






搬来大佬的文章哦~~
分布式深度学习框架目的只有一个:解决超大模型的训练问题,主要针对两种场景:一个具有超大规模的 dense(密集) 参数的模型,比如 NLP、CV 等;另一个是具有超大规模 sparse(稀疏)参数的模型,比如推荐模型。前一种场景重计算,主要采用 GPU 训练,通信采用 AllReduce 模式,后一种场景重存储和 I/O(参数读写),主要采用的技术是参数服务器。
1、上古时代的分布式机器学习平台
从早期的 MPI,到后来的 Hadoop,乃至于目前还有使用的 Spark,但是它们都存在一些不足:
- MPI Gradient Aggregation: 主要缺点是任务求解器的速度不高,无法支撑大规模数据。
- MapReduce:解决了用户需要手写 MPI 程序的麻烦,统一并抽象出了分布式框架,同时解决了 MPI 无法支撑大数据的问题,但无法改进批处理求解器的训练性能,而且迭代式计算低效、节点间通信低效。
- GraphLab:2010年由 CMU 的 Select 实验室提出,它借鉴了 MapReduce 的思想,将 MapReduce 并行计算模型推广到了对数据重叠性、数据依赖性和迭代型算法适用的领域,填补了 MapReduce 并行计算模型和底层消息传递、多线程模型之间的空隙。但对于深度学习中多层网络结构无法支持。
2、参数服务器的诞生
参数服务器(英文名 Parameter Server,又称 PS)的兴起本质上源于深度学习的快速发展,准确地说是为了应付越来越大的神经网络模型。众所周知,很多深度学习任务,比如推荐任务、自然语言处理等,都依靠海量参数(十亿、百亿、甚至千亿)来提高模型的拟合能力,同时需要给模型喂入大量训练数据。对于世界上顶尖的互联网公司(Facebook、Google、Baidu 等)来说,获取训练数据从来都不是难事,它们甚至拥有多达 TB、PB(1TB = 1024GB,1PB = 1024TB)量级的数剧,这样规模的数据在单机上训练和预测是明显不可能的。此外,它们还拥有丰富的计算资源(CPU/GPU/NPU/XPU 集群)来支持大规模计算。因此,如何有效的利用数据和计算资源,提高模型效率,成为急需解决的问题。于是,参数服务器应运而生。参数服务器提供了一条可行解决思路:将数据、训练参数、OP(执行单元)分散到不同的计算节点上,执行分布式训练,从而达到快速收敛的效果。
日益膨胀的神经网络模型
3、参数服务器的设计要点
- 性能:包括存储能力和计算能力。存储能力指能充分利用各种存储介质,如 SSD、MEM、PMEM、HBM 等,最大化节点的参数存储能力;计算能力指用尽可能少的硬件资源或者充分利用各种类型的硬件设备尽可能快地完成训练任务。
- 适用性:能够支持各种类型的深度学习训练任务。也就是说,Worker 端支持各种大模型的切分及前向和反向计算;PServer 端支持各种类型参数(如推荐任务中的 Sparse、Dense 参数,定长 embedding 和变长 embedding 等)读取、写入和各种梯度更新策略(如 SGD、Adam 等)。
- 通信开销:首先,针对实际应用场景,选取同步或者异步的通讯方式。其次,在异构集群中,涉及到 CPU 之间、CPU 和 GPU、GPU 之间、以及其他 AI 芯片之间的频繁数据交换,选择最优的通信路由是非常必要的。如果能解决通信开销问题,就能够堆更多的机器,从而具备更强的计算和存储能力。
- 一致性:一致性用来衡量不同节点之间的数据是否一致。强一致性意味着不同节点间的同步成本和时延提高。在设计参数服务器时,考虑到深度学习此类应用对数据一致性不敏感,因此研究人员可以通过设计宽松的一致性模型(flexible consistency model),来平衡系统性能和算法收敛。
- 弹性:首先是可扩展性,设计参数服务器需要考虑动态的插入移除某些节点,不能因为某些节点加入,移除或者故障导致系统重启;其次是容错能力。在分布式集群中,难免会出现节点故障,因此需要系统能够快速从非灾难性机器故障中恢复。
- 易用性和二次开发能力:小白用户能够快速上手,这需要参数服务器对外提供简洁的调用接口;对于二次开发用户,能够根据自己的任务特点定制某些功能,比如新的数据存储结构、指标计算模块等等。
4、参数服务器的发展历史
分布式机器学习领域,谷歌和百度是最早的参与者,谷歌在 2012 年发表了他们在大规模分布式机器学习的工作,百度凤巢其实在 2010 年就已经上线了分布式 LR 模型和参数服务器架构。2013 年开始上线超大规模稀疏 DNN 模型。PaddlePaddle(飞桨)在 2018 年开始支持大规模稀疏参数并对外开源。
第一代:LDA
参数服务器的概念最早来自于 Alex Smola 于 2010 年提出的并行 LDA(Latent Dirichlet Allocation,隐狄利克雷分配模型:是文本挖掘领域(文本主体识别、文本分类以及文本相似度计算等)的一种主题模型,它可以将文档中每篇文档的主题按照概率分布的形式给出,同时它是一种无监督学习,在训练时不需要手工标注的训练集,需要的仅仅是文档集以及指定主体的数据量k即可。简单来说,就是对于每一个主题均可以找出一些词语来描述它) 框架,它采用 Memcached 分布式存储参数,提供了有效的机制用于分布式系统中 Worker 之间同步模型参数,而每个 Worker 只需要保存其计算时所需要的一小部分参数即可。
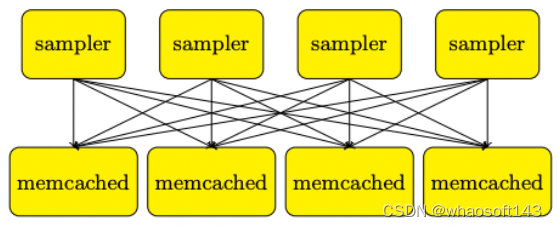
LDA 架构
但是,它缺少灵活性和性能 —— 仅使用 Memcached(key, value) 键值对存储作为同步机制。
第二代:DistBelief
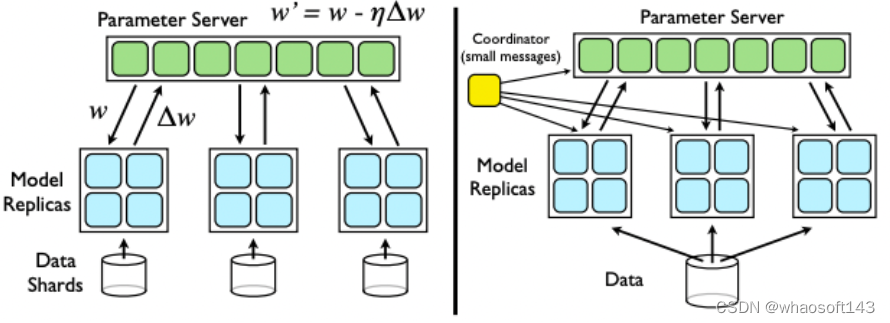
SGD Downpour 架构
2012 年 Google 的 Jeff Dean 发表了《Large Scale Distributed Deep Networks》一文。这篇文章不仅提出了 DistBelief 框架(TensorFlow 前身),还同时基于参数服务器架构(Parameter Server)提出了 Downpour SGD 纯异步模式。在取得性能大幅提升的同时,也有非常不错的效果收益。
实际应用时,TensorFlow 是运行在 Spark上的:Spark Worker 启动单机版的 Tensorflow 异步计算梯度,周期性把梯度发给 Driver,就是参数服务器,在汇总多个Worker的梯度后,参数服务器把梯度数据返回给 Worker。这种方式的并行实现简单,但 Driver(参数服务器)很容易引起网络通信的开销进而影响到伸缩性。
Yahoo 也曾经做过类似的工作:让 Caffe 运行在 Spark 上。
第三代(1):Parameter Server(PS-Lite)
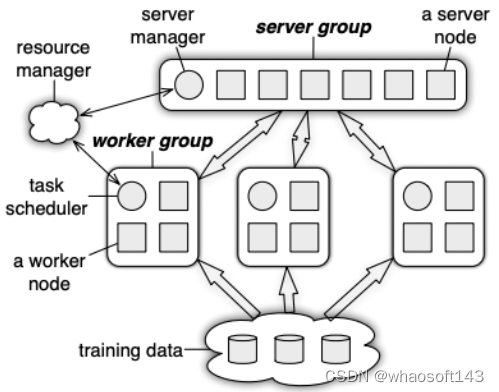
Parameter Server 架构
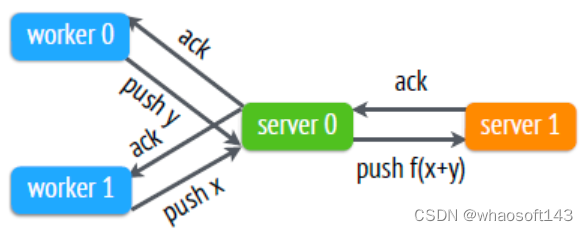
2014 年,李沐所在的 DMLC 组发表了论文《Scaling Distributed Machine Learning with the Parameter Server》,提出了第三代参数服务器架构,相比之前的 DistBelief 提供了更加通用的架构:在设计上包含一个Server Group 和若干个 Worker Group,Server Group 用来做参数服务器,每个Server Node 存放一个参数分片,由 Server Manager 管理整个 Server Group,维持整个 Server Group 的元数据的一致性视图,以及参数分片情况。每个 Worker Group 运行一个应用,Worker Node 只跟 Server Node 通信用来更新参数,Worker Node 之间没有任何交互。每个 Worker Group 内有一个调度器,负责给 Worker Nodes 分配任务以及监控,如果有Worker Node 挂掉或者新加入,调度器负责重新调度剩余的任务。PS-Lite 针对网络带宽的优化主要是针对 Server之间的参数复制提供了采用先聚合再复制的方式:
Replication after Aggregation
Server 之间复制主要是为容错考虑,因此 Worker 和 Server 之间的数据传输仍依赖参数服务器本身异步机制带来的带宽节省:在应用于深度学习时,主要借助于称作 Delayed Block Proximal Gradient 的方法(包括收敛性证明):每次迭代只更新一个 block 的参数;Worker 节点计算梯度的同时还需要计算特定坐标的学习速率,即该 block 的二阶偏导数的对角线。在数据传输时,PS-Lite 还会引入部分定义的 Filter 来避免传输对模型影响不大的参数,例如 Random Skip或者KKT Filter,引入这些Filter可以让传输的模型参数量减少十倍以上。
在 Parameter Server 中,每个 PServer 实际上只负责分到的部分参数(PServer 共同维持一个全局的共享参数,每个 Worker 也只分到部分数据和处理任务)它具有以下优势:
- Efficient Communication:高效的通信。网络通信开销是机器学习分布式系统中的大头,因此 parameter server基本尽了所有的努力来降低网络开销。其中最重要的一点就是:异步通信。因为是异步通信,所以不需要停下来等一些慢的机器执行完一个 iter,这就大大减少了延迟;
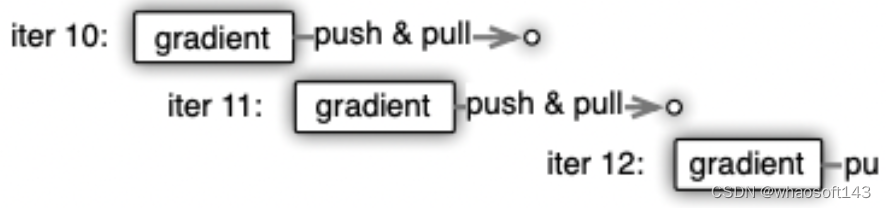
异步 task
它的具体实现:
使用 range vector clock 来记录每个节点参数的时间戳,用来跟踪数据状态或避免数据重复发送。由于参数都是 Range Push/Range Pull,因此同一个 key range 里的参数可以共享一个时间戳,相较于传统的 vector clock 进行了压缩,降低了内存和网络带宽开销。
节点之间通信发送的 message 由 range vector clock 和 <key, value> 对组成。
由于频繁更新模型参数,需要对 message 进行压缩以减少网络带宽开销,Parameter Server 采用两种方法来压缩 message:
key 的压缩:训练数据在迭代时通常不会改变,因此 worker 没必要每次都发送相同的 key lists,server 第一次接收时缓存起来即可,后续只需要发送 key lists 的哈希值进行匹配。
value 的压缩:有些参数更新并非对最终优化有价值,因此用户可以自定义过滤规则来过滤掉一些不必要的参数。例如对于梯度下降,大量 value 为 0 或者很小的梯度是低效的,可以过滤。
异步梯度更新的方式虽然大幅度加快了训练速度,但是带来了模型的一致性丧失,也就是说并行训练的结果与原来的单点串行的训练结果是不一致的,这样的不一致性会对模型的收敛速度造成了一定的影响。所以最终选取同步更新还是异步更新取决于不同模型对于一致性的敏感程度。这类似于一个模型超参数选取的问题,需要针对具体问题进行具体的验证。
bounded delay 模型:设置一个最大延时事件,称之为 staleness 值,允许一定程度的任务进度不一致,即最快的任务最多领先最慢的任务 staleness 轮迭代。因此 staleness = 0 时,即 Sequential 一致性模型(也称 BSP,bulk synchronous parallel,严格同步);当 staleness = ∞ 时,即 Eventual 一致性模型(也称 SSP, staleness synchronous parallel,纯异步)
第三代(2):SINGA 架构
该系统包含若干个 Server Group 和 Worker Group。每个 Server Group 维护完整的模型参数,相邻的 Server Group 定期同步模型参数。每个 Worker Group 负责计算,在数据并行中,每个 Worker Group 负责一个训练数据的分片,所有的 Worker Group 节点跟Server Group之间异步通信,然而在 Worker Group 内部,则是同步处理SINGA值得称道之处在于同时支持数据并行和模型并行,以及混合并行(两种并行的组合),在模型并行时,每个Worker Group 只负责更新部分模型参数。
- Flexible consistency models:宽松的一致性要求进一步减少了同步的成本和延时。并非所有算法都天然的支持异步和随机性,有的算法引入异步后可能收敛会变慢,因此 parameter server 允许算法设计者根据自身的情况来做算法收敛速度和系统性能之间的权衡 trade-off;

- bounded delay
- Elastic Scalability:使用一致性哈希算法,分布式的 hash 表,使得新的 PServer 可以随时动态插入集合中,无需重启训练任务;
- Fault Tolerance and Durability:节点故障是不可避免的。在本文中,对于 PServer 节点来说,使用链备份来应对;而对于 Worker 来说,因为 Worker 之间互相不通信,因此在某个 Worker 失败后,新的 Worker 可以直接加入。Vector clocks 保证了经历故障之后还是能运行良好;
- Ease of Use:全局共享的参数可以被表示成各种形式:vector、matrices 或是 sparse类型,同时框架还提供对线性代数类型提供高性能的多线程计算库。
- Vector Clock
- Messages
- 在数据一致性上使用一致性哈希算法,参数 key 和 server id 被插入到哈希环中,有两种方式保证了主节点和备份节点之间的数据一致性:
- Chain Replication
- Repiication after Aggregation
- Server 管理
- 添加 server:server manager 给新 server 分配 key range,其他 server 的 key range 做出相应更改;新 server 获取作为主 server 维护的 key range 和作为从 server 维护的 k 个 key range;server manager 广播节点的更改;
- 删除 server:当 server manager 通过心跳信号发现 server 出现故障后,会将该 server 的 key range 分配给新的 server,并删除该 server
- Worker 管理
- 添加 woker:task scheduler 给新 worker 分配数据;该新 worker 载入训练数据,然后从 server 获取参数;task scheduler 广播节点的更改,可能造成其他 worker 释放部分训练数据
- 删除 woker:丢失小部分训练数据通常并不会影响模型训练结果,此外恢复一个 worker 比 server 需要更多的开销。因此删除 worker 通常是直接不管该节点,可以用于终止最慢的 worker,减缓 Straggler 带来的性能影响。当然用户也可以选择用新 worker 来替代丢失的 worker。
- 异步任务
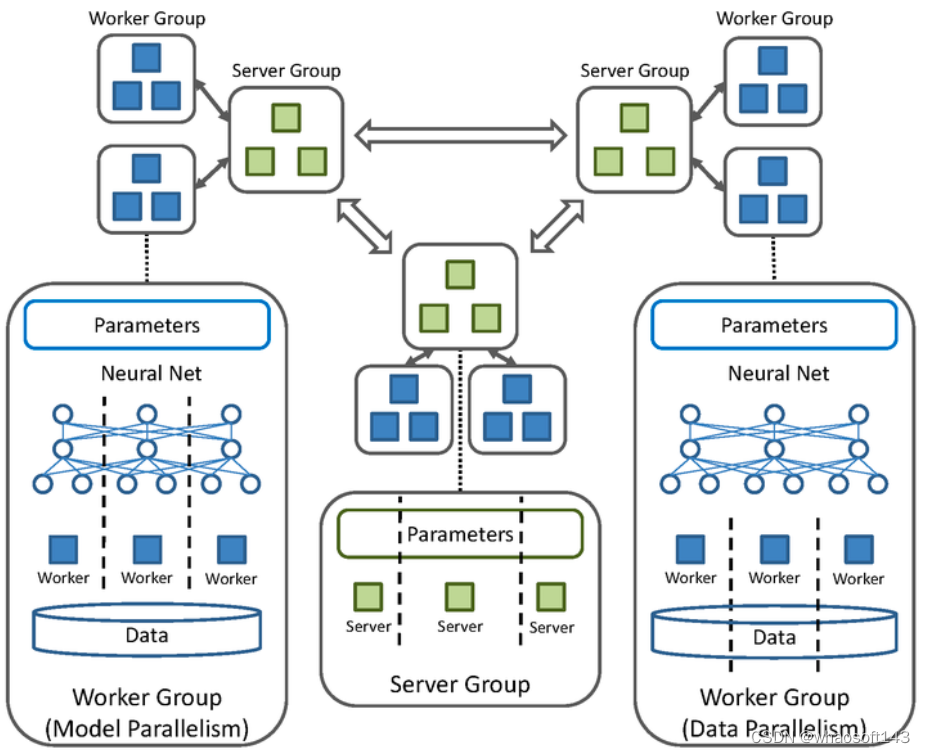
SINGA 的架构非常灵活,可以根据需要满足不同模式的分布式计算,除了类似 DownpourSGD 的结构之外,还可以配置成 AllReduce,Sandblaster,Distributed Hogwild 等不同范式。
在采用 SINGA 训练深度学习模型时,需要根据模型特点决定如何采用数据并行和模型并行,从而减少网络带宽造成的瓶颈,例如选取具有低维特征的神经网络层作为 Worker Group 的边界,减少 Worker 之间的数据传输;选取神经网络层之间依赖小的部分应用模型并行等。凭借多样化的并行机制。
第三代(3):CNTK
微软的 CNTK 只提供数据并行,它采用参数服务器模型实现了一种称为 1-Bit Quantized SGD 的算法,其目的就是用于节约带宽,其主要思想是压缩梯度的表示到只用 1bit,把残差带到下一次的 minibatch 中。相比用浮点数(32位)表示梯度值,1-Bit SGD 相当于节约了 30 多倍的传输带宽。
第三代(4):Poseidon
这来自 CMU 另一个机器学习研究小组 Eric Xing 教授的项目 Petuum。
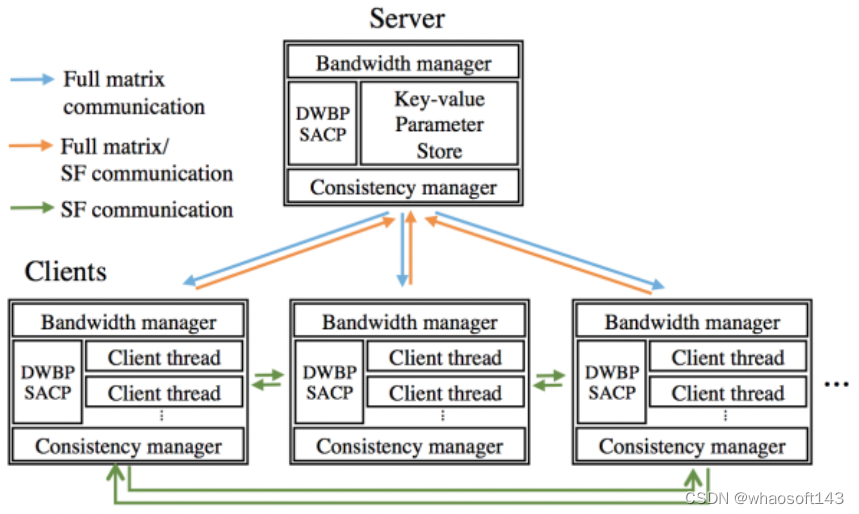
上图中的 Server 就相当于 DownpourSGD 的 Master,Clients 则相当于 Worker。与 DownpourSGD 相比,Poseidon 差异在于:首先,在每个 Worker 节点上增加了额外的一层,允许单节点运行多个线程任务,这主要是针对多 CPU 核和多 GPU 卡的设计,方便任务线程绑定到 1 个 CPU 核或者 1 张 GPU 卡。其次,Poseidon 不仅允许 Master 和 Worker 之间的参数更新,还允许不同的 Worker 之间通信。为了减少网络开销,Poseidon 做了如下工作:
- 引入Wait-free BP算法。BP 算法是神经网络里最基本的算法,在后向传播过程中,误差信息从神经网络的顶层一直传播到底层。每次迭代,每个 Worker 分别进行BP算法,只有当传播到达底层时,每个 Worker 才开始通信,把本地的参数更新发送到 Master 然后等待 Master 聚合各节点梯度后返回。以下图来表示如下,其中 push 和 pull 就是跟参数服务器 Master 之间的交互。
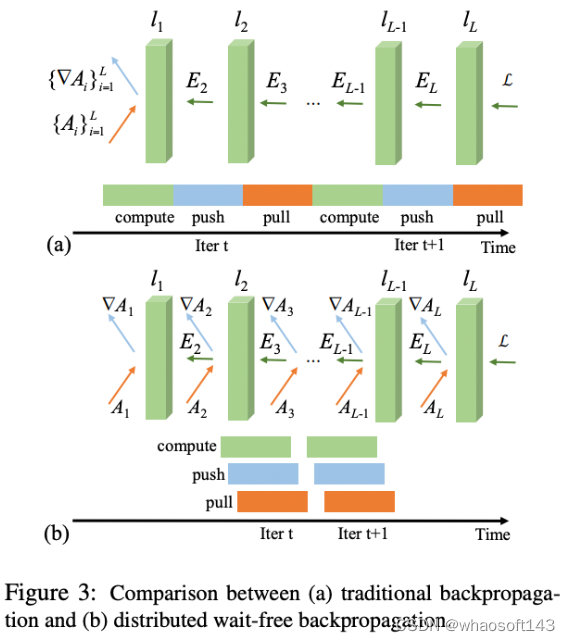

2. 引入SACP(Structured-Aware Communication Protocol)协议。这个协议一看名字就是专门针对带宽消耗设计的。该协议是专门针对矩阵型参数的机器学习模型来设计的——深度学习的参数就是典型的矩阵结构。以AlexNet 为例,两个 FC 全连接层 FC6 和 FC7 之间的参数权重就是个 4096*4096 的矩阵。每次迭代时,都需要在Master 和 Worker 之间交换这样 2 个矩阵。随着模型和集群的增大,交换的参数矩阵会更加庞大。为减少带宽消耗,首先,Poseidon 引入 Worker 之间的通信,称为 SFB(Sufficient Factor Broadcasting)。在 Worker 和Master 之间传递的矩阵参数 ∇W,可以通过矩阵分解写为 ∇W =uv',u,v' 就是所谓 Sufficient Factor,而 u,v' 可以通过直接从 Worker 节点之间的通信中获得,通过把矩阵转化为向量,减少了通信开销。随着集群节点的增多,这种手段也会带来副作用,因为 P2P 通信的成本会上升。
基于此 Poseidon 提出了 SACP 协议本身,这是一个混合 Master/Worker 之间通信和 SFB 的方案,它会动态决定是选取前者还是后者来进行参数交换,因此,在前边的Poseidon框图里我们看到了Bandwidth Manager,就是起这个作用。
因此,从设计上,我们可以看到基于 Petuum 的 Poseidon 为网络带宽消耗做了大量优化。在随后 Eric Xing 团队的进一步的工作中又提出了专门针对 GPU 集群的参数服务器,其目的主要在于让参数服务器更有效利用 GPU 显存。
第四代:百花齐放
随着深度学习的研究越来越深入,它的应用场景越来越广泛,模型种类越来越多,模型规模越来越大。各个厂商开始将参数服务器广泛应用到自家的业务上,也对参数服务器在功能、易用性、性能上做了各种各样的改进。
- 2017 年 Uber 开源了 Horvod,它以 Tensorflow 为基础,CPU PS 并无什么特色,GPU PS 采用了百度的 Tensorflow ring-allreduce 算法实现,它最大的特点是弹性:包括节点发现、容错、Worker 生命周期管理。
- 2017 年腾讯基于 Angel 的 LDA* 对传统的 LDA 进行了两个针对性优化,使得它有广泛的适用性和良好的性能,成为一个大规模的高性能主题模型系统:
- 吉布斯采样(Hybrid Sampler)
- 非对称架构:将一部分长尾词语的采样推送到 PServer 端进行,从而避免了对词 - 话题矩阵的拉取操作。由于在这样的架构中,PSServer 不仅仅作为一个分布式存储,还参与了一定的计算任务,从而某种程度上实现了模型并行。
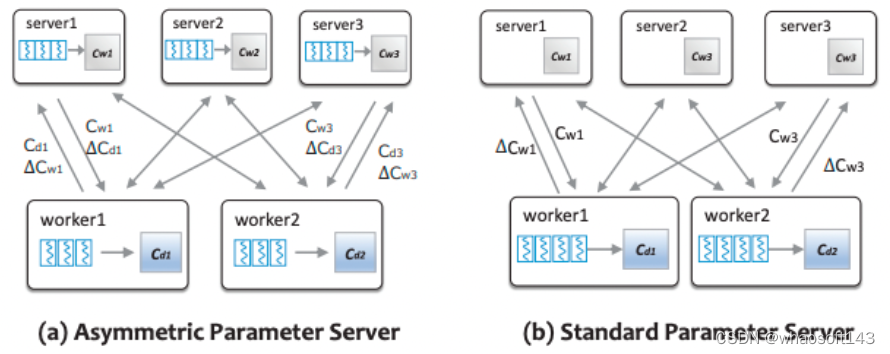
非对称参数服务器
- 2018 年阿里以 tensorflow 为基础,针对高纬稀疏场景问题做了个适配,开源了 X-Deep Learning 系统。它有如下几点特色:
- IO 优化:多项前缀树(在商业场景中,不同的训练样本有很多重复的特征,例如,用户在同一屏的多条曝光记录,item 不同,但是 use r特征是相同的)
- pipeline:XDL 每一轮迭代可以分为三个阶段:第1阶段,读取训练样本,并转化为 mini-batch;第2阶段,PServer 侧预先抓取参数索引;第3阶段,Worker 拉取模型参数,进行前后向的计算。为了加快训练速度,提升吞吐率,XDL 通过多线程技术,将相邻的迭代中不同的阶段在时间上重叠起来。
- 特征准入和淘汰(样本准入和淘汰)
- Facebook 在 2019 年发表了一篇论文讲DLRM模型《Deep Learning Recommendation Model for Personalization and Recommendation Systems》。它基于 pytorch 和 caffe2 实现。在 embedding table的模型并行模式上实现了一种特殊的并行范式(butterfly shuffle)。同时,这篇论文将这种并行模式运行在Facebook 的超级 AI 计算机 Big Basin 平台上。
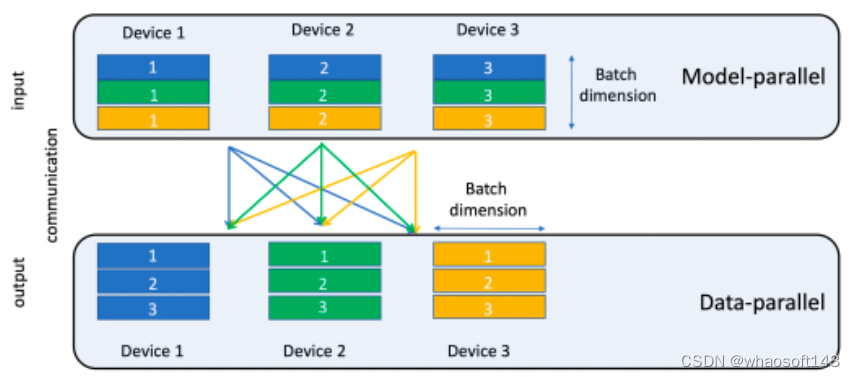
- 蝶形 shuffle
- 2019 年阿里推出 PAI Tensorflow(阿里云优化的商业版 Tensorflow),它支持的功能包括:静态特征回填(新上线特征);实时样本拼接;embedding variable 功能。这个功能提供动态的弹性特征的能力。每个新的特征会新增加一个 slot。并支持特征淘汰,比如说下架一个商品,对应的特征就会被删掉;实时训练模型校正;模型回退及样本回放。
- 2019 年字节跳动开源 BytePS,它继承了许多加速技术,比如分层策略、流水线、张量分区、NUMA 感知本地通信、基于优先级的调度等等。还提出了 BytePS ring-allreduce 方案:一是引入 CPU 节点,用于 ReduceScatter 操作;二是 ReduceScatter 和 AllGather 异步执行,从而缩短了数据传输时间开销。本质上还是通过引入 CPU Server,相当于额外增加一张网卡。
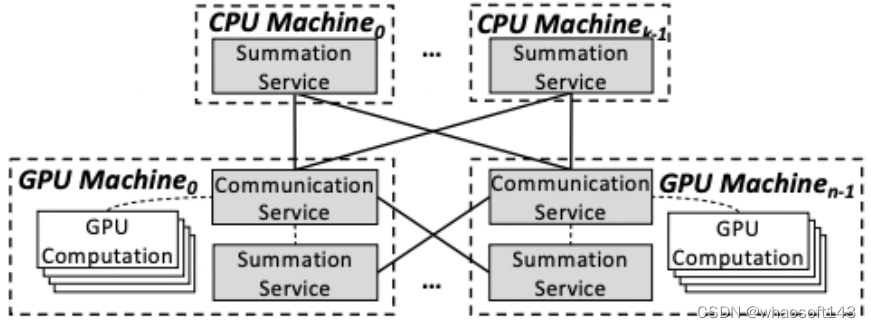
BytePS 架构
- 2020 年 360 公司开源了 TensorNet,该系统是针对 tensorflow 开发的轻量级 PS,支持 tf2.2 及以后的版本,TensorNet 能支持到百亿特征规模,它通过引入 virtual sparse feature,由原来直接从 parameter server 查找稀疏特征变为二级查找。TensorNet将每个batch 的特征 ID 从 0 开始重新编排作为输入,这样输入特征的 index 分布在 [0, 1024) 之间;同时根据原始的特征 ID 从 server 拉取对应的 embedding 向量,填充到 tensorflow 的 embedding 矩阵中,这样每个特征 field/slot 的 embedding 矩阵大小就只有 1024 x embedding_size.
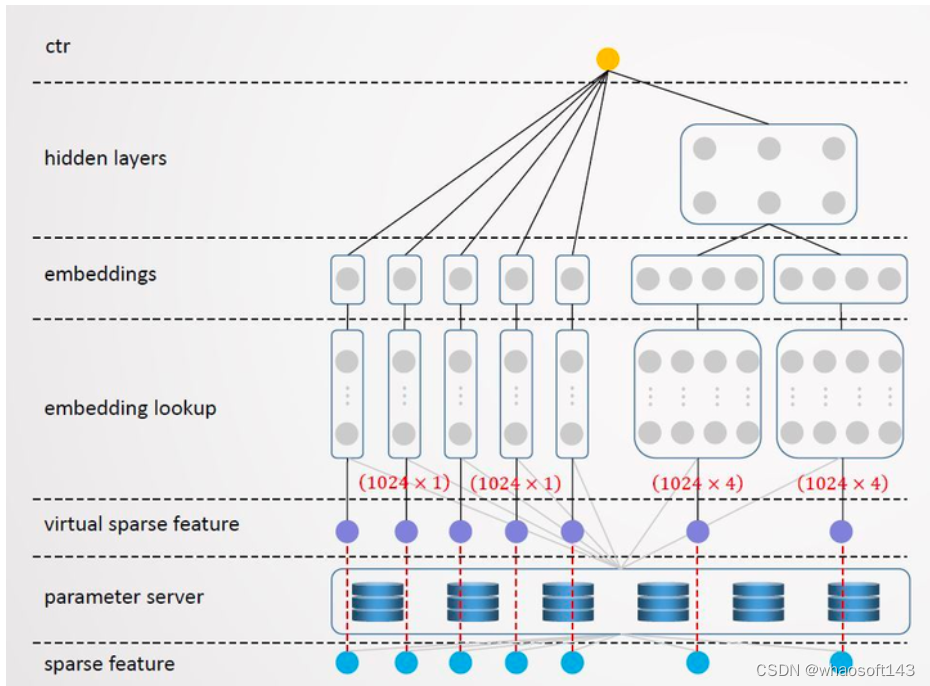
TensorNet
- 2021 年美团公开发布了它们在分布式训练优化这块的一些实践,它基于 tensorflow1.x 接口,具体有以下几点:
- 将所有稀疏参数和大的稠密参数自动、均匀的切分到每个 server 上
- 通信优化:采用 RDMA 通信方式,使用 RoCE V2 协议优化
- 只对那些涉及到跨节点通信的 Tensor 进行 Memory Regisitration,其余 Tensor 并不注册到 MR
- RDMA静态分配器
- Multi RequestBuffer 与 Completion Queue 负载均衡优化
- Send-Driven & Rendezvous-Bypass
- 稀疏域参数聚合
- 选用高性能 tbb::concurrent_hash_map
- 改造了 tensorflow 原生算子:Unique 和 Dynamic Partition 算子
- 2021年,Facebook 又推出了针对深度学习推荐模型(DLRM)的高性能分布式训练框架,它是一种基于 PyTorch 的高性能可扩展软件栈,并将其与 Zion 平台的新改进版本 ZionEX 配对。它能训练具有多达12万亿个参数的超大型DLRM的能力,并表明与以前的系统相比,时间上实现40倍的加速。具体手段包括:(i)设计具有专用横向扩展网络,配备高带宽,最佳拓扑和高效传输的ZionEX平台来实现这一目标(ii)实施支持模型和数据并行性的基于PyTorch的优化训练堆栈(iii)开发分片能够按行,列维度对嵌入表进行分层划分并在多个工作程序之间实现负载均衡的算法;(iv)增加高性能的核心运营商,同时保留灵活性,以通过完全确定的更新来支持优化器(v)利用降低的精度通信,多层内存层次结构(HBM + DDR + SSD)和流水线技术。此外,还针对在生产环境中进行强大而有效的端到端培训所需的分布式数据摄取和其他支持服务进行了开发。
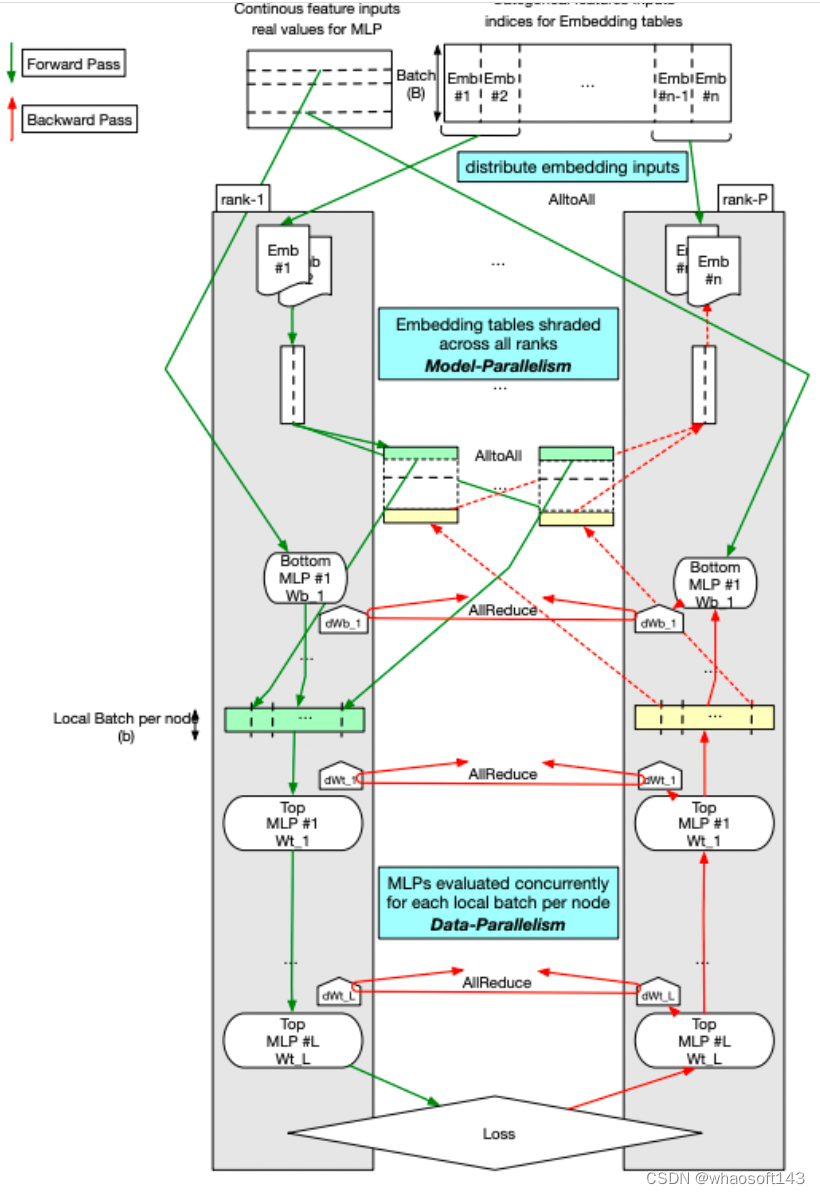
DLRM 高性能弹性训练架构
5、百度飞桨开源参数服务器框架
从参数服务器的发展历程可以看出,大部分厂商都是在 tensorflow 或者 pytorch 提供的原生分布式训练框架基础上,要么改造,要么实现了一个新的 PServer,它们并没有自家的深度学习框架。而促进参数服务器不断升级、优化、发展则取决于四大要素:
- Worker 端能力
- PServer 端能力
- 业务场景丰富性及功能验证
- AI 硬件(芯片)
而百度同时具备这四大要素,这是它天然的优势。PaddlePaddle(飞桨)开源的参数服务器支持四种模式:CPUS PS、GPU PS、Heter PS 和 Pipeline PS,其特色有:
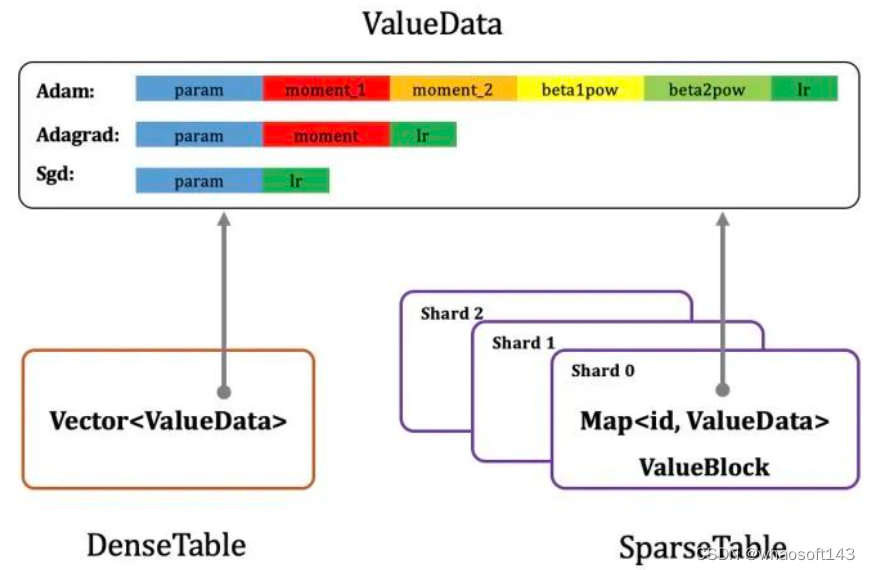
Paddle PS 存储设计
- 通用的大规模离散模型训练框架,支持多种业务场景
- 支持同步、异步、Geo 三种通信方式
- 相比 Byte-PS、美团 PS 中创建各种 PUSH、PULL Queue 的方式,Paddle PS 支持异步 Task 模式(更高效流水线架构),减少了线程间通信开销,效率更高
- 支持 Worker 端参数 key 各种 merge 操作,降低 Worker 和 PServer 之间通信频率
- 支持 SSD、HBM、MEM、PMEM 等多级存储结构及高效访存(软、硬件创新)
- 针对大规模稀疏参数和稠密参数,分别定义对应的 Table 类型及高效的 Table 访问(Accessor)方式
- 支持线上流式训练
- 数据读取支持 graph db、kafka、tfrecord、odps 等各种数据源
- 支持多种 AI 芯片,如 GPU、华为昇腾、百度昆仑等
- 丰富的指标计算模块
- 支持特征准入、特征淘汰
- 在网卡拓扑、通信协议等方面进行了软硬件一体的整体设计,超高的多机通信效率
- 支持 debug 单特征/组合特征重要度、输入样本聚合、分 tag(ins)打印 auc、定制化的优化器、支持变长 embedding 等
- 百度自研的高效 brpc 通信
- 等等
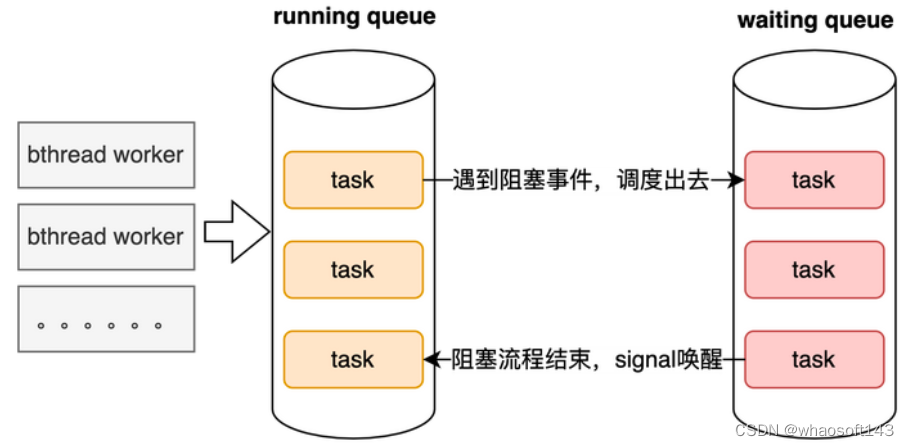
异构参数服务器异步task模式
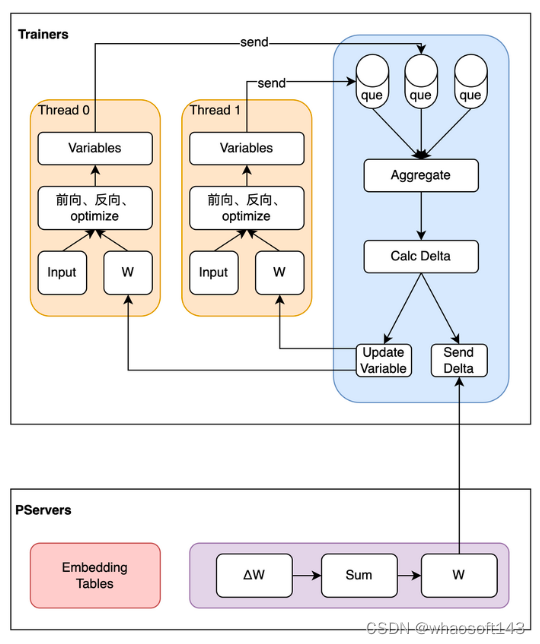
Geo 异步训练模式
目前百度在广告/推荐/推荐/电商场景中都是使用 PaddlePaddle 做训练和预估,离线训练也是在多机上做 PS 分布式训练。
在工业场景中部署 PS 时,要利用 K8S 在集群上进行调度。先是将训练所依赖的 PaddlePaddle 环境打包成镜像,存放在镜像仓库中,如果训练环境升级,只需要打包新的镜像,并在训练开始之前指定相应的镜像即可,环境的管理比较方便。每次训练的时候,将所需镜像下载到多个物理机上,然后在物理机上创建容器,并配置环境变量,在容器中创建 Worker 和 PServer 进程开始训练。
每台物理机上有一个 Worker 进程,每个 Worker 进程会创建几十个线程,所有线程同时从 hdfs 上读取数据并进行前后向计算,所有线程各自跑各自的,互不依赖。另外,每台物理机上至少有一个 PServer 进程,具体进程数取决于模型的大小。PServer 和 Worker 部署在一起,减少了跨物理机之间的通信,也是为了降低通信成本;另外 PServer 偏内存型任务,主要消耗内存,Worker 偏计算型任务,主要消耗 CPU,部署在一起也有利于提高资源利用率。
6、下一代分布式训练框架:Pathways
PServer 端将支持多种参数管理策略;每个 Worker 和 PServer 都将是一个无状态的服务,可以更加方便地进行容错和弹性扩缩容;结合 Paddle 框架自动并行能力,能够感知全局的存储、计算和通信能力,并按照最优策略自动执行任务切分和放置;可以应用框架本身的各种优化的 pass 策略,最大程度加快计算图的执行速度。















 1280
1280

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









