






参考(翻译)博客https://www.analyticsvidhya.com/blog/2015/08/comprehensive-guide-regression/#
python,7种回归技术,你应该知道!
一、引言
在预测模型中回归(线性、逻辑)通常是人们最先遇到的算法。由于受欢迎程度,许多分析师甚至认为他们是唯一的回归形式。 更多参与的人认为他们是所有形式的回归分析中最重要的。
事实是,有无数形式的回归可以执行。 每种形式都有其自身的重要性和最适合应用的特定条件。 在本文中,我以简单的方式解释了最常用的7种形式的回归。 通过这篇文章,我也希望人们能够形成回归广度的概念,而不是仅仅对他们遇到的每个问题应用线性/逻辑回归,并希望它们能够适合!
本文内容:
1. 什么是回归分析?
2. 为什么我们使用回归分析?
3. 回归的类型有哪些?
线性回归
Logistic回归
多项式回归
逐步回归
岭回归
套索回归
弹性网络回归
4.如何选择合适的回归模型?
一、什么是回归分析?
回归分析是预测建模技术的一种形式,它研究依赖(目标)和自变量(预测变量)之间的关系。 该技术用于预测,时间序列建模和查找变量之间的因果关系。 例如,通过回归可以最好地研究急速驾驶与驾驶员引起道路交通事故数量之间的关系。
回归分析是建模和分析数据的重要工具。 在这里,我们将曲线/线拟合到数据点,使得数据点距曲线或线的距离之间的差异最小化。 我将在接下来的章节中详细解释这一点。
二、为什么我们使用回归分析?
如上所述,回归分析估计两个或更多变量之间的关系。让我们通过一个简单的例子理解这一点:
比方说,您想根据当前的经济状况估算公司的销售增长率。您有最近的公司数据表明销售增长约为经济增长的2.5倍。利用这种洞察力,我们可以根据当前和过去的信息预测公司的未来销售情况。
使用回归分析有很多好处。它们如下:
它表明因变量和自变量之间的重要关系。
它表示多个自变量对因变量的影响强度。
回归分析还允许我们比较在不同尺度上测量的变量的影响,例如价格变化的影响和促销活动的数量。这些优势有助于市场研究人员/数据分析师/数据科学家消除和评估用于构建预测模型的最佳变量集。
三、我们有多少种回归技术?
有各种各样的回归技术可用于进行预测。 这些技术主要由三个指标(自变量的数量,因变量的类型和回归线的形状)驱动。 我们将在以下部分详细讨论它们。
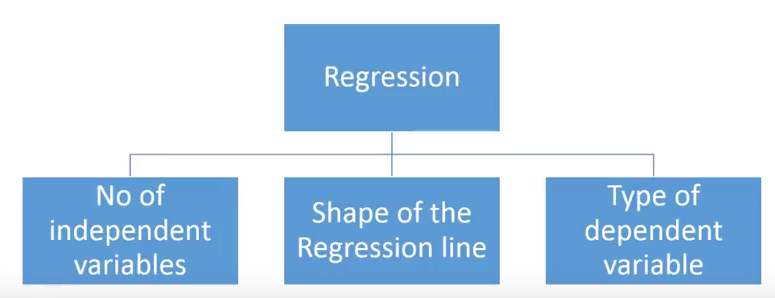
对于创造性的,如果您觉得需要使用上述参数的组合,您甚至可以做出新的回归,这些参数以前没有用过。 但在开始之前,让我们了解最常用的回归:
1. Linear Regression
它是最广为人知的建模技术之一。 线性回归通常是人们在学习预测建模时选择的前几个主题。 在该技术中,因变量是连续的,自变量可以是连续的或离散的,并且回归线的性质是线性的。
线性回归使用最佳拟合直线(也称为回归线)在因变量(Y)和一个或多个自变量(X)之间建立关系。
它由等式Y = a + b * X + e表示,其中a是截距,b是线的斜率,e是误差项。 该等式可用于基于给定的预测变量预测目标变量的值。
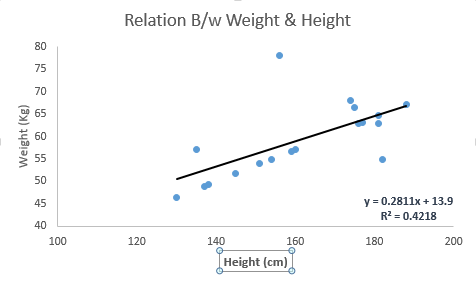
简单线性回归和多元线性回归之间的区别在于,多元线性回归具有(> 1)个独立变量,而简单线性回归只有1个独立变量。 现在,问题是“我们如何获得最佳拟合线?”
How to obtain best fit line (Value of a and b)?
这项任务可以通过最小二乘法轻松完成。 它是用于拟合回归线的最常用方法。 它通过最小化从每个数据点到线的垂直偏差的平方和来计算观测数据的最佳拟合线。 因为偏差是first squared 第一个平方?,所以当添加时,正值和负值之间没有抵消。
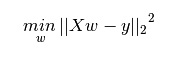
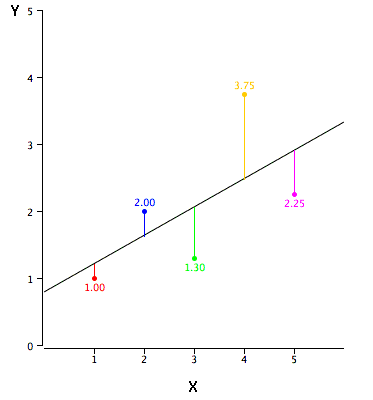
我们可以使用the metric R-square.公制R平方来评估模型性能。 要了解有关这些指标的更多详细信息,请参阅:模型性能指标第1部分,第2部分。
Important Points:
1. 独立变量和因变量之间必须存在线性关系
2. 多元回归受多重共线性,自相关,异方差性的影响。multicollinearity, autocorrelation, heteroskedasticity.
3. 线性回归对异常值Outliers.非常敏感。 它可以极大地影响回归线并最终影响预测值。
4. 多重共线性可以增加系数估计的方差,并使估计对模型中的微小变化非常敏感。 结果是系数估计不稳定
5. 在多个独立变量的情况下,我们可以选择前向选择,后向消除和逐步方法来选择最重要的自变量。forward selection, backward elimination and step wise approach
2. Logistic Regression
Logistic回归用于查找概率 事件=成功 和 事件=失败。 当因变量本质上是二元的(0/1,真/假,是/否)时,我们应该使用逻辑回归。 这里Y的值的范围从0到1,它可以用下面的等式表示。

。Above, p is the probability of presence of the characteristic of interest. A question that you should ask here is “why have we used log in the equation?”.
我们在这里使用二项分布(因变量),我们需要选择最适合这种分布的链接函数。 而且,它是logit功能。 在上面的等式中,选择参数以最大化观察样本值的可能性,而不是最小化平方误差的总和(如在普通回归中)。
Important Points:
它被广泛用于分类问题
逻辑回归不需要依赖变量和自变量之间的线性关系。 它可以处理各种类型的关系,因为它将非线性对数变换应用于预测的优势比
为了避免过度拟合和不合适,我们应该包括所有重要变量。 确保这种做法的一个好方法是使用逐步方法来估计逻辑回归
它需要大样本量,因为最小似然估计在低样本量时比普通最小二乘法更不强大
独立变量不应彼此相关,即不具有多重共线性。 但是,我们可以选择在分析和模型中包含分类变量的交互效应。
如果因变量的值是序数,那么它被称为序数逻辑回归
如果因变量是多类,那么它被称为多项Logistic回归。
3.Polynomial Regression多项式回归
如果自变量的幂大于1,则回归方程是多项式回归方程。下面的等式表示多项式方程:
y=a+b*x^2
在这种回归技术中,最佳拟合线不是直线。 它是一条适合数据点的曲线。
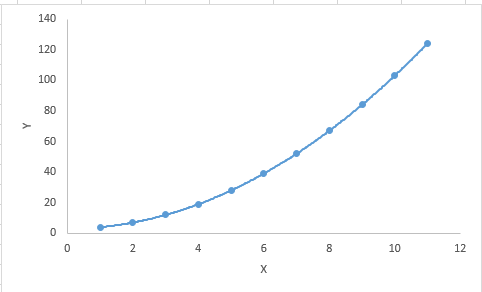
Important Points:
虽然可能存在适合更高次多项式以获得更低误差的诱惑,但这可能导致过度拟合。 始终绘制关系图以查看拟合,并专注于确保曲线符合问题的本质。 以下是绘图如何帮助的示例:
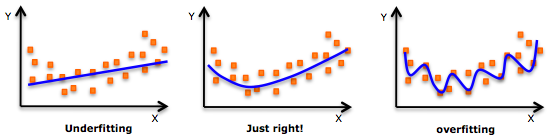
特别注意到最终的曲线,看看这些形状和趋势是否有意义。 更高的多项式最终会在外推时产生奇怪的结果。
4. Stepwise Regression
当我们处理多个自变量时,会使用这种形式的回归。在这种技术中,自变量的选择是在自动过程的帮助下完成的,该过程不涉及人为干预。
这一壮举是通过观察R-square,t-stats和AIC metric等统计值来识别重要变量来实现的。逐步回归基本上适合回归模型,通过基于某些规则一次指定一个(添加/删除)协变量co-variates。下面列出了一些最常用的逐步回归方法:
1.标准逐步回归做两件事。 它根据每个步骤的需要添加和删除预测变量。
2.正向选择从模型中最重要的预测变量开始,并为每个步骤添加变量。
3.向后消除从模型中的所有预测变量开始,并删除每个步骤的最不重要变量。
4.该建模技术的目的是以最少的预测变量来最大化预测能力。 它是处理数据集更高维度的方法之一。
5. Ridge Regression岭回归
岭回归是当数据遭受多重共线性(独立变量高度相关)时使用的技术。 在多重共线性中,即使最小二乘估计(OLS)是无偏的,它们的方差也很大,这使得远离真实值的观测值偏离。 通过向回归估计添加一定程度的偏差,岭回归可以减少标准误差。
上面,我们看到了线性回归的等式。 记得? 它可以表示为:
y=a+ b*x
该等式也有一个误差项。 完整的等式变为:

在线性方程中,预测误差可以分解为两个子分量。 首先是由于偏差,第二是由于方差variance。 由于这两个或两个组件中的任何一个,可能发生预测错误。 在这里,我们将讨论由于方差引起的错误。
岭回归通过收缩参数λ(lambda)解决了多重共线性问题。 请看下面的等式。
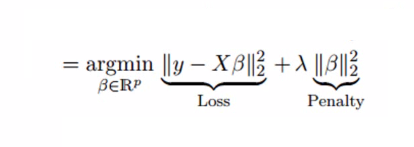
在这个等式中,我们有两个组成部分。 第一个是最小二乘项,另一个是β2(β平方)总和的λ,其中β是系数。 这被添加到最小平方项,以便缩小参数以具有非常低的方差。
Important Points:
该回归的假设与最小二乘回归相同,但不假设正态性
它会缩小系数的值,但不会达到零,这表明没有特征选择功能
这是一种正则化方法并使用l2正则化。
6. Lasso Regression
与岭回归相似,Lasso(最小绝对收缩和选择算子)也会对回归系数的绝对大小进行惩罚。 此外,它还能够降低线性回归模型的可变性并提高其准确性。 请看下面的等式:
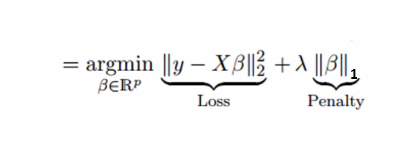
套索回归与岭回归的不同之处在于它在惩罚函数中使用绝对值而不是平方。 这导致惩罚(或等效地约束估计的绝对值的总和)值,这导致一些参数估计精确地为零。 应用的惩罚越大,估计值就越接近绝对零度。 这导致从给定n个变量的变量选择。
Important Points:
该回归的假设与最小二乘回归相同,但不假设正态性
它将系数缩小到零(正好为零),这肯定有助于特征选择
这是一种正则化方法并使用l1正则化
如果预测变量组高度相关,则套索仅选择其中一个并将其他预测变为零
7. ElasticNet Regression弹性网络回归
ElasticNet是Lasso和Ridge Regression技术的混合体。 在作为正则化器之前,它使用L1和L2进行训练。 当存在多个相关的特征时,弹性网很有用。 Lasso很可能随机选择其中一种,而弹性网很可能同时选择其中之一。
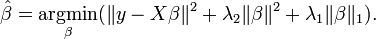
A practical advantage of trading-off between Lasso and Ridge is that, it allows Elastic-Net to inherit some of Ridge’s stability under rotation.
Important Points:
- It encourages group effect in case of highly correlated variables它可以在高度相关的变量的情况下鼓励群体效应
- There are no limitations on the number of selected variables所选变量的数量没有限制
- It can suffer with double shrinkage它能承受双重收缩
除了这7种最常用的回归技术之外,您还可以查看其他模型,如贝叶斯,生态和稳健回归。Bayesian, Ecological and Robust regression.
四、How to select the right regression model?
当你只知道一两种技术时,生活通常很简单。 我所知道的其中一个培训机构告诉他们的学生 - 如果结果是连续的 - 应用线性回归。 如果是二进制 - 使用逻辑回归! 但是,我们可以使用的选项数量越多,选择合适的选项就越困难。 回归模型也会发生类似的情况。
在多种类型的回归模型中,基于独立变量和因变量的类型,数据中的维数以及数据的其他基本特征来选择最适合的技术是很重要的。 以下是您应该选择正确的回归模型的关键因素:
- Data exploration is an inevitable part of building predictive model. It should be you first step before selecting the right model like identify the relationship and impact of variables数据探索是构建预测模型的必然部分。在选择正确的模型之前,应该是您的第一步,例如确定变量的关系和影响
- To compare the goodness of fit for different models, we can analyse different metrics like statistical significance of parameters, R-square, Adjusted r-square, AIC, BIC and error term. Another one is the Mallow’s Cp criterion. This essentially checks for possible bias in your model, by comparing the model with all possible submodels (or a careful selection of them).为了比较不同模型的拟合优度,我们可以分析不同的指标,如参数的统计显着性,R平方,调整后的r平方,AIC,BIC和误差项。另一个是Mallow的Cp标准。这基本上通过将模型与所有可能的子模型(或仔细选择它们)进行比较来检查模型中的可能偏差。
- Cross-validation is the best way to evaluate models used for prediction. Here you divide your data set into two group (train and validate). A simple mean squared difference between the observed and predicted values give you a measure for the prediction accuracy.交叉验证是评估用于预测的模型的最佳方式。在这里,您将数据集划分为两个组(训练和验证)。观察值和预测值之间的简单均方差可以为您提供预测准确度的度量
- If your data set has multiple confounding variables, you should not choose automatic model selection method because you do not want to put these in a model at the same time.如果您的数据集有多个混淆变量,则不应选择自动模型选择方法,因为您不希望同时将它们放在模型中。
- It’ll also depend on your objective. It can occur that a less powerful model is easy to implement as compared to a highly statistically significant model. 高统计显著性的低效模型常有
- Regression regularization methods(Lasso, Ridge and ElasticNet) works well in case of high dimensionality and multicollinearity among the variables in the data set.回归正则化方法(Lasso,Ridge和ElasticNet)在数据集中变量之间具有高维度和多重共线性的情况下运行良好。
到现在为止,我希望你能对回归有所了解。 应该考虑数据条件来应用这些回归技术。 找出使用哪种技术的最佳技巧之一是检查变量族,即离散或连续。
在本文中,我讨论了7种类型的回归以及与每种技术相关的一些关键事实。 作为这个行业的新人,我建议你学习这些技术,然后在你的模型中实现它们。















 707
707

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









