







MMLU(Massive Multitask Language Understanding,大规模多任务语言理解)是一个广泛应用于评估大型语言模型(LLM)能力的基准测试工具。它由斯坦福大学的研究人员开发,旨在全面测试模型在多个学科和任务中的知识掌握和问题解决能力。
MMLU的主要特点:
- 覆盖范围广泛:MMLU包含57个主题,涵盖基础数学、美国历史、计算机科学、法律、伦理等多个领域,难度从初级到高级不等,适用于不同水平的测试。
- 评估方式:MMLU采用多项选择题的形式,要求模型从多个选项中选择最正确的答案。其评分标准基于模型在所有学科中正确回答的比例,分数范围从0到100%。
- 应用场景:MMLU被广泛用于评估和比较不同语言模型的能力,例如OpenAI的GPT系列、Claude-3等。此外,它也被用于教育技术、机器翻译系统优化以及跨文化交流等领域。
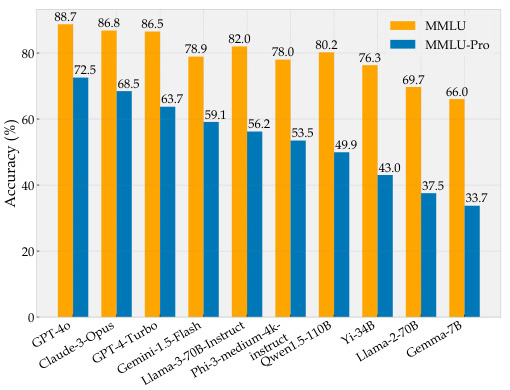
- 改进版本:为了应对传统MMLU在某些问题上的局限性,研究者推出了MMLU-Pro版本,增加了问题的复杂性和真实性,同时提高了评分标准。
MMLU的使用方法:
- 零样本(Zero-shot)和少样本(Few-shot)测试:MMLU支持零样本和少样本两种测试模式。在零样本模式下,模型仅依赖其预训练的知识;而在少样本模
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 4963
4963

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











