








©PaperWeekly 原创 · 作者 | 避暑山庄梁朝伟

背景
随着 ChatGPT 的火爆出圈,大模型也逐渐受到越来越多研究者的关注。有一份来自 OpenAI 的研究报告 (Scaling laws for neural language models) 曾经指出模型的性能常与模型的参数规模息息相关,那么如何训练一个超大规模的 LLM 也是大家比较关心的问题,常用的分布式训练框架有 Megatron-LM 和 DeepSpeed,下面我们将简单介绍这些框架及其用到的技术。

基础知识
在介绍这些和框架和技术之前先介绍一下设计分布式训练的基本知识。
1)通讯原语操作
NCCL 英伟达集合通信库,是一个专用于多个 GPU 乃至多个节点间通信的实现。它专为英伟达的计算卡和网络优化,能带来更低的延迟和更高的带宽。
a. Broadcast: Broadcast 代表广播行为,执行 Broadcast 时,数据从主节点 0 广播至其他各个指定的节点(0~3)。
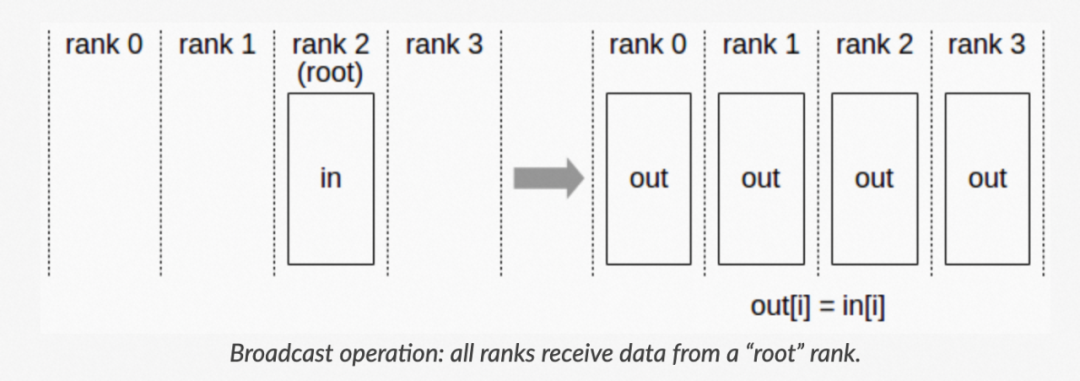
▲ Broadcast
b. Scatter: Scatter 与 Broadcast 非常相似,都是一对多的通信方式,不同的是 Broadcast 的 0 号节点将相同的信息发送给所有的节点,而 Scatter 则是将数据的不同部分,按需发送给所有的节点。
c. Reduce: Reduce 称为规约运算,是一系列简单运算操作的统称,细分可以包括:SUM、MIN、MAX、PROD、LOR 等类型的规约操作。Reduce 意为减少/精简,因为其操作在每个节点上获取一个输入元素数组,通过执行操作后,将得到精简的更少的元素。
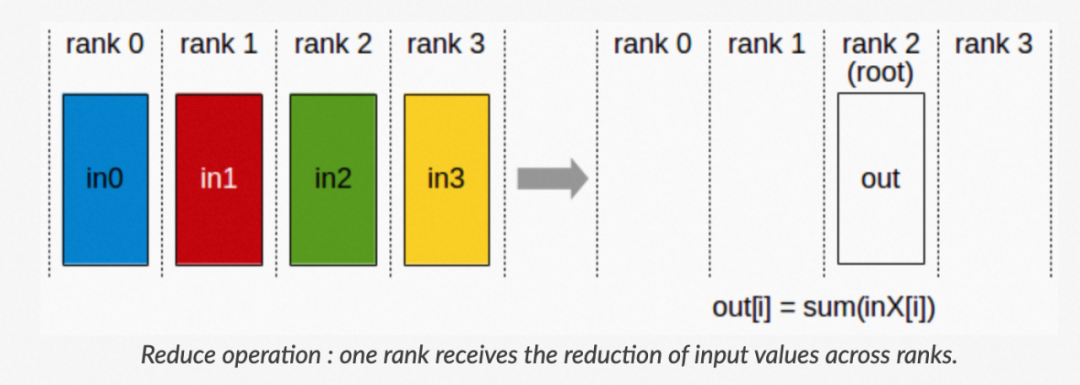
▲ Reduce
d. AllReduce: Reduce 是一系列简单运算操作的统称,All Reduce 则是在所有的节点上都应用同样的 Reduce 操作。

▲ AllReduce
e. Gather: Gather 操作将多个 sender 上的数据收集到单个节点上,Gather 可以理解为反向的 Scatter。
f. AllGather: 收集所有数据到所有节点上。从最基础的角度来看,All Gather 相当于一个 Gather 操作之后跟着一个 Broadcast 操作。
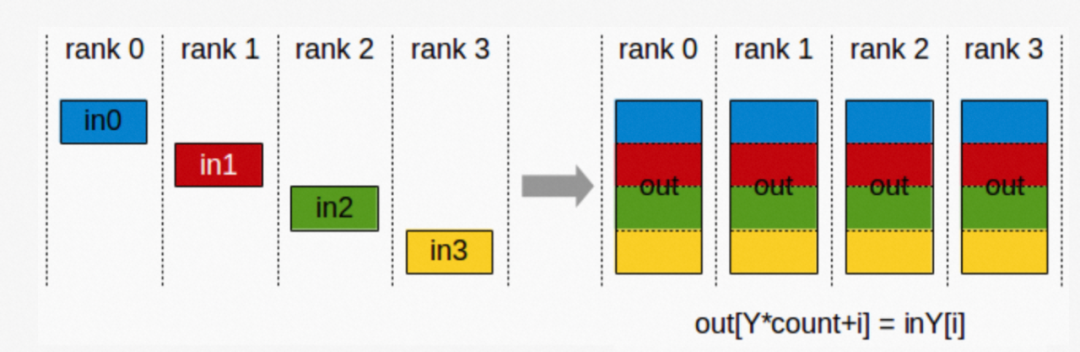
▲ AllGather
g. ReduceScatter: Reduce Scatter 操作会将个节点的输入先进行求和,然后在第0维度按卡数切分,将数据分发到对应的卡上。

▲ ReduceScatter
这里多说一下 AllReduce 操作,目标是高效得将不同机器中的数据整合(reduce)之后再把结果分发给各个机器。在深度学习应用中,数据往往是一个向量或者矩阵,通常用的整合则有 Sum、Max、Min 等。AllReduce 具体实现的方法有很多种,最单纯的实现方式就是每个 worker 将自己的数据发给其他的所有 worker,然而这种方式存在大量的浪费。
一个略优的实现是利用主从式架构,将一个 worker 设为 master,其余所有 worker 把数据发送给 master 之后,由 master 进行整合元算,完成之后再分发给其余 worker。不过这种实现 master 往往会成为整个网络的瓶颈。
AllReduce 还有很多种不同的实现,多数实现都是基于某一些对数据或者运算环境的假设,来优化网络带宽的占用或者延迟。如 Ring AllReduce:
第一阶段,将 N 个 worker 分布在一个环上,并且把每个 worker 的数据分成 N 份。
第二阶段,第 k 个 worker 会把第 k 份数据发给下一个 worker,同时从前一个 worker 收到第 k-1 份数据。
第三阶段,worker 会把收到的第 k-1 份数据和自己的第 k-1 份数据整合,再将整合的数据发送给下一个 worker。
此循环 N 次之后,每一个 worker 都会包含最终整合结果的一份。假设每个 worker 的数据是一个长度为 S 的向量,那么个 Ring AllReduce 里,每个 worker 发送的数据量是 O(S),和 worker 的数量 N 无关。这样就避免了主从架构中 master 需要处理 O(S*N) 的数据量而成为网络瓶颈的问题。
2)并行计算技术
a. 数据并行
DP (Data Parallel):本质上是单进程多线程的实现方式,只能实现单机训练不能算是严格意义上的分布式训练。步骤如下:
首先将模型加载到主 GPU 上,再复制到各个指定从 GPU;
将输入数据按照 Batch 维度进行拆分,各个 GPU 独立进行 forward 计算;
将结果同步给主 GPU 完成梯度计算和参数更新,将更新后的参数复制到各个 GPU。
主要存在的问题:
负载不均衡,主 GPU 负载大
采用 PS 架构通信开销大
分布式数据并行 DDP (Distribution Data Parallel):采用 AllReduce 架构,在单机和多机上都可以使用。负载分散在每个 GPU 节点上,通信成本是恒定的,与 GPU 数量无关。
b. 张量并行:分布式张量计算是一种正交且更通用的方法&#x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2183
2183











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









