







目录
源文件下载
可访问底部联系方式也可前往电子校园网官网搜索关键词
关键词: TTS语音输出
一、实物图

二、原理图
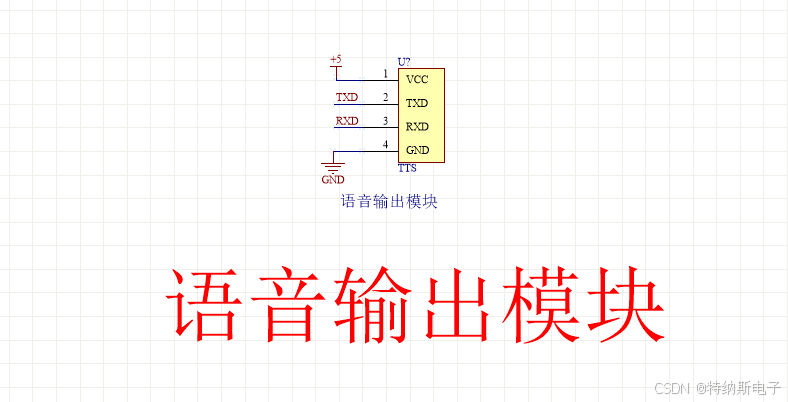
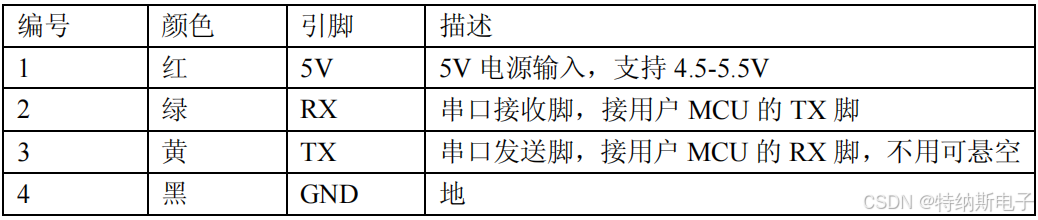
引脚定义
三、简介
TTS(Text-to-Speech)是一种将文本内容转换成语音的技术。它允许计算机能够将书面文字转换为可听的人类语音,从而为用户提供更多选择和灵活性。TTS技术采用自然语言处理、数字信号处理和语音合成等技术,将电子文字转化为口头发音,并通过扬声器、耳机或其他设备播放出来。
基本原理
我们用的是CN-TTS,是一款高集成度的语音合成模块,可实现中文、英文、数字的语音合成;并且支持用户的命令词或提示音的定制需求。CN-TTS 控制方式简单,是通过 TTL 串口发送 GBK 编码的形式,可兼容市面上主流 5V 或 3.3V 单片机,其基本原理与TTS技术相似,但在中文语音合成方面又有所不同。下面介绍CN-TTS的基本原理:
- 分词:首先会将输入文本进行分词处理,将整段话切分为单个词语。
- 语音预测模型:构建文字到语音的映射模型,这是将文本转换为语音的关键步骤。这个模型包含两个部分:音素的概率模型和声学模型。其中音素概率模型会根据输入的文本中每个字的上下文信息来预测该字对应的音素序列;声学模型则用于计算每个音素的声音特征,并将其转化成语音信号。
- 韵律特征融合:在输出语音序列之前,需要将音素序列转化成实际的语音,同时还需要根据输入文本的韵律模式来调节声音的音高、音量和语速等特征。为了实现这些调节,CN-TTS通常采用基于机器学习方法的韵律特征融合技术,也就是把韵律和声讯特征结合起来,使其达到更好的人类听感效果。
- 语音合成输出:最后将经过处理的声学特征转化为模拟声波信号,再将其输出到扬声器或耳机中播放出来。
综上所述,CN-TTS技术通过分词、语音预测模型和韵律特征融合等步骤,将中文文本转换成口头发音,并输出到硬件设备上。这种技术已经被广泛应用在各种语音交互场景中,例如自然语言对话系统、智能语音助手、虚拟主持人等。
功能描述
- 支持任意中文、英文字母、阿拉伯数字的文本合成,并且支持中文、英文字母、数字的混读。
- 模块支持中文 GBK 编码集;支持大、小写英文字母。
- 模块采用 UART 通讯方式UART 串口支持9600bps,发什么报什么,简单易用。
- 支持状态显示用户的控制器能够清楚地了解模块是否正在合成播报,还是空闲状态。
模块使用
- 语音合成
这个模块连接的是串口,在用单片机控制时,波特率设置为9600,直接用串口发送想要播报的内容,如:printf(“大家好”);模块就会播报“大家好”。
- 音效播报控制
内置8种音效,编号为0-7,代码如:printf(“<Z>0”); 播报编号为0的音效
- 音量设置
可设置1-4级音量,代码如:printf(“<V>3”);设置音量为3。系统默认为 4,为最高音量。
- 语速设置
可设置 1-3 级语速,代码如:printf(“<S>3”); 设置语速为 3。系统默认为 2,为中速。
- 设置上电提示
发送”<I>1”开启上电音效提示,”<I>0”则关闭上电音效提示。系统默认开启。
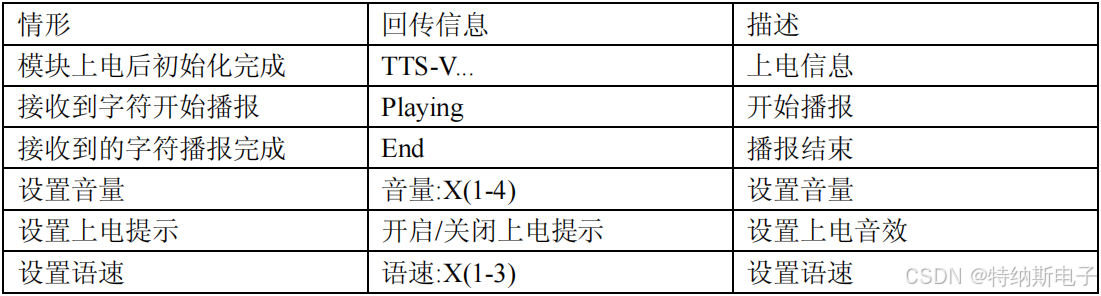
- 模块回传模块在不同情形下通过 TX 脚向用户 MCU 发送不同的回传信息。
四、结构尺寸
接口:1*4P 连接线。
长*宽*高:31*27.5*15mm
线长:80mm
五、注意:
可驱动喇叭功率(典型):4 欧 3 瓦、8 欧 1.5 瓦、16 欧 1 瓦。若要驱动更高功率喇叭,需外接有源功放。
模块套件内是带有一个喇叭的。


















 5753
5753

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











