







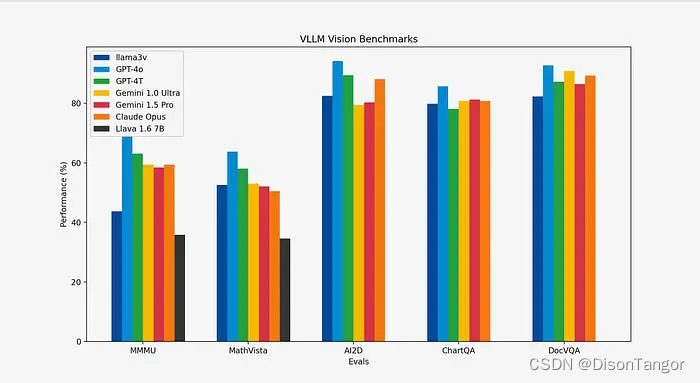
近期在Huggingface上,一个来自斯坦福的研究团队发布了一个能够“改变现状”的产品:Llama3-V,号称只要 500 美元(约为人民币 3650 元),就能基于 Llama3 训练出一个超强的多模态模型,效果与 GPT4-V、Gemini Ultra 、 Claude Opus 多模态性能相当,但模型小 100 倍。
Github 项目链接:https://github.com/mustafaaljadery/llama3v(已删库)
HuggingFace 项目链接:https://huggingface.co/mustafaaljadery/llama3v(已删库)
用这么少的成本,创造出了如此惊艳的成果,Llama3-V 在Twitter上迅速爆火,浏览量突破 30 万,转发超过 300 次,还冲上了“ HuggingFace Trending ”Top 5。
但是随着越来越多的学者争相下载研究后,发现Llama3-V 项目中有一大部分似乎窃取了清华大学自然语言处理实验室与面壁智能合作开发的多模态模型 MiniCPM-Llama3-V 2.5。
而此前 MiniCPM-Llama3-V 2.5 就已经成功超越了同系列的Llava-next,并且其多模态综合性能超越 GPT-4V-1106、Gemini Pro、Claude 3、Qwen-VL-Max 等商用闭源模型。OCR 能力及指令跟随能力进一步提升,并支持超过 30 种语言的多模态交互。这样的优秀性能,不仅让 MiniCPM-Llama3-V 2.5 成为受大家推崇的模型,或许也成为了 Llama3-V 的“模仿”对象。
项目地址:https://github.com/OpenBMB/MiniCPM-V/blob/main/README_zh.md

在这个 Issue 中,他首先提出,Llama3-V 与 MiniCPM- Llama3-V 2.5 具有相同的模型结构和配置文件,只是变量名不同。Llama3-V 的代码几乎完全照抄 MiniCPM-Llama3-V 2.5,只是进行了一些格式上的修改,包括但不限于分割图像、tokenizer、重采样器和数据加载部分。
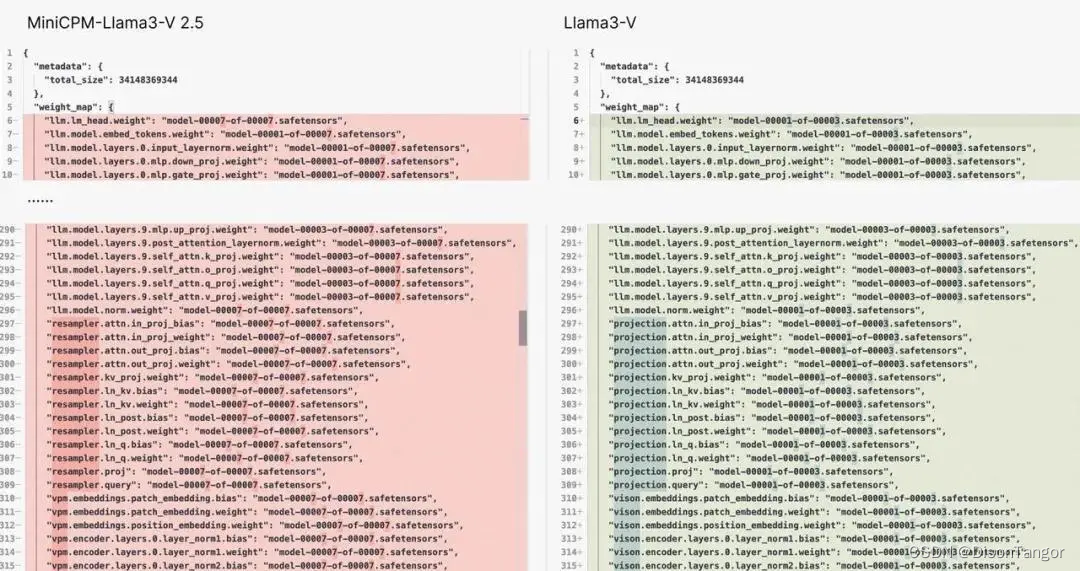

细心的网友在这一线索下细扒,甚至发现连清华 NLP 实验室和面壁智能团队特别采集和标注而独有的战国竹简的ocr识别都有。

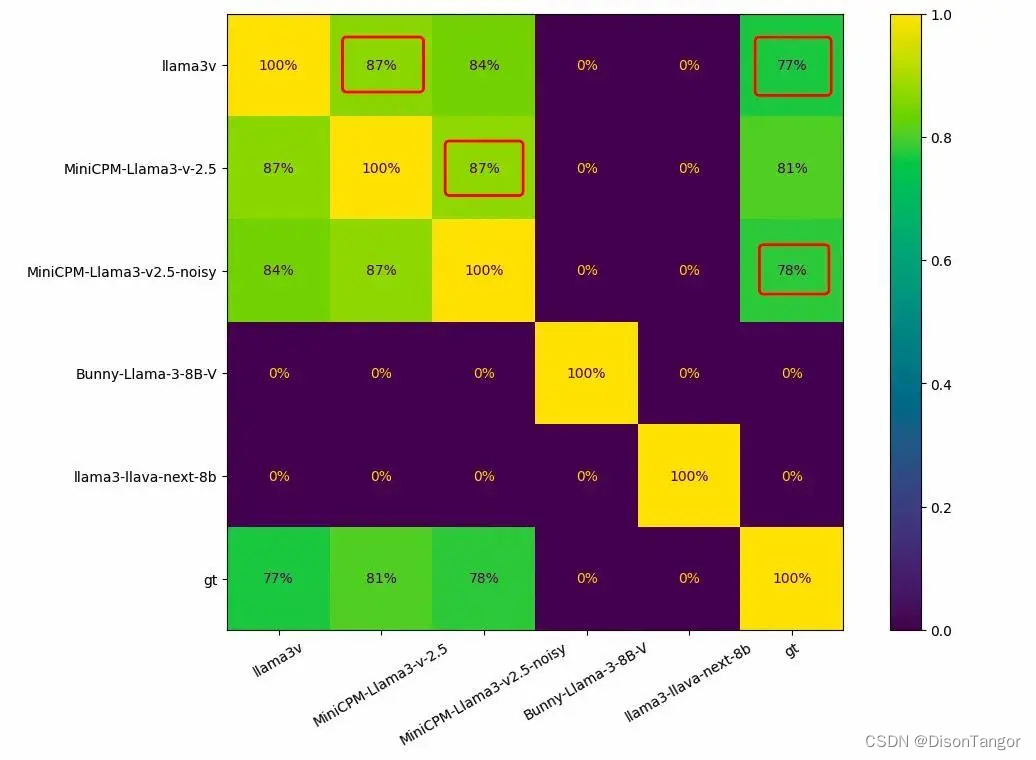
有网友用 1000 张竹简图像对同类模型进行了测试,正常情况下,每两个模型之间的重叠应该为 0,而 Llama3-V 和 MiniCPM-Llama3-V 2.5 之间的重叠高达 87%。识别错误的结果 Llama3-V 和 MiniCPM-Llama3-V 2.5 也有高达 182 个重合。
在国内外舆情发酵了两天后,作者之一站出来道歉,称“抄袭”源于对队友 Mustafa 的盲信。
这不禁让人想起去年的某些事
















 8681
8681

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









