







一、前言
今天为大家带来的是2018年由中科大、北邮、微软联合推出的xDeepFM(eXtreme Deep Factorization Machine)模型。 (Lian, Jianxun, et al. "xdeepfm: Combining explicit and implicit feature interactions for recommender systems." Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. ACM, 2018.)
该模型的主要贡献在于,基于vector-wise的模式提出了新的显式交叉高阶特征的方法,并且与DCN(https://blog.csdn.net/weixin_41332009/article/details/113745300)一样,能够构造有限阶交叉特征。虽然xDeepFM在名称上与DeepFM相似,但其主要对比的是DCN模型。
在进行模型分析与对比之前,首先为大家介绍一下什么是vector-wise模式。与vector-wise概念相对应的是bit-wise,在最开始的FM模型当中,通过特征隐向量之间的点积来表征特征之间的交叉组合。特征交叉参与运算的最小单位为向量,且同一隐向量内的元素并不会有交叉乘积,这种方式称为vector-wise。后续FM的衍生模型,尤其是引入DNN模块后,常见的做法是,将embedding之后的特征向量拼接到一起,然后送入后续的DNN结构模拟特征交叉的过程。这种方式与vector-wise的区别在于,各特征向量concat在一起成为一个向量,抹去了不同特征向量的概念,后续模块计算时,对于同一特征向量内的元素会有交互计算的现象出现,这种方式称为bit-wise。
将常见的bit-wise方式改为vector-wise,使模型与FM思想更贴切,这也是xDeepFM的Motivation之一。这里需要提醒的是,vector-wise的方式其实在之前介绍的PNN、NFM、AFM与DeepFM中都有使用,但是并没有单独拎出来说明清楚。
关于xDeepFM的另一个贡献点“有限阶数特征交叉”,所具备的优点之前也提到过。简单DNN结构虽然说能够隐式交叉特征,学习任意函数的表示,但是我们并不清楚其最大特征交叉阶数为多少,简单来说就是无法得知哪些特征交叉可以得到最佳效果,而显式指定阶数交叉特征能够在一定程度缓解这些问题。
在论文原文中,作者对DCN模型的Cross Network进行分析,并从数学层面证明了Cross Network最终学习到的是一种特定形式的表示,认为该结构不利于模型充分表征交叉特征。个人理解,Cross Network之所以采用该形式,是因为其精简参数,在实现显式特征交叉的同时控制计算复杂度。二者孰优孰劣,仍需要在实际业务场景中对比试验方能判定。
二、分析
1. 模型结构
xDeepFM的模型结构如下所示,下面将对模型的四个模块详细讲解。
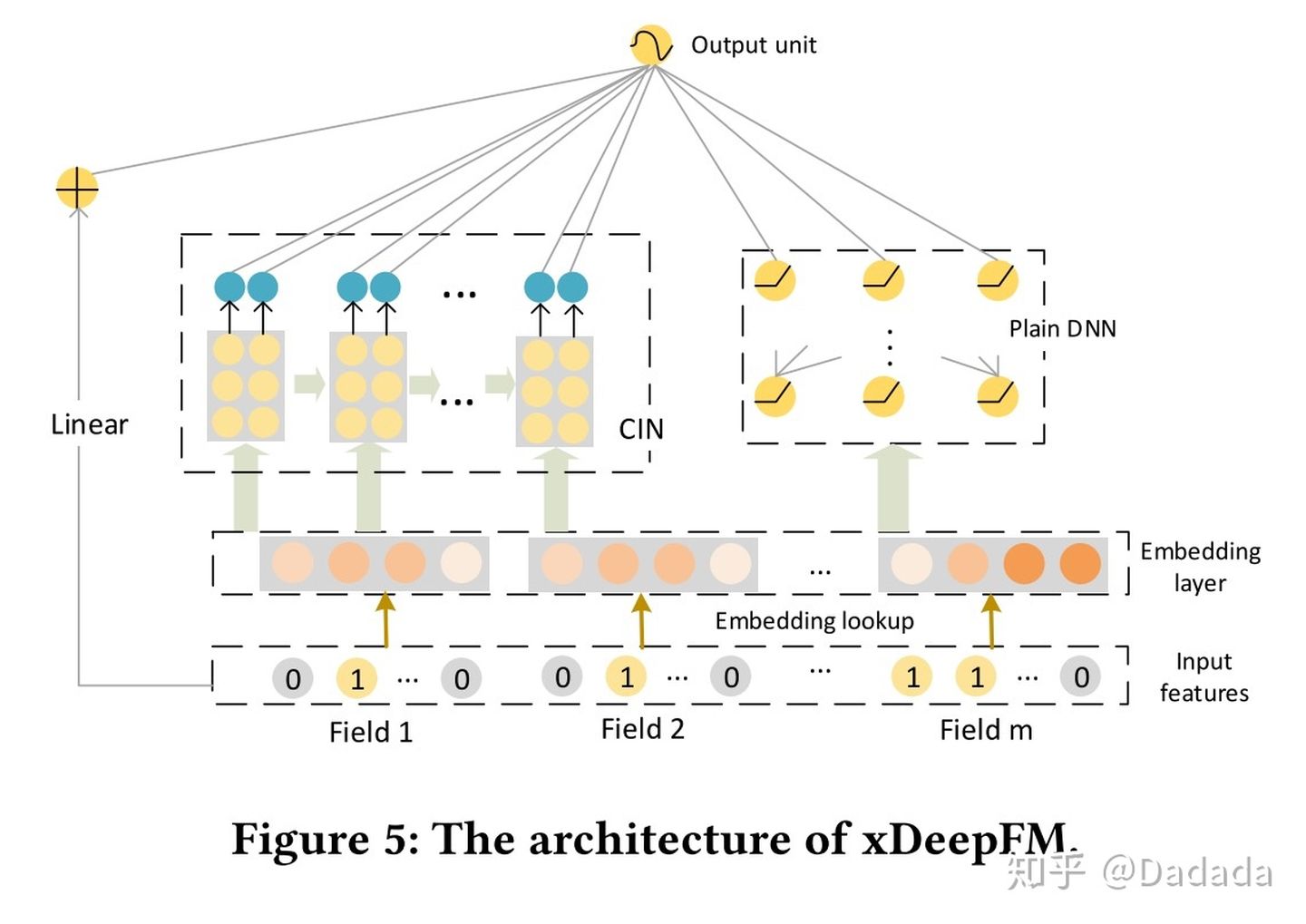
1.1 Embedding Layer
这个部分无需多言,将离散特征进行embedding,表示成低维稠密向量。每个field对应一个field的embedding向量。
If the field is univalent, the feature embedding is used as the field embedding.
If the field is multivalent, the sum of feature embedding is used as the field embedding.
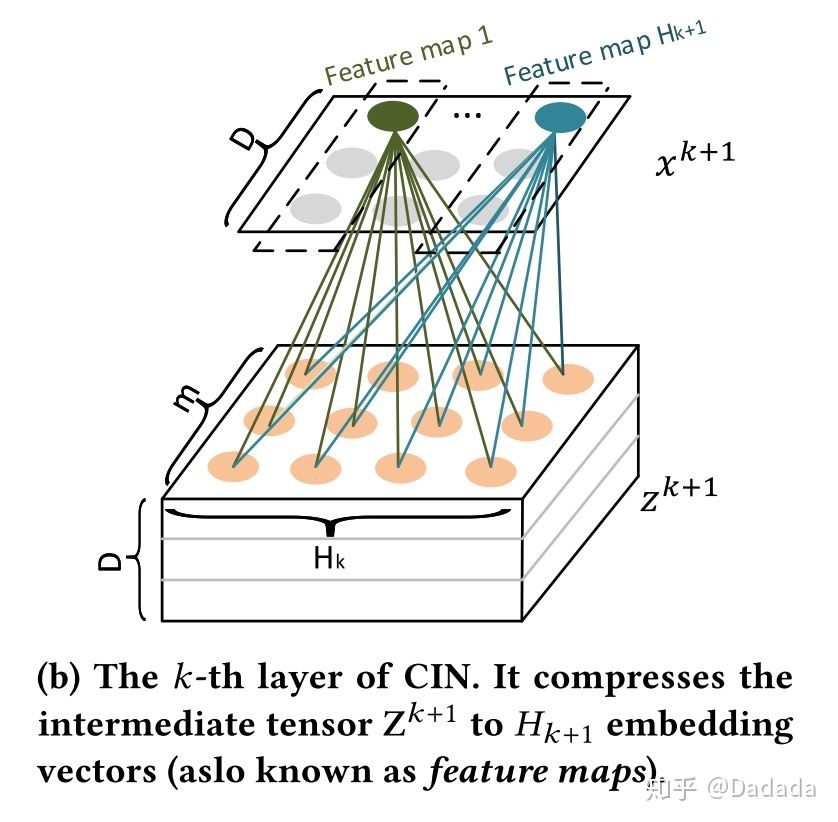
 1.2 Compressed Interaction Network(CIN)
1.2 Compressed Interaction Network(CIN)
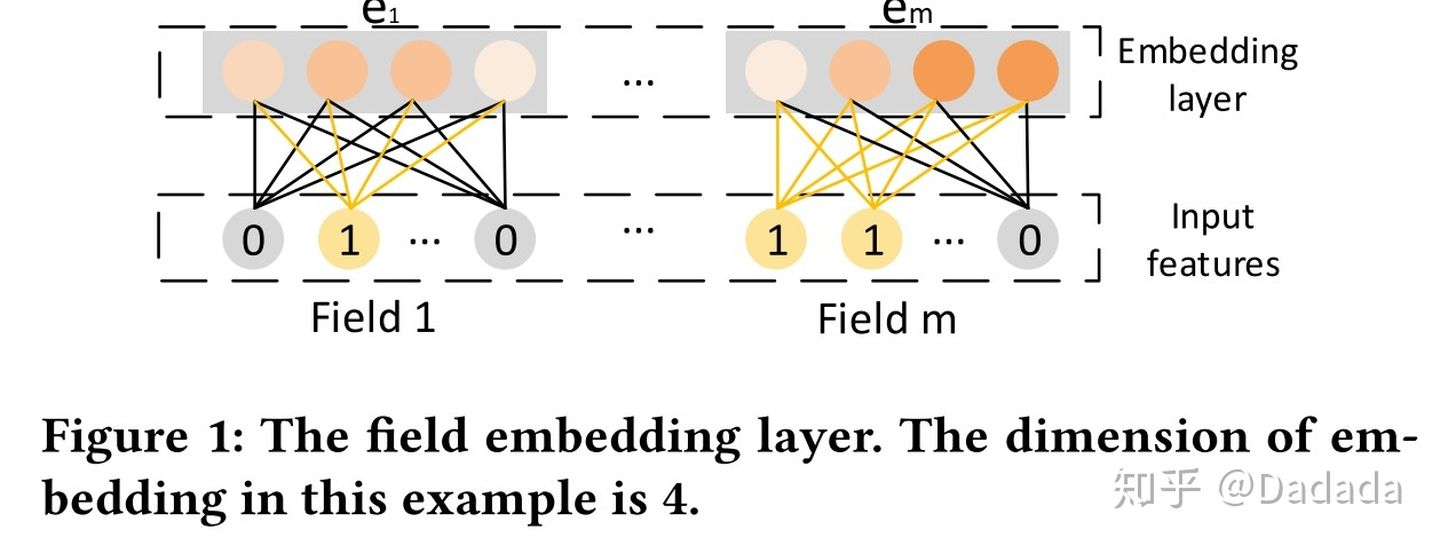
与DCN的bit-wise不同的是,xDeepFM的CIN中采用vector-wise对特征向量进行交叉。这就意味着不能简单的把所有的embedding全部concat在一起,因为这样就把每个向量都混在一起了;应该让所有的embedding构成一个矩阵,这样才能把不同特征的embedding区分开来。
将embedding矩阵表示为 ,
第 i 行表示第 i 个Field 对应的特征 embedding 向量,共有 m 个 D 维的embeddding vector。m是field数,D是embedding长度。
 ==============
============== 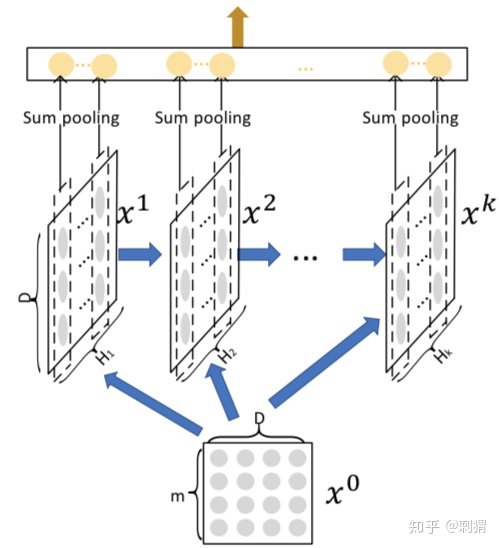
CIN是多层输出结构,每层都会产出一个中间结果矩阵,将第 k 层产出的矩阵表示为 ,说明第k层的field数从m个压缩成了
个,但是embedding长度还是D不变。
,就是原先的field数。
具体地,第 k+1 层每个vector的计算方式为:
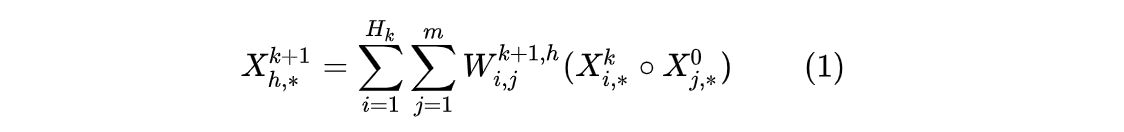
看懂了这个计算公式,就理解了CIN结构,我们先看这个公式到底干了什么:
步骤一.
![]() :遍历前一层
:遍历前一层 的每一行(共有
行,每一行是个长度为D的vector)。
![]() :遍历输入层
:遍历输入层 中每一行(共有m行,每一行是一个长度为D的vector)。进行两两Hadamard乘积运算,得到
个长度为D的 vector(
![]() 就是一个长度为D的vector),然后加权求和。
就是一个长度为D的vector),然后加权求和。
步骤二.
![]() 表示下一层矩阵的第h行向量,它的长度是D维。它就是那
表示下一层矩阵的第h行向量,它的长度是D维。它就是那 个长度为D的 vector经过
个参数矩阵
加权平均得到的。
下面直观的来看图:
步骤一对应图
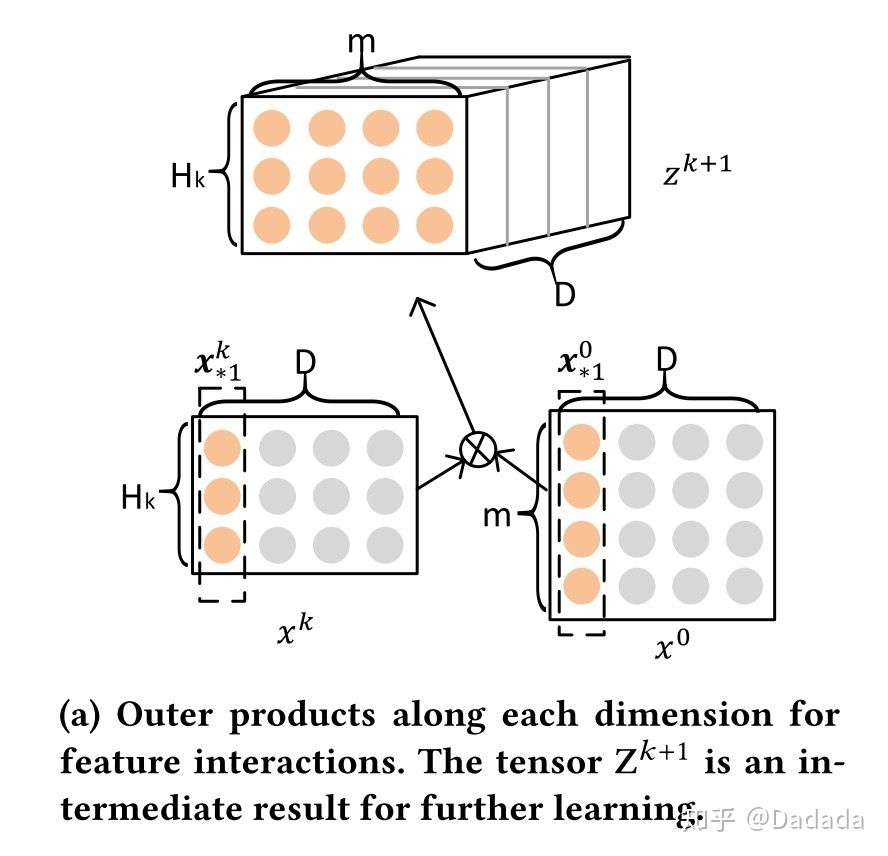
和
两两求Hadamard积,构成了
个D维向量:
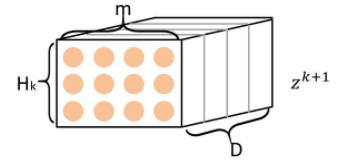 每一个黄色的“桶”就是一个D维向量。
每一个黄色的“桶”就是一个D维向量。
步骤二对应图:
现在,我们有了个D维向量。要想通过它们生成下一步的矩阵
, 需要把它们加权求和。对于
的每一行(D维),都需要这
个D维向量通过某个权重加权求和。
得到每层的输出之后,通过sum pooling操作将所有的特征矩阵
进一步压缩为向量,作为最终的输出。

中含有
个长度为D的特征embedding,对
中每一行求和得到一个值
![]() 。总共有
。总共有行,所以总共有
个值
![]() 。将所有矩阵的sum pooling值拼接起来,得到:
。将所有矩阵的sum pooling值拼接起来,得到:![]() ,记作
,记作.
最终 CIN 的输出为: 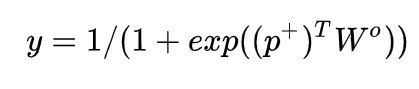
1.3 DNN

在Embedding Layer之后,除了连接CIN模块,同时并行的会接入到简单的多层感知机。与Wide&Deep、DeepFM类似,设置这个模块的目的在于,隐式交叉编码可以作为显式交叉(CIN)的补充,进一步的提高模型表征能力。
1.4 Linear part
![]()
这个部分可以是一个简单的LR,将原始特征(未经过Embedding)作为输入,表示为:![]() ,其中的 a 就是原始特征输入,
,其中的 a 就是原始特征输入, 是激活函数。
1.5 模型组合
各个模块分析完毕,将1.1~1.4所有模块组合到一块,三个输出模块(Linear、CIN、DNN)统一到一起,作为模型的最终输出,公式如下:
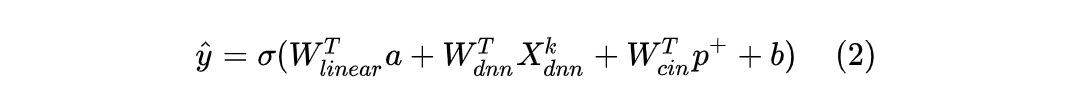
其中,a 是原始特征, 是DNN模块的输出向量,
是CIN模块的输出向量,
分别是对应模块的可训练参数,b 为全局偏置项,
为激活函数。
从这个形式上来看,xDeepFM既有低阶项又有高阶项,既有显式交叉又有隐式组合,并且是基于vector-wise级别的交叉,可谓是应有尽有,算是FM类模型的完备实现了。
三、与FM、DeepFM的关系
假设输入的所有特征Field都是单值的,CIN模块只有1层,并且其中的feature map只有1个,此时的xDeepFM模型基本等价于DeepFM模型。因为CIN模块只对所有的特征embedding vector进行两两哈达玛积,将得到的结果进行加权求和(DeepFM是权重恒定为1进行求和),然后再对结果进行sum pooling作为输出。结合一阶项与DNN部分,模型基本等价于DeepFM。
如果更进一步,将DNN部分去除,同时在加权求和部分固定权重为1,那么此时xDeepFM与FM模型完全等价。















 360
360











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









