







音频分离(Audio Separation)是指从混合音频信号中提取并分离出各个独立的音频源的技术。这项技术在音乐制作、语音增强、视频编辑、语音识别等多个领域具有广泛的应用前景。
- 技术原理与方法
音频分离技术的核心在于通过算法从复杂的音频混合信号中识别和提取出各个独立的声音源。传统方法包括谱减法、独立成分分析(ICA)、非负矩阵分解(NMF)等,但这些方法往往存在信号失真或需要大量数据训练的问题。近年来,深度学习技术的引入显著提升了音频分离的精度和效率。例如,卷积神经网络(CNN)、递归神经网络(RNN)、生成对抗网络(GAN)等深度学习模型被广泛应用于音频分离任务中,能够自动学习音频特征并实现高效的分离。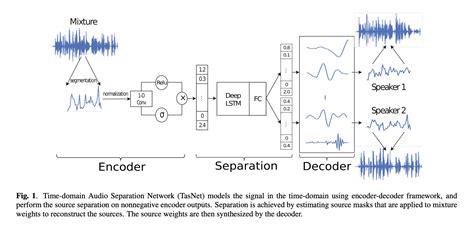
- 多模态融合与视觉引导
为了进一步提高音频分离的准确性和鲁棒性,一些研究开始结合多模态信息,如将音频与视频数据结合进行分离。例如,SeCo模型通过结合视觉和听觉信息来增强音频分离的效果,而CLAPSep则利用对比预训练模型从多通道音频中提取目标声源。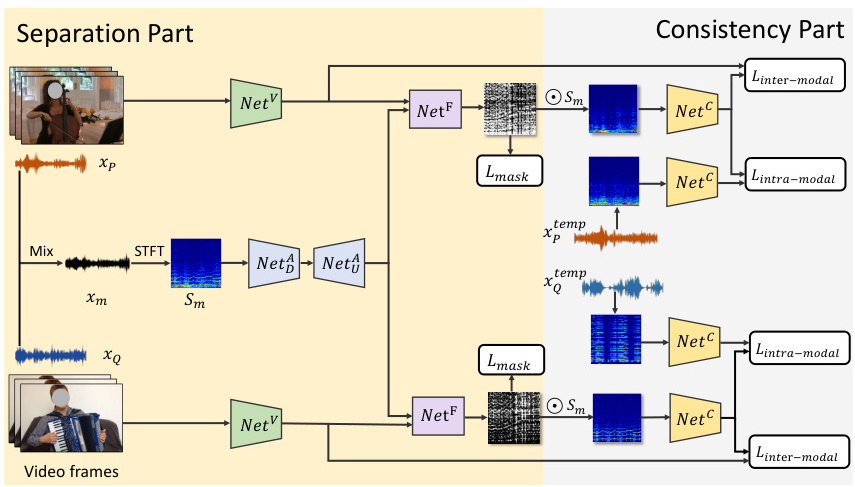

此外,基于场景图的音频-视觉动态学习方法也展示了通过视觉引导来分离音频信号的潜力。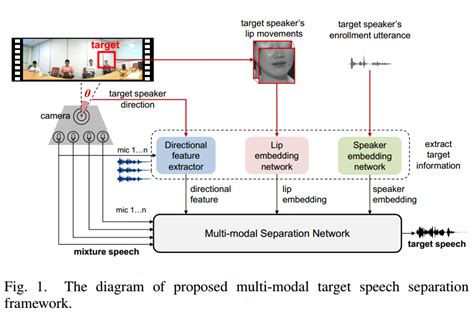
- 应用场景
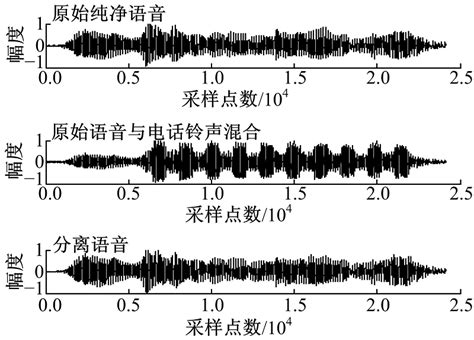
音频分离技术在多个领域展现出广泛的应用潜力。在音乐制作中,它可以帮助音乐制作人将乐器声音和人声分开,从而提高创作效率和音质。在语音增强领域,音频分离可以用于改善通话质量,通过分离人声和背景噪音,使通话更加清晰。此外,音频分离还被应用于视频编辑、音频修复、文化遗产保护等领域。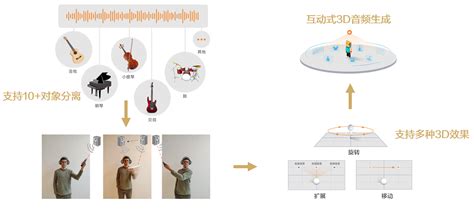
- 未来发展趋势
随着人工智能和深度学习技术的不断发展,音频分离技术正朝着多源分离、实时性、低延迟以及个性化处理方向发展。未来的研究可能会更加注重跨模态信息的融合、自适应技术的应用以及计算资源的优化,以实现更高效和智能的音频分离解决方案。</
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1141
1141

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











