







 本文探讨了多智能体强化学习的概念,相比于单智能体学习,多智能体能更高效地协同寻优。介绍了Actor-Critic和MADDPG算法在多智能体合作与竞争中的应用,并通过实例展示了MADDPG在复杂任务中的优越性。最后,讨论了ADOG在多智能体学习中的实现,特别是在量化投资策略中的应用。
本文探讨了多智能体强化学习的概念,相比于单智能体学习,多智能体能更高效地协同寻优。介绍了Actor-Critic和MADDPG算法在多智能体合作与竞争中的应用,并通过实例展示了MADDPG在复杂任务中的优越性。最后,讨论了ADOG在多智能体学习中的实现,特别是在量化投资策略中的应用。
1、多智能体强化学习
为什么需要多智能体(multi-agent)学习?
人工智能学习的梯度下降算法寻优方法,类似从山顶放置小球向下滚,希望寻找最快最好的路径,到达最低的谷底。
传统的单个智能体每次只使用一个小球,学习训练并使用一条路径,重复多次。
而多个智能体类似放置一群小球,同时分别学习训练并使用各自的多条路径,向下滚动过程中互相联系通信,相互告知自己的位置及状态,团队合作,引导共同到达最低的谷底。
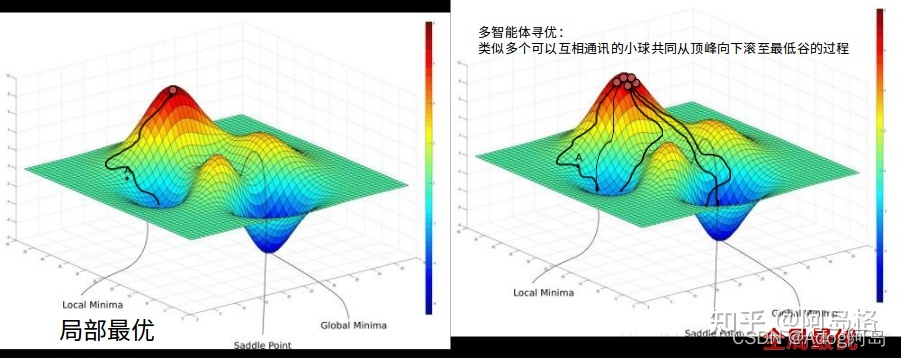
参见上图,多智能体(multi-agent)学习,相比单智能体:
- 多智能体智能体保持各自独特性和总体多样性 多智能体协同学习互通信息,效率更高,梯度下降速
- 更快 多智能体更易到达全局更优(上右图)
- 多智能体收敛性
2. Actor-Critic和MADDPG
Google DeepMind 提出Actor-Critic,多个agent各自训练,分别更新主结构中的参数,协同进行寻优
OpenAI: MADDPG(Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments)用于实现多智能体环境中的集中式学习和分散式执行,让智能体学习互相合作、互相竞争
用MADDPG算法训练四个红色圆点追逐两个绿色圆点,红色圆点已经学会彼此合作追逐同一个绿色圆点,以获得更高的奖励。与此同时,绿色圆点学会了“分头行动”,其中一个被红点追逐,其他的则试图接近蓝色圆点获得奖励,同时避开红色圆点。
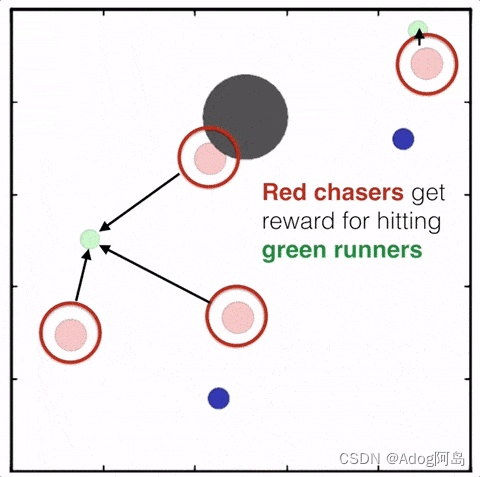
每个协同的智能体无需具备中间的评委官;它们根据观察以及对其他智能体行为的预测,做出动作。由于一个中心化的评委是为每个智能体独立学习的,这种方法也可以用来模拟多智能体之间的任意奖励结构,包括拥有相反奖励的对抗案例。
OpenAI研究人员在多任务上经过测试,结果均优于DDPG上的表现。在上图的动画中,从上至下可以看到:两个智能体试图前往特定位置,并且学习分散,向对手隐藏真实的目的地;一个智能体将位置信息传递给另一个智能体,其他三个智能体协调前往此处,并且不会碰撞。
使用MADDPG训练的红色圆点比用DDPG训练的智能体行为更复杂。在上面的动画中可以看到,用MADDPG技术训练的智能体和用DDP
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











