









文章目录
论文地址:https://arxiv.org/abs/2008.03673
代码:未公开
发表在ECCV2020
本文贡献
对于没有充分表达的尾部类则需要额外的知识来补充,所以作者利用头部的类无关特征作为额外的知识来增强尾部类。
思路
虽然深度学习取得了非常好的效果,但是有一个前提条件:所有的类都需要被很好的表达。如何量化数据的representation是一个有挑战的问题。

如图所示虽然一些方法可以调整决策边界,但是当尾部数据过少时,如何找到决策边界的正确调整方向是有挑战的。因此,作者想通过augment的方法恢复尾部数据特征分布,并利用头部的信息实现这一过程。

例如,图3左侧只有中心红色点代表降维后的尾部数据,当数据过少时,通过简单移动决策边界无法得到最优解。图3右侧代表数据充足时的决策边界。
两个假设
- 头部的类通用(类别无关信息)特征有助于恢复尾部类的数据分布。
- 由于在高级特征空间具有更“线性”的表示,可以提取类通用和类特定的特征,并重新混合生成新的样本。
方法
CAM(class activation map)
简述:得到一个热力图(类激活图),都是0到1之间的数值,越接近1的部分代表对识别这个类越有帮助,也就是类相关特征,反之亦然。作者对类相关特征和类无光特征分别设定了两个阈值。
可视化特征
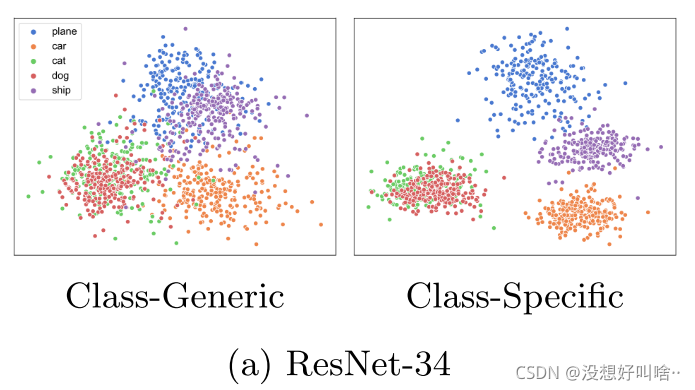
对于提取的类相关与无关特征可视化,可见无关特征更紧密,相关特征更具有代表性,也越容易分离。
流程
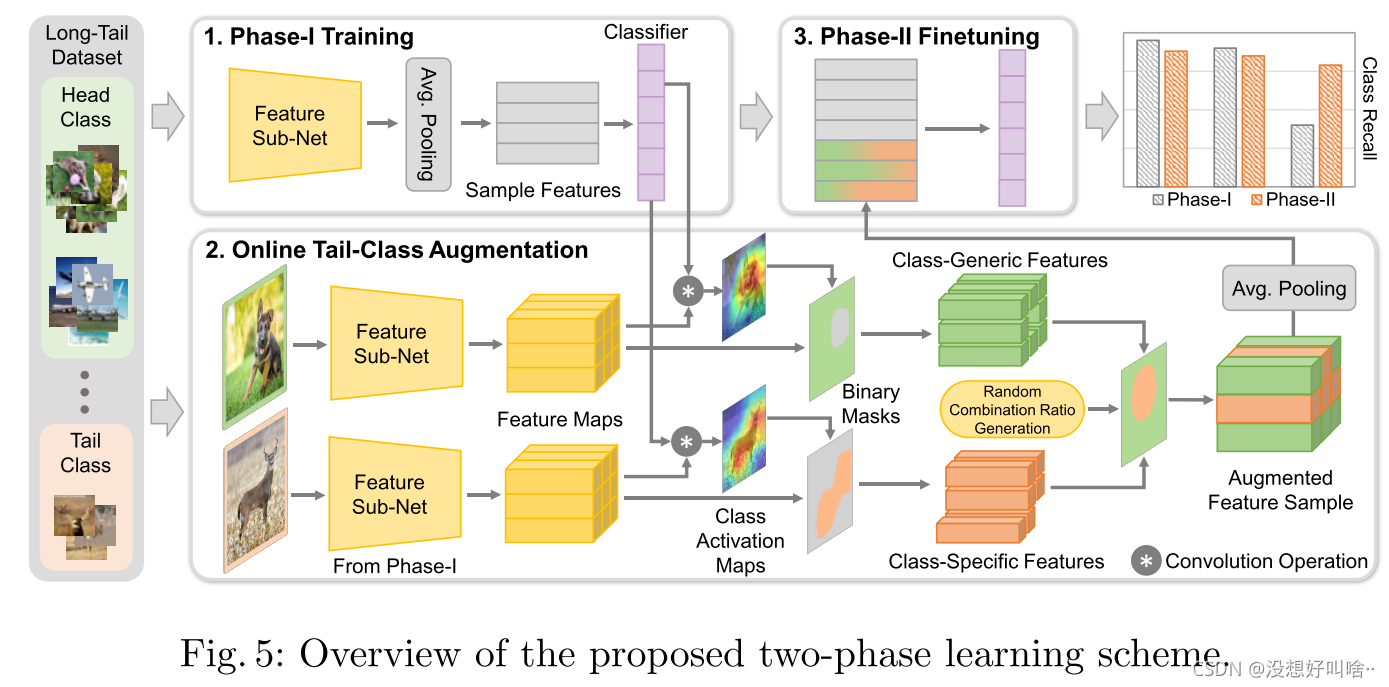
- 正常训练得到数据的representation和分类器。
- 利用第一步得到的representation训练CAM得到类别相关和无关特征,再利用得到的与尾部类最混淆类的类别无关特征和尾部数据做一个线性加权生成增强后的新尾部数据。作者认为在特征空间加权会减少噪声和偏差。
- 做一个fine tuning。
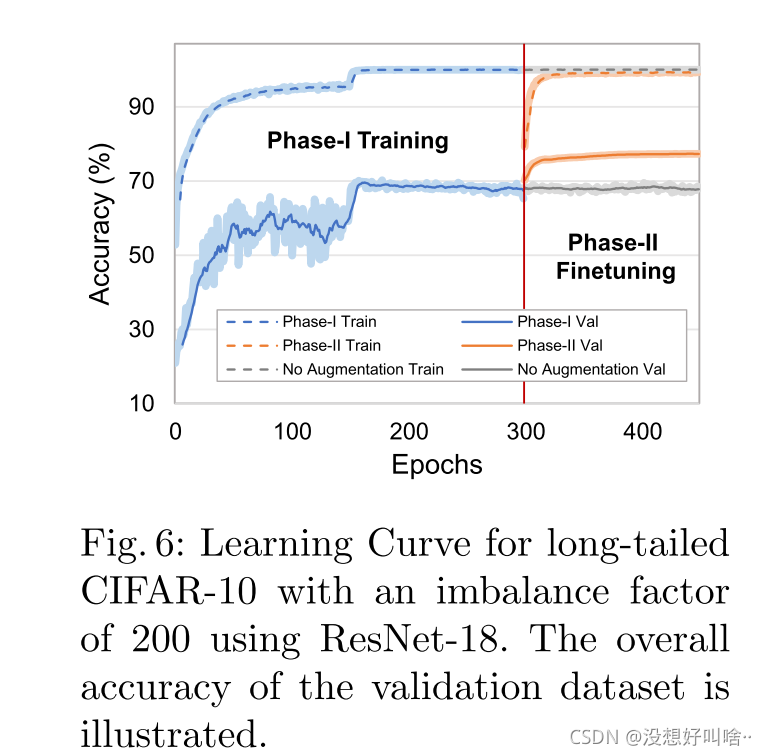
可以看到在验证集上有一个不错的提升。
实验
CIFAR10、CIFAR100
ImageNet、Places
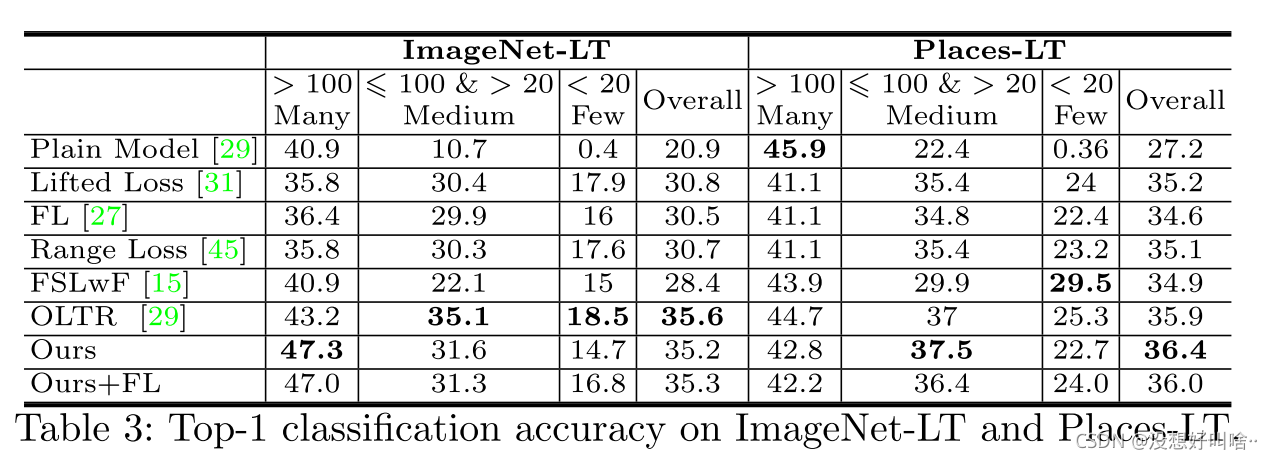
iNaturalist 2017、2018
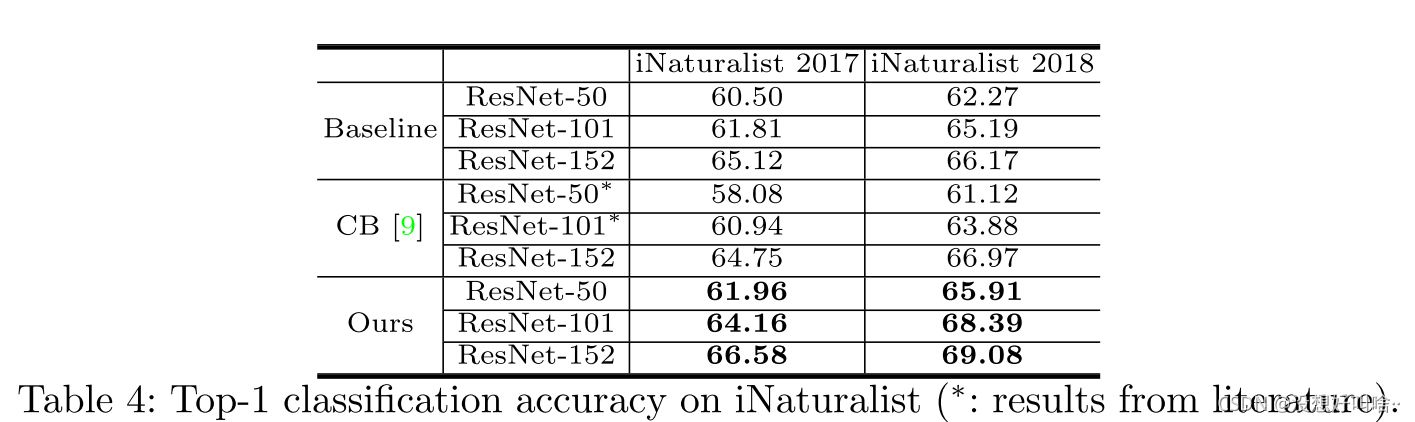
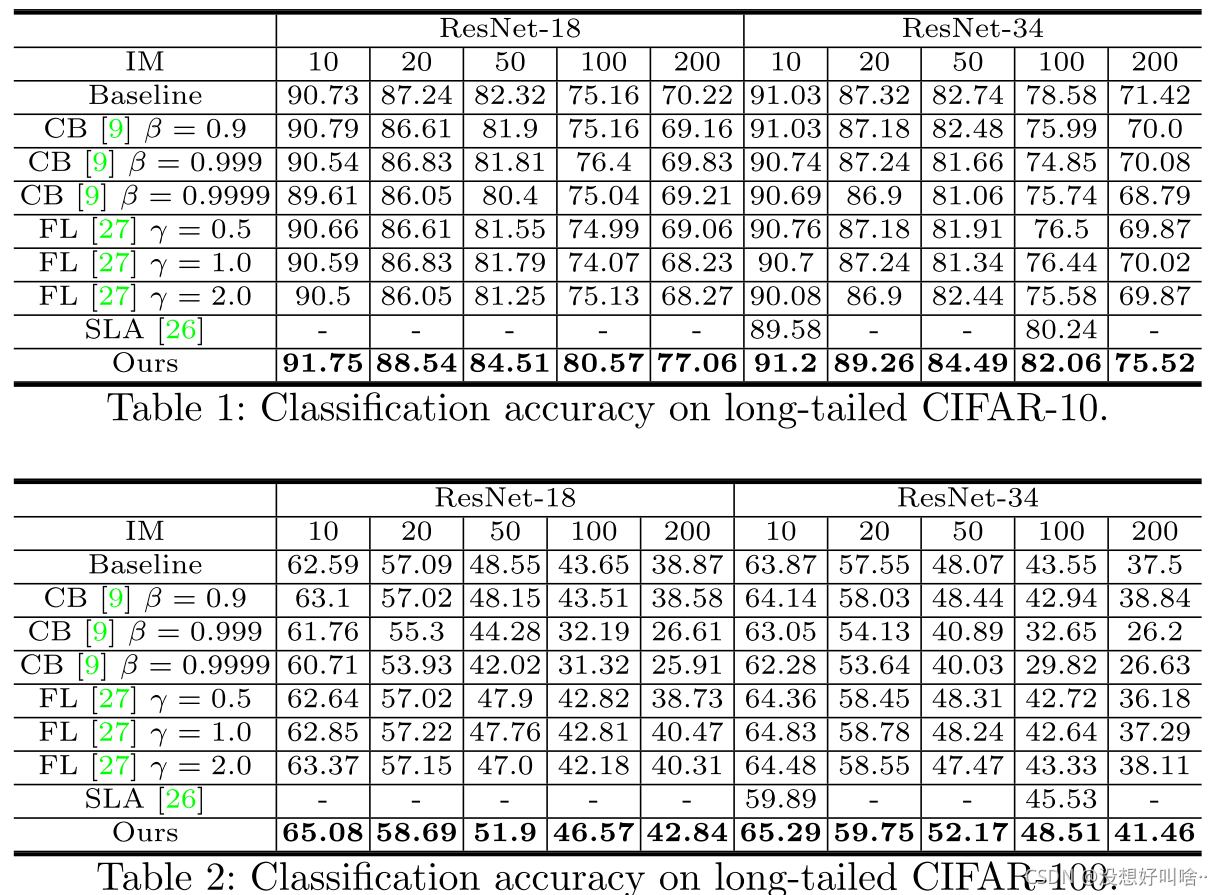
实验结果可能没有别的论文好,不错方法确实有效。
探讨
融合层的深度
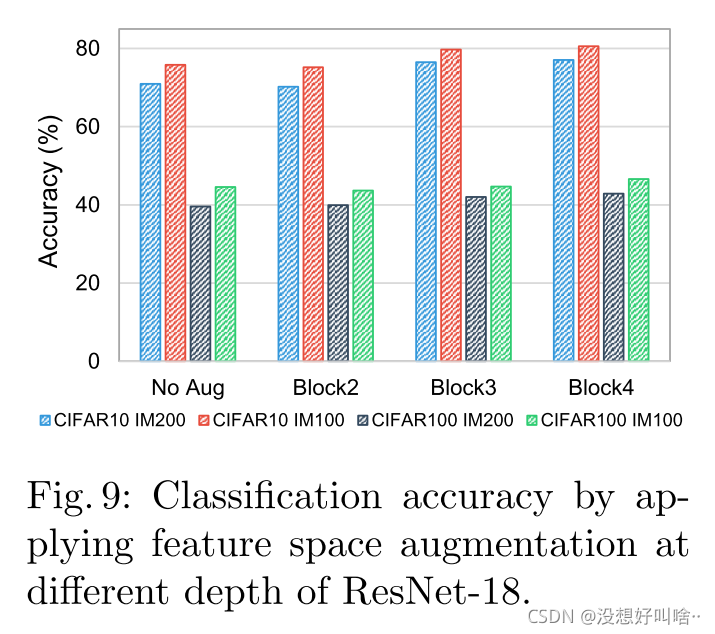
可见,还是在Block4的时候效果偏好。作者认为在靠近输入端的特征图包含更多的空间信息,在增强样本时会引入额外的artifacts(我理解为人为噪声)。
头部和尾部的划分
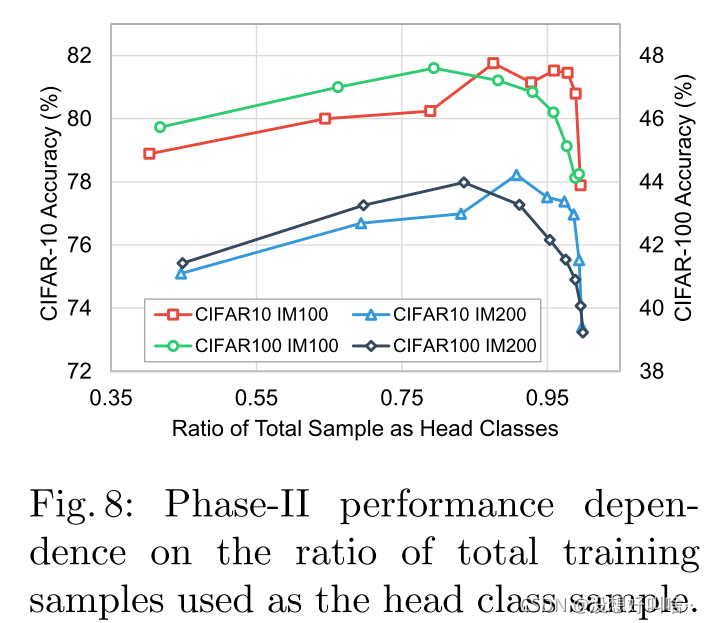
实验证明头部数据占总样本的95%时效果最好。
总结
idea简单,实验完整。挺好















 1212
1212











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









