{private,global}_expedited() may have observed that * kernel thread and not issued an IPI. It is therefore possible to * schedule between user->kernel->user threads without passing though * switch_mm(). Membarrier requires a barrier after storing to * rq->curr, before returning to userspace, so provide them here: * * - a full memory barrier for {PRIVATE,GLOBAL}_EXPEDITED, implicitly * provided by mmdrop(), * - a sync_core for SYNC_CORE. */ if (mm) { membarrier_mm_sync_core_before_usermode(mm); mmdrop(mm); } if (unlikely(prev_state == TASK_DEAD)) { if (prev->sched_class->task_dead) prev->sched_class->task_dead(prev); /* * Remove function-return probe instances associated with this * task and put them back on the free list. */ kprobe_flush_task(prev); /* Task is done with its stack. */ put_task_stack(prev); put_task_struct_rcu_user(prev); } tick_nohz_task_switch(); return rq; } -
接下来就非常有意思,finish_task_switch调用了一个vtime_task_switch函数,这个函数的定义根据编译选项的不同而不同,在这里我将会分别阐述在不同的预编译选项下,如何完成统计工作,另外由于这个相关的代码内容实在是太长了,这里列出头文件中的声明部分,根据函数调用情况再看具体的函数定义
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NeVx5G9z-1630926489510)(https://raw.githubusercontent.com/Richardhongyu/pic/main/20210815100548.png)]
#if defined(CONFIG_VIRT_CPU_ACCOUNTING_NATIVE) static inline bool vtime_accounting_enabled_this_cpu(void) { return true; } extern void vtime_task_switch(struct task_struct *prev); #elif defined(CONFIG_VIRT_CPU_ACCOUNTING_GEN) /* * Checks if vtime is enabled on some CPU. Cputime readers want to be careful * in that case and compute the tickless cputime. * For now vtime state is tied to context tracking. We might want to decouple * those later if necessary. */ static inline bool vtime_accounting_enabled(void) { return context_tracking_enabled(); } static inline bool vtime_accounting_enabled_cpu(int cpu) { return context_tracking_enabled_cpu(cpu); } static inline bool vtime_accounting_enabled_this_cpu(void) { return context_tracking_enabled_this_cpu(); } extern void vtime_task_switch_generic(struct task_struct *prev); static inline void vtime_task_switch(struct task_struct *prev) { if (vtime_accounting_enabled_this_cpu()) vtime_task_switch_generic(prev); } #else /* !CONFIG_VIRT_CPU_ACCOUNTING */ static inline bool vtime_accounting_enabled_cpu(int cpu) {return false; } static inline bool vtime_accounting_enabled_this_cpu(void) { return false; } static inline void vtime_task_switch(struct task_struct *prev) { } #endif /* * Common vtime APIs */ #ifdef CONFIG_VIRT_CPU_ACCOUNTING extern void vtime_account_kernel(struct task_struct *tsk); extern void vtime_account_idle(struct task_struct *tsk); #else /* !CONFIG_VIRT_CPU_ACCOUNTING */ static inline void vtime_account_kernel(struct task_struct *tsk) { } #endif /* !CONFIG_VIRT_CPU_ACCOUNTING */ #ifdef CONFIG_VIRT_CPU_ACCOUNTING_GEN extern void arch_vtime_task_switch(struct task_struct *tsk); extern void vtime_user_enter(struct task_struct *tsk); extern void vtime_user_exit(struct task_struct *tsk); extern void vtime_guest_enter(struct task_struct *tsk); extern void vtime_guest_exit(struct task_struct *tsk); extern void vtime_init_idle(struct task_struct *tsk, int cpu); #else /* !CONFIG_VIRT_CPU_ACCOUNTING_GEN */ static inline void vtime_user_enter(struct task_struct *tsk) { } static inline void vtime_user_exit(struct task_struct *tsk) { } static inline void vtime_guest_enter(struct task_struct *tsk) { } static inline void vtime_guest_exit(struct task_struct *tsk) { } static inline void vtime_init_idle(struct task_struct *tsk, int cpu) { } #endif #ifdef CONFIG_VIRT_CPU_ACCOUNTING_NATIVE extern void vtime_account_irq_enter(struct task_struct *tsk); static inline void vtime_account_irq_exit(struct task_struct *tsk) { /* On hard|softirq exit we always account to hard|softirq cputime */ vtime_account_kernel(tsk); } extern void vtime_flush(struct task_struct *tsk); #else /* !CONFIG_VIRT_CPU_ACCOUNTING_NATIVE */ static inline void vtime_account_irq_enter(struct task_struct *tsk) { } static inline void vtime_account_irq_exit(struct task_struct *tsk) { } static inline void vtime_flush(struct task_struct *tsk) { } #endif-
开启了CONFIG_VIRT_CPU_ACCOUNTING选项后,我们可以看到这个vtime_task_switch函数啥也不做,也就是统计工作还是交由tick阶段的函数完成,这里只是一个幌子
-
而开启了CONFIG_VIRT_CPU_ACCOUNTING_NATIVE选项后,我们发现这个vtime_task_switch函数大有所为
void vtime_task_switch(struct task_struct *prev) { if (is_idle_task(prev)) vtime_account_idle(prev); else vtime_account_kernel(prev); vtime_flush(prev); arch_vtime_task_switch(prev); }-
进一步探讨vtime_account_idle函数
//注意这个函数的定义在https://elixir.bootlin.com/linux/v5.10/source/arch/ia64/kernel/time.c#L152 void vtime_account_idle(struct task_struct *tsk) { struct thread_info *ti = task_thread_info(tsk); ti->idle_time += vtime_delta(tsk); } -
进一步探讨vtime_account_kernel函数
//注意这个函数的定义在https://elixir.bootlin.com/linux/v5.10/source/arch/ia64/kernel/time.c#L136 void vtime_account_kernel(struct task_struct *tsk) { struct thread_info *ti = task_thread_info(tsk); __u64 stime = vtime_delta(tsk); if ((tsk->flags & PF_VCPU) && !irq_count()) ti->gtime += stime; else if (hardirq_count()) ti->hardirq_time += stime; else if (in_serving_softirq()) ti->softirq_time += stime; else ti->stime += stime; } -
这里user_time暂时没有找到在哪里,不过不影响大体结论,等我再寻找一下
-
-
而开启了CONFIG_VIRT_CPU_ACCOUNTING_GEN选项后,我们发现了
static inline void vtime_task_switch(struct task_struct *prev) { if (vtime_accounting_enabled_this_cpu()) vtime_task_switch_generic(prev); }void vtime_task_switch_generic(struct task_struct *prev) { struct vtime *vtime = &prev->vtime; write_seqcount_begin(&vtime->seqcount); if (vtime->state == VTIME_IDLE) vtime_account_idle(prev); else __vtime_account_kernel(prev, vtime); vtime->state = VTIME_INACTIVE; vtime->cpu = -1; write_seqcount_end(&vtime->seqcount); vtime = ¤t->vtime; write_seqcount_begin(&vtime->seqcount); if (is_idle_task(current)) vtime->state = VTIME_IDLE; else if (current->flags & PF_VCPU) vtime->state = VTIME_GUEST; else vtime->state = VTIME_SYS; vtime->starttime = sched_clock(); vtime->cpu = smp_processor_id(); write_seqcount_end(&vtime->seqcount); }-
首先看一下idel_time
void vtime_account_idle(struct task_struct *tsk) { account_idle_time(get_vtime_delta(&tsk->vtime)); }/* * Account for idle time. * @cputime: the CPU time spent in idle wait */ void account_idle_time(u64 cputime) { u64 *cpustat = kcpustat_this_cpu->cpustat; struct rq *rq = this_rq(); if (atomic_read(&rq->nr_iowait) > 0) cpustat[CPUTIME_IOWAIT] += cputime; else cpustat[CPUTIME_IDLE] += cputime; }static u64 get_vtime_delta(struct vtime *vtime) { u64 delta = vtime_delta(vtime); u64 other; /* * Unlike tick based timing, vtime based timing never has lost * ticks, and no need for steal time accounting to make up for * lost ticks. Vtime accounts a rounded version of actual * elapsed time. Limit account_other_time to prevent rounding * errors from causing elapsed vtime to go negative. */ other = account_other_time(delta); WARN_ON_ONCE(vtime->state == VTIME_INACTIVE); vtime->starttime += delta; return delta - other; } -
这个account_idle_time和我们在tick统计的情况下,统计idel时间用到的函数是一样的,只是传来的参数不一致
-
然后看一下kernel_time
static void __vtime_account_kernel(struct task_struct *tsk, struct vtime *vtime) { /* We might have scheduled out from guest path */ if (vtime->state == VTIME_GUEST) vtime_account_guest(tsk, vtime); else vtime_account_system(tsk, vtime); } -
可以看到这里追踪了vtime_account_guest和vtime_account_system的时间
-
-
-
-
如何开启上下文切换统计
- 在openEuler的内核编译选项中,我们实际是沿用了部分centos的选项,默认开启了利用上下文统计,所以无需额外的操作
-
如何将上下文统计的时间输出到/proc/stat
-
从代码角度
- 首先看代码
#ifdef CONFIG_VIRT_CPU_ACCOUNTING_GEN extern u64 kcpustat_field(struct kernel_cpustat *kcpustat, enum cpu_usage_stat usage, int cpu); extern void kcpustat_cpu_fetch(struct kernel_cpustat *dst, int cpu); #else static inline u64 kcpustat_field(struct kernel_cpustat *kcpustat, enum cpu_usage_stat usage, int cpu) { return kcpustat->cpustat[usage]; } static inline void kcpustat_cpu_fetch(struct kernel_cpustat *dst, int cpu) { *dst = kcpustat_cpu(cpu); } #endif-
关键问题在kcpustat_cpu_fetch上,从这个函数追踪到代码
void kcpustat_cpu_fetch(struct kernel_cpustat *dst, int cpu) { const struct kernel_cpustat *src = &kcpustat_cpu(cpu); struct rq *rq; int err; if (!vtime_accounting_enabled_cpu(cpu)) { *dst = *src; return; } rq = cpu_rq(cpu); for (;;) { struct task_struct *curr; rcu_read_lock(); curr = rcu_dereference(rq->curr); if (WARN_ON_ONCE(!curr)) { rcu_read_unlock(); *dst = *src; return; } err = kcpustat_cpu_fetch_vtime(dst, src, curr, cpu); rcu_read_unlock(); if (!err) return; cpu_relax(); } } -
static int kcpustat_cpu_fetch_vtime(struct kernel_cpustat *dst, const struct kernel_cpustat *src, struct task_struct *tsk, int cpu) { struct vtime *vtime = &tsk->vtime; unsigned int seq; do { u64 *cpustat; u64 delta; int state; seq = read_seqcount_begin(&vtime->seqcount); state = vtime_state_fetch(vtime, cpu); if (state < 0) return state; *dst = *src; cpustat = dst->cpustat; /* Task is sleeping, dead or idle, nothing to add */ if (state < VTIME_SYS) continue; delta = vtime_delta(vtime); /* * Task runs either in user (including guest) or kernel space, * add pending nohz time to the right place. */ if (state == VTIME_SYS) { cpustat[CPUTIME_SYSTEM] += vtime->stime + delta; } else if (state == VTIME_USER) { if (task_nice(tsk) > 0) cpustat[CPUTIME_NICE] += vtime->utime + delta; else cpustat[CPUTIME_USER] += vtime->utime + delta; } else { WARN_ON_ONCE(state != VTIME_GUEST); if (task_nice(tsk) > 0) { cpustat[CPUTIME_GUEST_NICE] += vtime->gtime + delta; cpustat[CPUTIME_NICE] += vtime->gtime + delta; } else { cpustat[CPUTIME_GUEST] += vtime->gtime + delta; cpustat[CPUTIME_USER] += vtime->gtime + delta; } } } while (read_seqcount_retry(&vtime->seqcount, seq)); return 0; }
-
解析
-
在更新时间的时候,是从上下文统计的更新了vtime;
-
而输出时间的时候,则是按照上面的函数调用路径
-
-
-
参考文献
[1] https://www.jianshu.com/p/d7e18630e6a7
[2] https://lrita.github.io/images/posts/linux/Linux_CPU_Usage_Analysis.pdf
[3] https://www.kernel.org/doc/Documentation/cpu-load.txt
[4] https://www.kernel.org/doc/html/latest/scheduler/sched-stats.html?highlight=proc%20stat#proc-pid-schedstat

















 1607
1607

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









