









1. Kafka
Kafka:一个分布式流处理平台,官网主要列举了三点:
1. 发布&订阅:类似于一个消息系统,读写流式的数据
2. 处理:编写可扩展的流处理应用程序,用于实时事件响应的场景
3. 存储:安全的将流式的数据存储在一个分布式,有副本备份,容错的集群
个人觉得比较拗口记不住,还是自己白话一下:
1. Kafka基于发布&订阅的消息模式,用于分布式系统间消息的传递,常被归类为消息中间件。
1.1 消息队列模式 点对点、发布&订阅 的定义是在JMS中被提出的,ActiveMQ完全基于该规范实现,但是Kafka并不是,Kafka只是实现了发布&订阅模式
1.2 kafka主题下若只有单一分区,个人认为这也是点对点模式的实现(只不过和点对点模式不同的是Kafka是持久化的,消息可以被再次消费)
2. Kafka主要负责消息的传递,它只是个搬运工
3. kafka支持持久化存储,可以有多个副本,高可用
kafka是一个分布式的、多分区、多副本、多订阅者的消息系统2. Kafka整体架构图

度娘来一张图,如图所示:
1. 生产者:生产消息,以push模式推送消息至kafka集群
2. 消费者:消费消息,以pull模式从kafka集群中拉取消息
3. Broker:kafka实例(一般一台机器即是一个Broker,但同一台机器可以设置不同的端口以及存储路径来启动多个实例)
------------------------------------------------------------------------------------------
1. Topic:主题,生产者发送消息的前提就是主题,消费者订阅主题下的消息进行消费
2. Partation:分区,一个主题下至少有一个分区,分区是消息在kafka上的物理存储,一个分区下消息是顺序存放的,但多个分区间则不是
3. Replicas:kafka对于消息是需要持久化的(至少一份),副本是为了提高kafka的高可用行的消息副本,防止作为leader的broker宕机
4. Offset:消费组对主题下的某一个分区消费到那儿的记录
------------------------------------------------------------------------------------------
1. Broker集群:kafka多个实例Broker组成
2. 消费组:一般启动多个消费者来提升业务处理能力,同一消费组中的消费组对于同一主题下的消息只能消费一次(当然若重启重洗设置offset另说)
3. Zookeeper集群:主要用于命名服务,维护生产者、消费者、Broker的节点信息,以及消费者的offset等元数据信息;选举Leader;以及消费组发生变化时的再均衡(rebalance)3. Kafka四大核心API

1. Producer API :生产者API,顾名思义为生产者提供接口
2. Consumer API :消费者API,顾名思义为消费者提供接口
3. Streams API :流式处理API,一个应用即作为生产者又作为消费者的情况。
4. Connector API :连接处理API,一个应用作为生产者或者作为消费者,将Kafka topics与已存在的应用程序或者数据系统连接进行读取或写入4. kafka交互
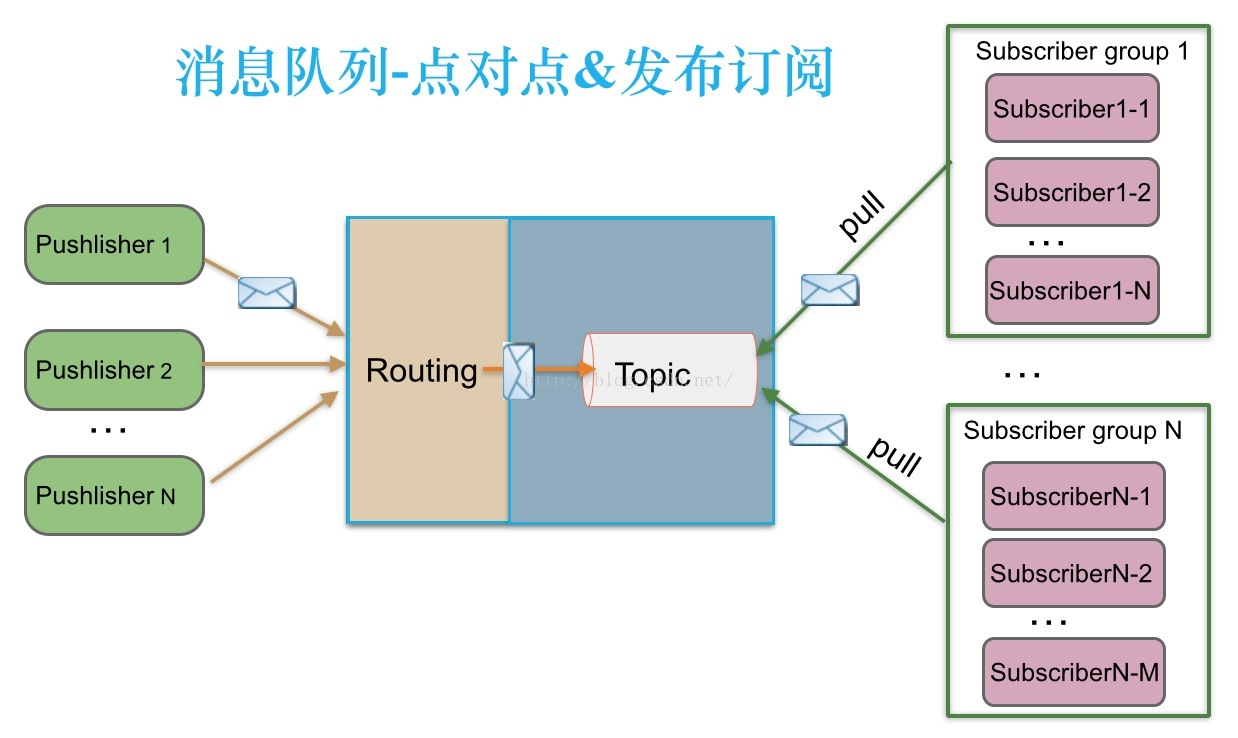
度娘来一张图
1. 与生产者交互:注意分区的3种路由策略(指定分区,自定义分区策略,kafka默认随机分配策略),推模式
2. 与消费者交互:消费端为拉模式,消费状态和订阅关系有消费端维护
2.1 一个topic可以有多个消费组,每个topic下的分区有消费组维护一个offset偏移量
2.2 消费组中消费者的数量不应该大于分区数,每个分区同一时间只能分配到一个消费者消费,若消费者过多,则多余的消费者接收不到消息,纯属浪费5.kafka应用场景
1. 消息中间件
2. 日志收集:作为日志聚合解决方案,收集分布式机器上的日志,并送往下游分布式存储中(如HDFS)
3. 行为分析:收集用户日志,分析用户行为,获取商业价值
4. 审计监控:实时汇总系统中的操作步骤等,对其进行集中式处理后,对关键操作或运维进行监控和审计(又可通过持久化特性,后期可用于离线分析)
5. 流处理
应用场景无外乎就是kafka的功能提现,根本就是发布&订阅,根据各个场景对消息进行集中式处理,以达到某种目的6. kafka组成
6.1 kafka主题
主题相关的有分区、副本:一个主题下可以有多个分区,每个分区又可以有多个副本
kafka主题被删除时时标记删除,只有在kafka重启时才会删除6.2 kafka分区
分区可以提升查询效率
分区中的消息是有序的,不同分区间的消息是无序的
消费组中的消费者应该小于等于分区数量(最好成比例关系)
分区中的数据都有相应的编号,消费组记录该分区中的offset偏移量(物理删除前,消费者可以自定义offset来选择如何消费,重复消费)
ISR:可用分区副本集合6.3 kafka副本
副本数量应小于等于Broker数量
副本以分区为单位
副本中Leader角色提供读写能力,其它Follower则不提供服务,只是提供高可用
副本因子数是包含本身的
副本因子不能放到同一个Broker中
副本间存在同步操作,Follwer会拉取Leader中新到的消息(启动一个专门的线程)6.4 Producer写数据

如图所示,生产者与Leader分区的交互:
1. 同步交互:从生产者线程池中找个与Leader分区对应的生产者,发送消息(一批)到Leader分区,Leader分区做完后续操作(Leader与Follower同步)同步返回消息给生产者
2. 异步交互:生产者将消息写入到本地阻塞队列中,一定时间后,发送线程发送消息(一批)到Leader分区,等Leader分区做完后异步通知
生产者何时拿到结果:
1. 等待所有副本确认,ACK=all(速度慢,若Leaer副本返回消息给生产者时异常,生产者可能重复发送)
2. 不需要确认:Ack=0(速度快,容易导致数据丢失,丢失时需要重新发送)
3. 只需要Leader确认:ACK=1 (速度居中)
4. 部分确认
Kafka没有完美的方案去解决丢失和重复,只能根据场景去选择
kafka的副本本身就是冗余,若Broker挂了一台(leader),则从剩余的ISR中选择一个Leader;若是Follower挂了,不做处理(保证高吞吐量)6.5 Consumer读数据
Consumer读数据有两种API方式:
1. high level API:封装好的,不够灵活
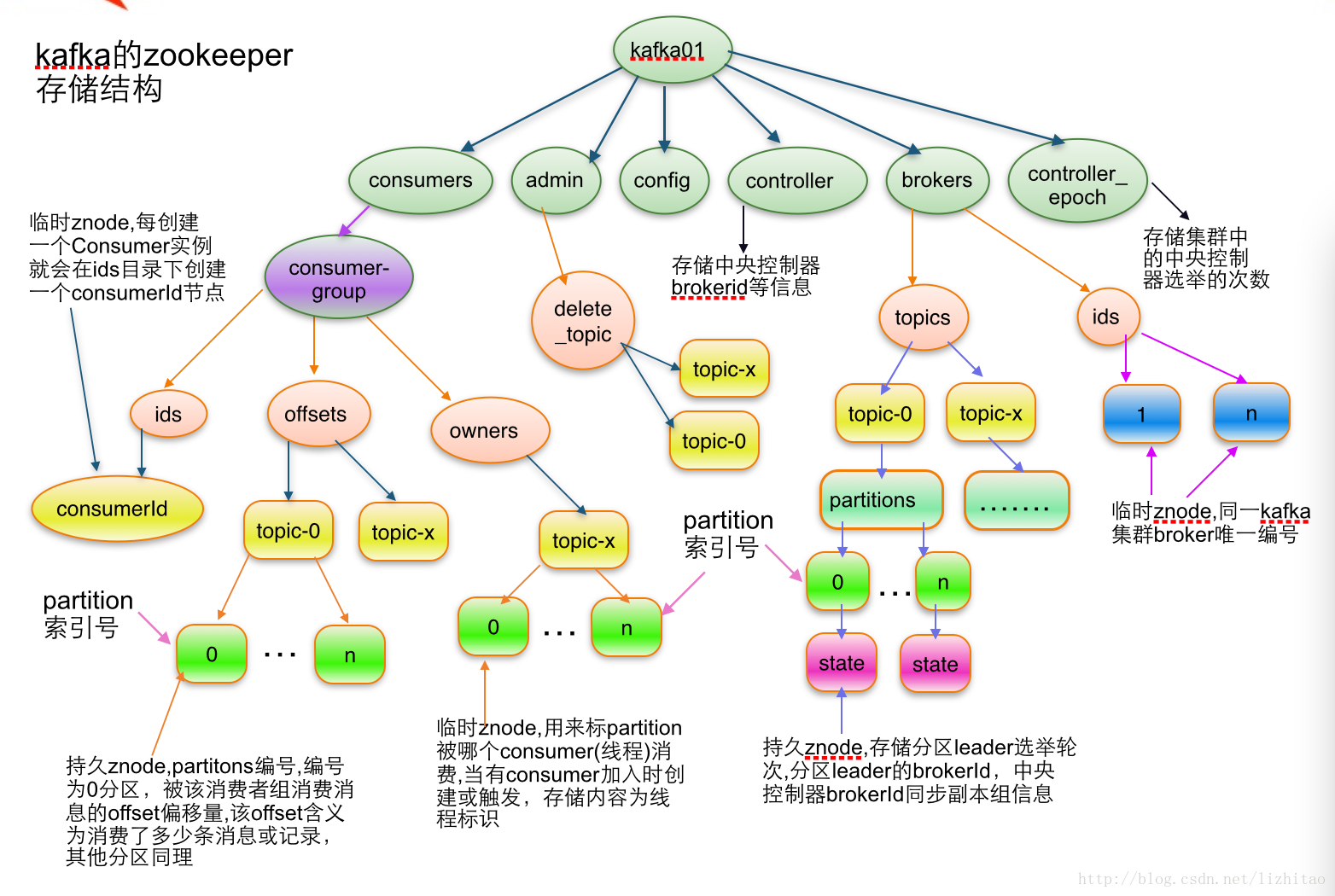
2. low level API:没有进行封装,需要自己去处理(如offset)6.6 Kafka In Zookeeper
6.7 kafka Log 数据存储

1. kafka中的log目录下有index的索引文件以及log的数据文件,类似于MyISAM下的几个文件
2. log文件默认大小1G,当大于1G时,会生成新的文件(kafka会将offset作为文件名的一部分,查找更加便捷)
3. 稀疏索引:减少索引文件的存储大小
4. kafka删除方式:定期删除(时间维度)、合并(大小维度,相同的key进行合并,只保留最新的key的值)6.8 kafka复制原理

生产者写如Leader副本数据的时候有ACK机制,若Leader副本和Follower副本进行同步期间:
1. Leader挂了(此时会有一个Follower被选举为新的Leader副本),因HW并没有更新到原有Leader的LEO位置上,存在数据丢失的可能性:
1.1 生产者此时并没有收到ACK消息,若不进行重发,则消息丢失
1.2 生产者此时并没有收到ACK消息,若进行重发,则消息不丢失
2. Leader没挂,但是Follower同步非常耗时(可能超过生产者等待ack的timeout设置),严重影响了吞吐量,此时kafka采用了ISR机制,即只要可用副本进行了同步即可
HW:最高水平线,即副本ISR中的数据都同步到了那个位置,也是消费者可以消费的最大位置
LEO:一个分区中最大的位置
ISR:副本同步队列
推荐视频:https://ke.qq.com/course/309013?taid=2242587109144341
Leader副本将某个Follower剔除ISR的情况:
1. 数量:Follower副本和Leader副本不同的数量已经超过了数量的设置
2. 时间:Follower副本已经多久没有给Leader发送确认(Leader有新消息同步时)
6.9 Kafka防丢失、防重复策略
1. 数据丢失:当向kafka发送数据时,连接超时,此时数据可能丢失:
预防策略:
1.1 callback的方式,通过callback获取异常数据:
1.1.1 直接重试
1.1.2 消息放入到redis中,另起一个生产者读取数据进行消息重发
1.2 kafka内部重试机制,retries设置
1.3 ack的确认策略(all,1,0)设置可靠性级别
1.4 手动提交offset
2. 数据重复:生产数据时重复
2.1 处理消息时,key都会保存到redis中,处理时,首先判断key是否存在,存在的话说明消息重发(redis要和kafak相同的有效期)
2.2 幂等性处理
7. kafka注意事项
1. kafka版本号
kafka基于scala语言,包名的前几位是scala的版本号,后几位才是kafka版本号,如kafka_2.13-2.7.0,版本号是2.7.0
2. kafka主题
kafka生产/消费消息,主题概念是前提,主题用于消息的分类
3. kafka分区路由
3.1 kafka生产者可以指定分区进行消息发送
3.2 kafka生产者默认会以轮训的方式将消息负载均衡到多个分区
3.3 kafka生产者可以重写分区策略(继承分区接口),如对key进行hash取值保证相同的key落在同一个分区
3.4 kafka消费者可以指定分区的消费,对于同一主题下的一个消息,消费组中只能有一个消费者消费,所以当消费者指定分区消费时,也就意味着这个分区不能再被kafka进行分配(此处未做验证,请保持怀疑态度)
4. 消费组中消费者实例与分区(官方文档解释如下)
4.1 在Kafka中实现消费的方式是将日志中的分区划分到每一个消费者实例上,以便在任何时间,每个实例都是分区唯一的消费者。
4.2 维护消费组中的消费关系由Kafka协议动态处理。如果新的实例加入组,他们将从组中其他成员处接管一些 partition 分区;如果一个实例消失,拥有的分区将被分发到剩余的实例。
5. Kafka副本是以分区为单位的
5.1 Kafka中有副本的概念,副本是以分区为单位的备份,一个分区会有有一个leader角色,以及0个若干个Follower角色,用以保证高可用性(要特别注意是以分区为单位的,Leader以及Follower也是基于分区概念的,和Master-Slave模式稍有区别,后者一般是以服务器实例为单位的)。
5.2 Leader分区负责消费者进行消息的读写,Follower不参与,这个不像zookeeper集群(zookeeper集群中Leader负责写操作,其它Follower可以读)
6. kafka消息丢失
6.1 生产者生产消息至Broker时,若Leader分区所在机器宕机,而此时其它Follower分区并没有拉取到新增的消息却被选举为了Leader分区,则消息会丢失。
6.2 开启自动offset提交时,消费者拿到消息即会向Broker提交offset,但后面消息没有成功处理,则也会丢失消息
7. Kafka消息重复
7.1 生产消息的时候有ACK确认机制,若消息发送到了Broker中,但是向生产者返回确认信息时网络异常,生产者若有重试机制,则可能导致消息重复。
7.2 kafka删除主题只是一个标记删除,其实消息还在,只有在重启Broker实例时才会消失。推荐:Kafka 架构设计
【说明】梳理知识用,有些地方未做验证,请保持怀疑态度。















 1423
1423











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









