







操作系统-进程
Java后端各科最全八股自用整理,获取方式见:
协程和线程的区别以及优势
线程,进程,协程的区别
进程同步方式
进程同步就是控制多个进程按一定顺序执行,而进程间通信(IPC)是在进程间传输信息。它们之间的关系是:进程通信是一种手段,而进程同步是一种目的,为了能够达到进程同步的目的,需要让进程进行通信,传输一些进程同步所需要的信息。
临界区
临界区是一段代码,在临界区内进程将访问临界资源。任何时候最多只有一个进程可以进入临界区,也就是说,临界区具有排他性。所以,为了互斥访问临界资源,每个进程在进入临界区之前,需要先进行检查。
互斥量
就是使用一个互斥的变量来直接制约多个进程,每个进程只有拥有这个变量才具有访问公共资源的权限,因为互斥量只有一个,所以能保证资源的正确访问。
信号量
https://developer.aliyun.com/article/416789
信号量(Semaphore)是一个整型变量,可以对其执行自增和自减操作,自减操作通常也叫做P操作,自增操作也称为V操作。这两个操作需要被设计成原语,是不可分割,通常的做法是在执行这些操作的时候屏蔽中断。进程使用这两个操作进行同步。
对于P操作,若sem减 1 后仍>=0,则请求的进程继续执行;若sem减 1 后小于零,则进程被阻塞后进入与该信号相对应的队列中,然后转进程调度。
对于V操作,若相加结果>0,则请求的进程继续执行;若相加结果小于等于零,则从该信号的等待队列中唤醒一个等待进程,然后再返回原进程继续执行或转进程调度。
管程
管程使用的是面向对象思想,将表示共享资源的数据结构还有相关的操作,包括同步机制,都集中并封装到一起。所有进程都只能通过管程间接访问临界资源,而管程只允许一个进程进入并执行操作,从而实现进程互斥。
管程中设置了多个条件变量,表示多个进程被阻塞或挂起的条件。对条件变量执行 wait() 操作会导致调用进程阻塞,把管程让出来给另一个进程持有。signal() 操作用于唤醒被阻塞的进程。
管程有一个重要特性,就是在一个时刻只能有一个进程使用管程。进程在无法继续执行的时候不能一直占用管程,否则其它进程永远不能使用管程。
进程间通信方式?(面试官说有十多种。。。我迷惑了)
找了一下,进程间通信大概有下面这些类别:(参考《Linux/UNIX系统编程手册》 https://book.douban.com/subject/25809330/ )
6种
低级进程通信
- 信号(Signal):从一个进程发送到另一个进程的系统消息,通常不用于传输数据,而是用来提醒进程一个事件已经发生。
- 信号量(Semaphores):信号量是一个计数器,可以用来控制多个进程对共享资源的访问。常作为一种锁机制,防止某进程正在访问共享资源时,其他进程也访问该资源。主要用于进程间同步。
信号量是一种特殊的变量,对它的操作都是原子的,有两种操作:V(signal())和 P(wait())。V 操作会增加信号量 S 的数值,P 操作会减少它。
前面说到的通信机制,都是工作于同一台主机,如果要与不同主机的进程间通信,那么就需要 Socket 通信了。 - 套接字(Sockets) :主要用于客户端和服务器之间的通信。与其他通信机制不同的是,它可用于不同主机间的进程通信。
套接字是支持 TCP/IP 网络通信的基本操作单元,可以在不同主机之间的进程进行双向通信。简单的说就是通信的两方的一种约定,用套接字中的相关函数来完成通信过程。
高级进程通信
- 共享内存(Shared memory) :使得多个进程访问同一块内存空间,不同进程可以及时看到其他进程对共享内存中数据的更新。这种方式需要依靠某种同步操作,如互斥锁和信号量等。可以说这是最有用的进程间通信方式。
共享内存可以说是最有用的进程间通信方式,也是最快的 IPC 形式。
优点是简单且高效,缺点是存在并发问题。 - 消息队列(Message Queuing) :消息队列是一个消息的链表,保存在内核中。消息队列中的每个消息都是一个数据块,具有特定的格式。操作系统中可以存在多个消息队列,每个消息队列有唯一的 key,称为消息队列标识符。
消息队列允许一个或多个进程向它写入和读取。消息的发送者和接收者不需要同时与消息队列交互。消息会保存在队列中,直到接收者取回它。也就是说,消息队列是异步的,但这也造成了一个缺点,就是接收者必须轮询消息队列,才能收到最近的消息。
消息队列克服了信号传递信息少、管道只能承载无格式字节流以及缓冲区大小受限等缺点。和信号相比,消息队列能够传递更多的信息。与管道相比,消息队列提供了有格式的数据,但消息队列仍然有大小限制。
消息队列和管道相比,相同点在于二者都是通过发送-接收的方式进行通信,并且数据都有最大长度限制。不同点在于消息队列的数据是有格式的,并且取消息进程可以选择接收特定类型的消息,而不是像管道中那样默认全部接收。管道和消息队列的通信数据都是先进先出的原则。 - 管道:管道是一种半双工的通信方式,数据只能单向流动,上游进程往管道中写入数据,下游进程从管道中接收数据。如果想实现双方通信,那么需要建立两个管道。
管道适合于传输大量信息。管道发送的内容是以字节为单位的,没有格式的字节流。
线程间通信
线程间的通信目的主要是用于线程同步,所以线程没有像进程通信中的用于数据交换的通信机制。
- 锁机制:包括互斥锁、读写锁、条件变量
互斥锁提供了以排他方式防止数据结构被并发修改的方法。
读写锁允许多个线程同时读共享数据,而对写操作是互斥的。
条件变量可以以原子的方式阻塞进程,直到某个特定条件为真为止。对条件的测试是在互斥锁的保护下进行的。条件变量始终与互斥锁一起使用。while+if+volatile变量 - 信号量机制(Semaphore):包括无名线程信号量和命名线程信号量
- 信号机制(Signal):类似进程间的信号处理
① 锁机制:互斥锁、条件变量
- 互斥锁确保同一时间只能有一个线程访问共享资源。当锁被占用时试图对其加锁的线程都进入阻塞状态。当锁释放时哪个等待线程能获得该锁取决于内核的调度。
- 条件变量始终与互斥锁一起使用。互斥锁用来保证对临界区的互斥进入,而条件变量则用于线程的长期等待,直至等待的资源成为可用的资源。
② 信号量机制(Semaphore)
信号量实际上是一个非负的整数计数器,用来实现对公共资源的控制。在公共资源增加的时候,信号量就增加;公共资源减少的时候,信号量就减少;只有当信号量的值大于0的时候,才能访问信号量所代表的公共资源。
https://blog.51cto.com/u_16269508/7623695
6.什么是条件变量?举例条件变量。
https://cloud.tencent.com/developer/article/1755454
线程可以使用条件变量,来等待一个条件变成真。
条件变量是一个显式队列,当某些执行状态(即条件,condition)不满足时,线程可以把自己加入队列,等待该条件。当其他线程改变了上述状态时,就可以通过在该条件上发送信号唤醒队列中的等待线程,让它们继续执行。
2. 共享内存实现方式
为了实现在多个进程间高效的数据通信,linux内核特地留下一块内存区,该内存区能够被需要的进程映射到自身的内存空间。因此,进程便能够直接对这块内存区进行读写操作。

共享内存的实现较为简单,一共分为两个步骤:
- 创建共享内存。通过函数shmget()从内存中获取一块共享内存区域,该函数返回值为共享内存的ID。
- 映射共享内存。通过函数shmat()将上一步获取的共享内存映射到具体的内存空间。
NOTE:先创建共享内存,再将共享内存映射到每个进程中。
线程调度
进程栈和线程栈的区别?
4.fork一个子进程背后的指令操作。
fork函数的底层实现原理
https://www.dounaite.com/article/6276a476ac359fc91322c39f.html
以当前进程作为父进程创建出一个新的子进程,并且将父进程的所有资源拷贝给子进程,这样子进程作为父进程的一个副本存在。父子进程几乎时完全相同的,但也有不同的如父子进程ID不同。
当fork系统调用成功时,它会返回两个值:一个是0,另一个是所创建的新的子进程的ID(>0)。当fork成功调用后此时有两个数据相同的父子进程,我们可以通过fork的返回值来判断接下来程序是在执行父进程还是子进程。
id==0:执行子进程
id>0:在父进程中执行
id<0:fork函数调用失败
那么fork函数为什么是一次调用,却返回了两次呢?
当程序执行到下面的语句: pid=fork();
由于在复制时复制了父进程的堆栈段,所以两个进程都停留在fork函数中,等待返回。因此fork函数会返回两次,一次是在父进程中返回,另一次是在子进程中返回,这两次的返回值是不一样的。
fork调用的一个奇妙之处就是它仅仅被调用一次,却能够返回两次,它可能有三种不同的返回值:
1)在父进程中,fork返回新创建子进程的进程ID;
2)在子进程中,fork返回0;
3)如果出现错误,fork返回一个负值。
我们可以通过fork返回的值来判断当前进程是子进程还是父进程。通俗的解释,可以这样看待:“其实就相当于链表,进程形成了链表,父进程的fork函数返回的值指向子进程的进程id, 因为子进程没有子进程,所以其fork函数返回的值为0。
调用fork之后,数据、堆、栈有两份,代码仍然为一份但是这个代码段成为两个进程的共享代码段都从fork函数中返回。当父子进程有一个想要修改数据或者堆栈时,两个进程真正分裂。
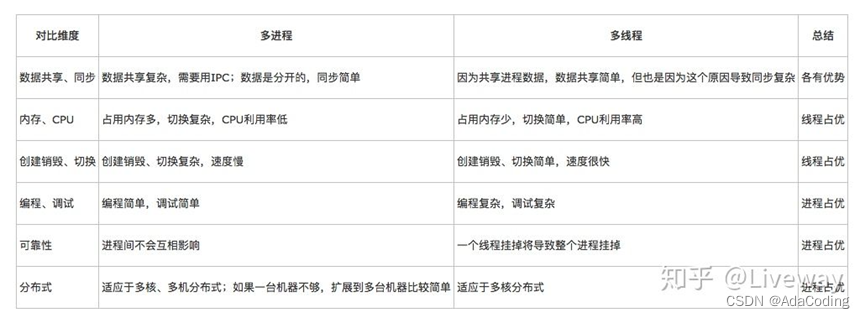
什么时候用多线程,什么时候用多进程;
多线程:io密集型 (读取网络,读取文件)
多进程:计算 cpu耗用的多 (一个程序就可以理解为一个进程 )
频繁修改:需要频繁创建和销毁的优先使用多线程
计算量大:需要大量计算的优先使用多线程 因为需要消耗大量CPU资源且切换频繁,所以多线程好一 点
相关性:任务间相关性比较强的用多线程,相关性比较弱的用多进程。因为线程之间的数据共享和同 步比较简单。
多分布:可能要扩展到多机分布的用多进程,多核分布的用多线程。
但是实际中更常见的是进程加线程的结合方式,并不是非此即彼的。
临界区
(临界资源是一次仅允许一个进程使用的共享资源)
每个进程中访问临界资源的那段代码称为临界区(Critical Section)。 每次只准许一个进程进入临界区,进入后不允许其他进程进入。 不论是硬件临界资源,还是软件临界资源,多个进程必须互斥地对它进行访问。
更多后端全部八股点击👉👉【闲鱼】https://m.tb.cn/h.5yHpgkY?tk=O8bhWpn1NBD CZ8908 「我在闲鱼发布了【京985计算机硕士自用后端八股文出售,不同于市面上的几块钱八】」
点击链接直接打开
Java后端各科最全八股自用整理,获取方式见:
整理不易,关注和收藏后拿走!
欢迎专注我的公众号:AdaCoding

















 4585
4585











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









