







Github完整代码获取:https://github.com/Lian-Zekun/python_spilder
1.实现功能
可以分别对歌名,歌手,歌单进行搜索,搜索歌曲和歌单会列出页面第一页所显示的所有歌曲或歌单及其id以供选择下载,搜索歌手会下载网易云音乐列表显示第一位歌手的所有热门歌曲。
2.具体实现
1.搜索部分
网易云音乐搜索界面为:https://music.163.com/#/search ,经过测试发现
对单曲搜索时链接为:https://music.163.com/#/search/m/?s={}&type=1 ,
对歌手搜索时链接为:https://music.163.com/#/search/m/?s={}&type=100 ,
对歌单搜索时链接为:https://music.163.com/#/search/m/?s={}&type=1000
其中大括号中内容为要搜索内容的名称,例如搜索年少有为,网址为:https://music.163.com/#/search/m/?s=年少有为&type=1 搜索后即出现此页面
通过检查元素发现在网页的这一部分存在歌曲链接和名字
同理,在搜索歌单和歌手时检查元素也会发现类似的情况
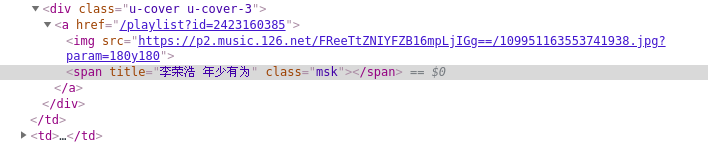
虽然分析网易云音乐接口可能会更快的得到这些信息,网上也有很多这样的文章,但菜鸡的我现在对js实在是不懂,选择selenium + chrome 获取js渲染后的页面源码,并通过xpath提取想要的信息(虽然速度是慢了点,但它简单啊)
python代码:
本文导入的所有模块及对爬虫的伪装
import requests
from urllib import request
from lxml import etree
from selenium import webdriver
import platform
import os
import time
headers = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.81 Safari/537.36',
'Host': 'music.163.com',
'Referer': 'https://music.163.com/'
}
通过selenium获得页面源码
def selenium_get_html(url):
"""通过selenium获得页面源码"""
# 无界面启动chrome
options = webdriver.ChromeOptions()
options.add_argument(
'User-Agent="Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.81 Safari/537.36"')
options.add_argument('--headless')
driver = webdriver.Chrome(chrome_options=options)
driver.get(url)
# 歌曲信息在frame框架内,进入frame框架得到源码
driver.switch_to.frame('contentFrame')
return driver.page_source
得到具体信息
# 提取歌曲名称,演唱者姓名,和歌曲id以供选择
def search_input_song(url):
"""获取歌曲名字和id"""
html = selenium_get_html(url)
root = etree.HTML(html)
id = root.xpath('//div[@class="srchsongst"]//div[@class="td w0"]//div[@class="text"]/a[1]/@href')
artist = root.xpath('//div[@class="srchsongst"]//div[@class="td w1"]//div[@class="text"]/a[1]/text()')
name = root.xpath('//div[@class="srchsongst"]//div[@class="td w0"]//div[@class="text"]//b/@title')
id = [i.strip('/song?id==') for i in id]
return zip(name, artist, id)
# 歌手默认选择第一位,所以仅得到第一位歌手的id
def search_input_artist(url):
"""获取歌手id"""
html = selenium_get_html(url)
root = etree.HTML(html)
id = root.xpath('//div[@class="u-cover u-cover-5"]/a[1]/@href')
return id[0].strip('/artist?id==')
# 提取歌单名称,和歌单id以供选择
def search_input_playlist(url):
"""获取歌单名字和id"""
html = selenium_get_html(url)
root = etree.HTML(html)
id = root.xpath('//div[@class="u-cover u-cover-3"]/a/@href')
name = root.xpath('//div[@class="u-cover u-cover-3"]//span/@title')
id = [i.strip('/playlist?id==') for i in id]
return zip(name, id)
2.下载歌曲
1.再次获取信息
得到id信息后,就可以在交互界面提示用户选择id下载。对于单曲来说获取用户选择的id后与对应地址拼接即可进行下载,而对于歌单和歌手因为每一个单位中都存在多首歌曲,第一次仅仅获取了歌手或歌单的id,需要二次分析。我们通过刚刚获取的链接可以发现
单曲的地址为:https://music.163.com/song?id={}
歌手的地址为:https://music.163.com/artist?id={}
歌单的地址为:https://music.163.com/playlist?id={} ({}内为id)
这回我们进入歌手的页面,检查元素查询歌曲信息,但这次有一个小坑,因为获取的页面中真正的歌曲信息并不在我们检查时看到所在的位置,通过查看框架源代码发现真正的信息在这,歌单页面也是一样。
python代码:
# url为歌单或歌手的地址
def get_url(url):
"""从歌单中获取歌曲链接"""
req = requests.get(url, headers=headers)
root = etree.HTML(req.text)
items = root.xpath('//ul[@class="f-hide"]//a')
print(items)
return items
2.下载
通过之前的爬取,我们已经获得了歌曲的id及名称,可以进行下载了
网易云音乐有一个下载外链:https://music.163.com/song/media/outer/url?id={}.mp3
大括号中内容为所下载音乐在网易云的id,所以通过该外链和相应id即可下载网易云音乐。
将id和外链进行拼接后发送get请求,获取get请求所得到页面请求头中’Location’内容,这里面存储的是真正的音乐地址,使用request模块的urlretrieve方法下载。
python代码:
# song_id为歌曲id, song_name为歌曲名称
def download_song(song_id, song_name):
"""通过外链下载歌曲"""
url = 'https://music.163.com/song/media/outer/url?id={}.mp3'.format(song_id)
# get请求设置禁止网页跳转,即allow_redirects=False
req = requests.get(url, headers=headers, allow_redirects=False)
song_url = req.headers['Location']
try:
# path在主函数中输入
request.urlretrieve(song_url, path + "/" + song_name + ".mp3")
print("{}--下载完成".format(song_name))
except:
print("{}--下载失败".format(song_name))
3.结语
网易云音乐下载就这么草率的完成了,还有一些瑕疵,因为在写的时候并没有完全构思好,想到什么就加点什么,但绝对可以正常的运行。
本博客文章仅供博主学习交流,博主才疏学浅,语言表达能力有限,对知识的理解、编写代码能力都有很多不足,希望各路大神多多包涵,多加指点。















 1634
1634











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









