







下载安装 vscode
https://blog.csdn.net/weixin_41192489/article/details/125647248
常用快捷键
- Ctrl + i 唤起代码提示
Ctrl+,打开设置- Ctrl + G 输入行号—— 定位到指定行
- Ctrl + P 输入文件路径/文件名关键字 —— 打开指定文件
- 按Ctrl不放,依次按 K ,数字 0 —— 折叠所有区域代码
- 按Ctrl不放,依次按 K ,J —— 展开所有区域代码
同步设置
用于在不同设备上都能立马获得设置(如安装的插件等)。
登录 vscode 的账号(推荐通过 Microsoft 账号登录) ,开启同步
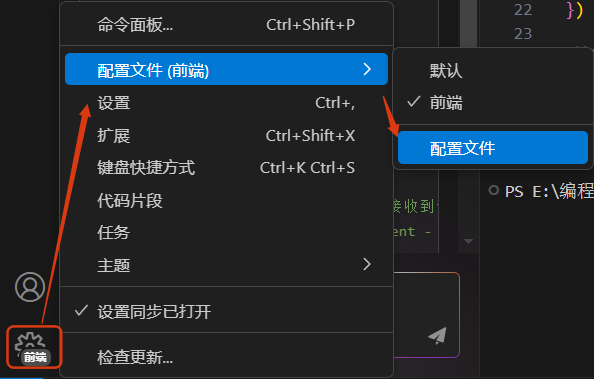
新建配置
可创建一个专门针对前端的配置
多点同时编辑
按住 Alt ,点击需要同时编辑的地方

删除空行
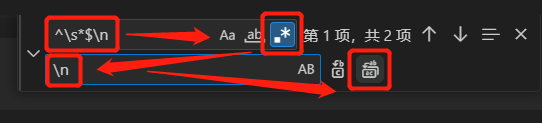
Ctrl+h弹出搜索框- 输入^\s*(?=\r?$)\n
- 点击全部替换
多行空行变单行空行
Ctrl + F 搜索
^\s*$\n
删除所有空行
Ctrl + F 搜索
^\s*$\n

保存时自动格式化
左下角点击”设置“按钮,搜索 Format On Save 勾选即可。
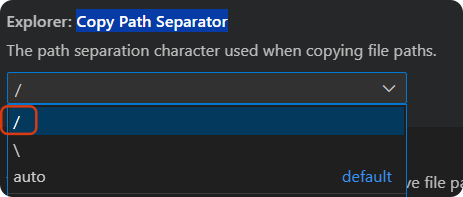
复制相对路径时,用 “/”
设置中搜索 Copy Path Separator
一个窗口打开多个项目
在工作区中,鼠标右键快捷菜单添加项目文件夹即可。
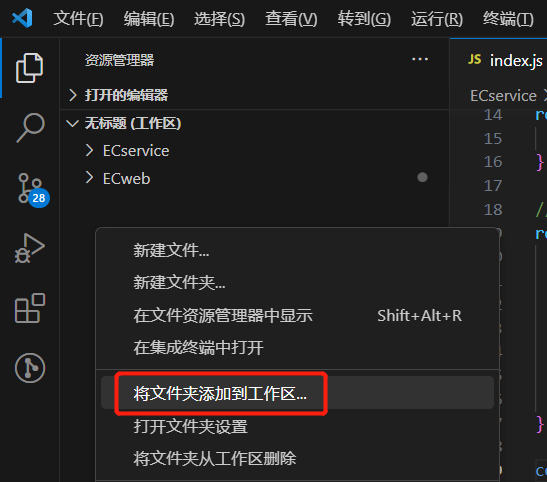
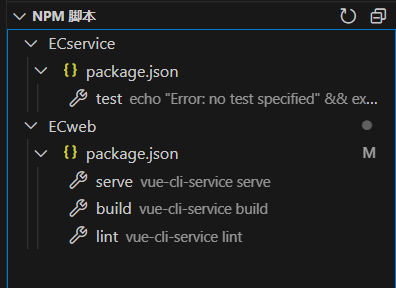
多项目时,NPM脚本中也会展示多项目的脚本
加载离线插件
在快捷启动按钮的属性中,修改目标为
"vscode快捷启动按钮的绝对路径\Code.exe" --extensions-dir "离线插件的绝对路径"
插件
前端推荐的插件
- Vue.js Extension Pack
- Vue Peek
- Vue 3 Snippets
- React Extension Pack
- Material Icon Theme 美化文件图标
https://blog.csdn.net/weixin_41192489/article/details/145188097 - Node Extension Pack
- Node.js Modules Intellisense
- Node.js Exec
- Git Extension Pack
- gitignore 生成 gitignore 文件
- Formatting Toggle 切换格式化插件
- Move TS
- TypeScript lmporter
- json2ts
Markdown Preview Enhanced 预览 .md 文件
https://blog.csdn.net/weixin_41192489/article/details/142565467
Notes 便捷做笔记
https://blog.csdn.net/weixin_41192489/article/details/142566397
Project Manager 项目管理
https://blog.csdn.net/weixin_41192489/article/details/142567409
Code Runner 运行代码
https://blog.csdn.net/weixin_41192489/article/details/142585212
Element Plus Helper 极速生成 Element 组件代码
https://blog.csdn.net/weixin_41192489/article/details/144542357
快捷日志 console helper
ctrl + l 打印变量日志
ctrl + shift + l 简单日志
ctrl + shift + d 删除所有日志
官方教程
https://marketplace.visualstudio.com/items?itemName=AT-9420.console-helper
打印日志 Turbo Console Log

Vue 2 语法库 Vue 2 Snippet
在vue文件中输入vue,可以自动生成优化后的vue模板



















 1234
1234

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











