







InternLM3 已经开源了一个 80 亿参数指令模型 InternLM3-8B-Instruct,设计用于通用用途和高级推理。该模型具有以下特点:
- 以更低的成本实现更高的性能:在推理和知识密集型任务上的一流性能超过了 Llama3.1-8B 和 Qwen2.5-7B 等模型。值得注意的是,InternLM3 仅在 4 万亿个高质量标记上进行训练,与其他类似规模的 LLM 相比,可节省 75% 以上的训练成本。
- 深度思考能力:InternLM3 既支持通过长思维链解决复杂推理任务的深度思考模式,也支持流畅用户交互的正常响应模式。
性能评估
我们使用开源评估工具 OpenCompass 对 InternLM 进行了全面评估。评估涵盖五个方面的能力:学科能力、语言能力、知识能力、推理能力和理解能力。以下是部分评估结果,您可以访问 OpenCompass 排行榜了解更多评估结果。
| Benchmark | InternLM3-8B-Instruct | Qwen2.5-7B-Instruct | Llama3.1-8B-Instruct | GPT-4o-mini(closed source) | |
|---|---|---|---|---|---|
| General | CMMLU(0-shot) | 83.1 | 75.8 | 53.9 | 66.0 |
| MMLU(0-shot) | 76.6 | 76.8 | 71.8 | 82.7 | |
| MMLU-Pro(0-shot) | 57.6 | 56.2 | 48.1 | 64.1 | |
| Reasoning | GPQA-Diamond(0-shot) | 37.4 | 33.3 | 24.2 | 42.9 |
| DROP(0-shot) | 83.1 | 80.4 | 81.6 | 85.2 | |
| HellaSwag(10-shot) | 91.2 | 85.3 | 76.7 | 89.5 | |
| KOR-Bench(0-shot) | 56.4 | 44.6 | 47.7 | 58.2 | |
| MATH | MATH-500(0-shot) | 83.0* | 72.4 | 48.4 | 74.0 |
| AIME2024(0-shot) | 20.0* | 16.7 | 6.7 | 13.3 | |
| Coding | LiveCodeBench(2407-2409 Pass@1) | 17.8 | 16.8 | 12.9 | 21.8 |
| HumanEval(Pass@1) | 82.3 | 85.4 | 72.0 | 86.6 | |
| Instrunction | IFEval(Prompt-Strict) | 79.3 | 71.7 | 75.2 | 79.7 |
| Long Context | RULER(4-128K Average) | 87.9 | 81.4 | 88.5 | 90.7 |
| Chat | AlpacaEval 2.0(LC WinRate) | 51.1 | 30.3 | 25.0 | 50.7 |
| WildBench(Raw Score) | 33.1 | 23.3 | 1.5 | 40.3 | |
| MT-Bench-101(Score 1-10) | 8.59 | 8.49 | 8.37 | 8.87 |
- 用粗体标记的值表示 ** 最高** 在开源模型中
- 评估结果来自 OpenCompass获取(部分数据标有*,表示使用思考模式进行评估),评估配置可在 OpenCompass 提供的配置文件中找到。
- 由于 OpenCompass 的版本迭代,评估数据可能存在数值差异,请以 OpenCompass 的最新评估结果为准。 -评估数据可能存在数值差异,请以 OpenCompass 的最新评估结果为准。
限制: 尽管我们在训练过程中努力确保模型的安全性,并鼓励模型生成符合道德和法律要求的文本,但由于其规模和概率生成范例,模型仍可能产生意想不到的输出。例如,生成的回复可能包含偏见、歧视或其他有害内容。请勿传播此类内容。对于因传播有害信息而导致的任何后果,我们概不负责。
要求
transformers >= 4.48
对话模式
transformers推理
要使用 transformers 加载 InternLM3 8B Instruct 模型,请使用以下代码:
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
model_dir = "internlm/internlm3-8b-instruct"
tokenizer = AutoTokenizer.from_pretrained(model_dir, trust_remote_code=True)
# Set `torch_dtype=torch.float16` to load model in float16, otherwise it will be loaded as float32 and might cause OOM Error.
model = AutoModelForCausalLM.from_pretrained(model_dir, trust_remote_code=True, torch_dtype=torch.bfloat16).cuda()
# (Optional) If on low resource devices, you can load model in 4-bit or 8-bit to further save GPU memory via bitsandbytes.
# InternLM3 8B in 4bit will cost nearly 8GB GPU memory.
# pip install -U bitsandbytes
# 8-bit: model = AutoModelForCausalLM.from_pretrained(model_dir, device_map="auto", trust_remote_code=True, load_in_8bit=True)
# 4-bit: model = AutoModelForCausalLM.from_pretrained(model_dir, device_map="auto", trust_remote_code=True, load_in_4bit=True)
model = model.eval()
system_prompt = """You are an AI assistant whose name is InternLM (书生·浦语).
- InternLM (书生·浦语) is a conversational language model that is developed by Shanghai AI Laboratory (上海人工智能实验室). It is designed to be helpful, honest, and harmless.
- InternLM (书生·浦语) can understand and communicate fluently in the language chosen by the user such as English and 中文."""
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": "Please tell me five scenic spots in Shanghai"},
]
tokenized_chat = tokenizer.apply_chat_template(messages, tokenize=True, add_generation_prompt=True, return_tensors="pt").to("cuda")
generated_ids = model.generate(tokenized_chat, max_new_tokens=1024, temperature=1, repetition_penalty=1.005, top_k=40, top_p=0.8)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(tokenized_chat, generated_ids)
]
prompt = tokenizer.batch_decode(tokenized_chat)[0]
print(prompt)
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)
LMDeploy 推理
LMDeploy 是用于压缩、部署和提供 LLM 的工具包,由 MMRazor 和 MMDeploy 团队开发。
pip install lmdeploy
您可以使用以下 python 代码在本地运行批量推理:
import lmdeploy
model_dir = "internlm/internlm3-8b-instruct"
pipe = lmdeploy.pipeline(model_dir)
response = pipe("Please tell me five scenic spots in Shanghai")
print(response)
或者使用以下命令启动与 OpenAI 兼容的服务器:
lmdeploy serve api_server internlm/internlm3-8b-instruct --model-name internlm3-8b-instruct --server-port 23333
然后就可以向服务器发送聊天请求:
curl http://localhost:23333/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "internlm3-8b-instruct",
"messages": [
{"role": "user", "content": "Please tell me five scenic spots in Shanghai"}
]
}'
更多详情,请参阅 LMDeploy 文档
Ollama 推理
首先安装 ollama
# install ollama
curl -fsSL https://ollama.com/install.sh | sh
# fetch model
ollama pull internlm/internlm3-8b-instruct
# install
pip install ollama
推理代码
import ollama
system_prompt = """You are an AI assistant whose name is InternLM (书生·浦语).
- InternLM (书生·浦语) is a conversational language model that is developed by Shanghai AI Laboratory (上海人工智能实验室). It is designed to be helpful, honest, and harmless.
- InternLM (书生·浦语) can understand and communicate fluently in the language chosen by the user such as English and 中文."""
messages = [
{
"role": "system",
"content": system_prompt,
},
{
"role": "user",
"content": "Please tell me five scenic spots in Shanghai"
},
]
stream = ollama.chat(
model='internlm/internlm3-8b-instruct',
messages=messages,
stream=True,
)
for chunk in stream:
print(chunk['message']['content'], end='', flush=True)
vLLM 推理
请参阅 安装 安装 vllm 的最新代码
pip install vllm --pre --extra-index-url https://wheels.vllm.ai/nightly
推理代码:
from vllm import LLM, SamplingParams
llm = LLM(model="internlm/internlm3-8b-instruct")
sampling_params = SamplingParams(temperature=1, repetition_penalty=1.005, top_k=40, top_p=0.8)
system_prompt = """You are an AI assistant whose name is InternLM (书生·浦语).
- InternLM (书生·浦语) is a conversational language model that is developed by Shanghai AI Laboratory (上海人工智能实验室). It is designed to be helpful, honest, and harmless.
- InternLM (书生·浦语) can understand and communicate fluently in the language chosen by the user such as English and 中文."""
prompts = [
{
"role": "system",
"content": system_prompt,
},
{
"role": "user",
"content": "Please tell me five scenic spots in Shanghai"
},
]
outputs = llm.chat(prompts,
sampling_params=sampling_params,
use_tqdm=False)
print(outputs)
思考模式
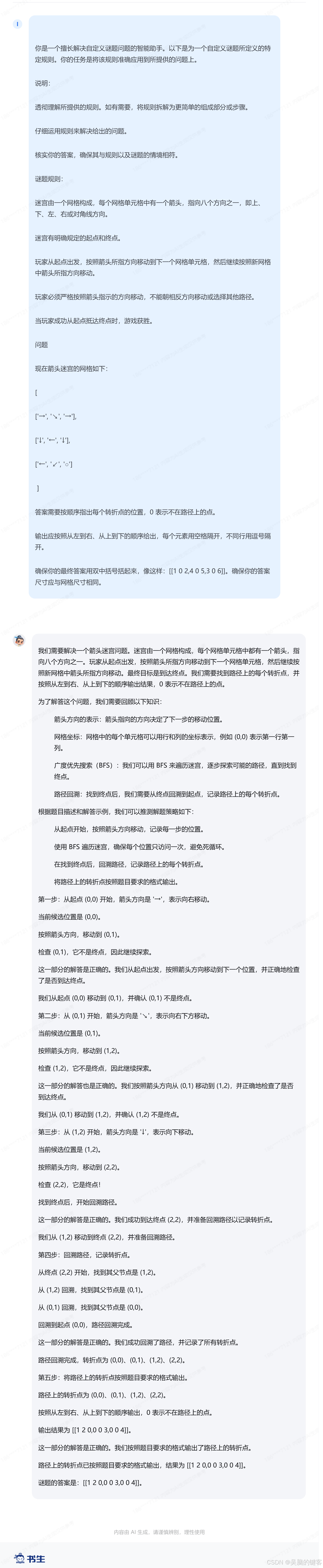
Thinking Demo
Thinking system prompt
thinking_system_prompt = """You are an expert mathematician with extensive experience in mathematical competitions. You approach problems through systematic thinking and rigorous reasoning. When solving problems, follow these thought processes:
## Deep Understanding
Take time to fully comprehend the problem before attempting a solution. Consider:
- What is the real question being asked?
- What are the given conditions and what do they tell us?
- Are there any special restrictions or assumptions?
- Which information is crucial and which is supplementary?
## Multi-angle Analysis
Before solving, conduct thorough analysis:
- What mathematical concepts and properties are involved?
- Can you recall similar classic problems or solution methods?
- Would diagrams or tables help visualize the problem?
- Are there special cases that need separate consideration?
## Systematic Thinking
Plan your solution path:
- Propose multiple possible approaches
- Analyze the feasibility and merits of each method
- Choose the most appropriate method and explain why
- Break complex problems into smaller, manageable steps
## Rigorous Proof
During the solution process:
- Provide solid justification for each step
- Include detailed proofs for key conclusions
- Pay attention to logical connections
- Be vigilant about potential oversights
## Repeated Verification
After completing your solution:
- Verify your results satisfy all conditions
- Check for overlooked special cases
- Consider if the solution can be optimized or simplified
- Review your reasoning process
Remember:
1. Take time to think thoroughly rather than rushing to an answer
2. Rigorously prove each key conclusion
3. Keep an open mind and try different approaches
4. Summarize valuable problem-solving methods
5. Maintain healthy skepticism and verify multiple times
Your response should reflect deep mathematical understanding and precise logical thinking, making your solution path and reasoning clear to others.
When you're ready, present your complete solution with:
- Clear problem understanding
- Detailed solution process
- Key insights
- Thorough verification
Focus on clear, logical progression of ideas and thorough explanation of your mathematical reasoning. Provide answers in the same language as the user asking the question, repeat the final answer using a '\\boxed{}' without any units, you have [[8192]] tokens to complete the answer.
"""
Transformers 推理
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
model_dir = "internlm/internlm3-8b-instruct"
tokenizer = AutoTokenizer.from_pretrained(model_dir, trust_remote_code=True)
# Set `torch_dtype=torch.float16` to load model in float16, otherwise it will be loaded as float32 and might cause OOM Error.
model = AutoModelForCausalLM.from_pretrained(model_dir, trust_remote_code=True, torch_dtype=torch.bfloat16).cuda()
# (Optional) If on low resource devices, you can load model in 4-bit or 8-bit to further save GPU memory via bitsandbytes.
# InternLM3 8B in 4bit will cost nearly 8GB GPU memory.
# pip install -U bitsandbytes
# 8-bit: model = AutoModelForCausalLM.from_pretrained(model_dir, device_map="auto", trust_remote_code=True, load_in_8bit=True)
# 4-bit: model = AutoModelForCausalLM.from_pretrained(model_dir, device_map="auto", trust_remote_code=True, load_in_4bit=True)
model = model.eval()
messages = [
{"role": "system", "content": thinking_system_prompt},
{"role": "user", "content": "Given the function\(f(x)=\mathrm{e}^{x}-ax - a^{3}\),\n(1) When \(a = 1\), find the equation of the tangent line to the curve \(y = f(x)\) at the point \((1,f(1))\).\n(2) If \(f(x)\) has a local minimum and the minimum value is less than \(0\), determine the range of values for \(a\)."},
]
tokenized_chat = tokenizer.apply_chat_template(messages, tokenize=True, add_generation_prompt=True, return_tensors="pt").to("cuda")
generated_ids = model.generate(tokenized_chat, max_new_tokens=8192)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(tokenized_chat, generated_ids)
]
prompt = tokenizer.batch_decode(tokenized_chat)[0]
print(prompt)
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)
LMDeploy 推理
LMDeploy 是用于压缩、部署和提供 LLM 的工具包。
pip install lmdeploy
您可以使用以下 python 代码在本地运行批量推理:
from lmdeploy import pipeline, GenerationConfig, ChatTemplateConfig
model_dir = "internlm/internlm3-8b-instruct"
chat_template_config = ChatTemplateConfig(model_name='internlm3')
pipe = pipeline(model_dir, chat_template_config=chat_template_config)
messages = [
{"role": "system", "content": thinking_system_prompt},
{"role": "user", "content": "Given the function\(f(x)=\mathrm{e}^{x}-ax - a^{3}\),\n(1) When \(a = 1\), find the equation of the tangent line to the curve \(y = f(x)\) at the point \((1,f(1))\).\n(2) If \(f(x)\) has a local minimum and the minimum value is less than \(0\), determine the range of values for \(a\)."},
]
response = pipe(messages, gen_config=GenerationConfig(max_new_tokens=2048))
print(response)
Ollama 推理
首先安装 ollama
# install ollama
curl -fsSL https://ollama.com/install.sh | sh
# fetch model
ollama pull internlm/internlm3-8b-instruct
# install
pip install ollama
推理代码
import ollama
messages = [
{
"role": "system",
"content": thinking_system_prompt,
},
{
"role": "user",
"content": "Given the function\(f(x)=\mathrm{e}^{x}-ax - a^{3}\),\n(1) When \(a = 1\), find the equation of the tangent line to the curve \(y = f(x)\) at the point \((1,f(1))\).\n(2) If \(f(x)\) has a local minimum and the minimum value is less than \(0\), determine the range of values for \(a\)."
},
]
stream = ollama.chat(
model='internlm/internlm3-8b-instruct',
messages=messages,
stream=True,
)
for chunk in stream:
print(chunk['message']['content'], end='', flush=True)
vLLM 推理
请参阅 installation 安装 vllm 的最新代码
pip install vllm --pre --extra-index-url https://wheels.vllm.ai/nightly
推理代码
from vllm import LLM, SamplingParams
llm = LLM(model="internlm/internlm3-8b-instruct")
sampling_params = SamplingParams(temperature=1, repetition_penalty=1.005, top_k=40, top_p=0.8, max_tokens=8192)
prompts = [
{
"role": "system",
"content": thinking_system_prompt,
},
{
"role": "user",
"content": "Given the function\(f(x)=\mathrm{e}^{x}-ax - a^{3}\),\n(1) When \(a = 1\), find the equation of the tangent line to the curve \(y = f(x)\) at the point \((1,f(1))\).\n(2) If \(f(x)\) has a local minimum and the minimum value is less than \(0\), determine the range of values for \(a\)."
},
]
outputs = llm.chat(prompts,
sampling_params=sampling_params,
use_tqdm=False)
print(outputs)
Open Source License
Code and model weights are licensed under Apache-2.0.
Citation
@misc{cai2024internlm2,
title={InternLM2 Technical Report},
author={Zheng Cai and Maosong Cao and Haojiong Chen and Kai Chen and Keyu Chen and Xin Chen and Xun Chen and Zehui Chen and Zhi Chen and Pei Chu and Xiaoyi Dong and Haodong Duan and Qi Fan and Zhaoye Fei and Yang Gao and Jiaye Ge and Chenya Gu and Yuzhe Gu and Tao Gui and Aijia Guo and Qipeng Guo and Conghui He and Yingfan Hu and Ting Huang and Tao Jiang and Penglong Jiao and Zhenjiang Jin and Zhikai Lei and Jiaxing Li and Jingwen Li and Linyang Li and Shuaibin Li and Wei Li and Yining Li and Hongwei Liu and Jiangning Liu and Jiawei Hong and Kaiwen Liu and Kuikun Liu and Xiaoran Liu and Chengqi Lv and Haijun Lv and Kai Lv and Li Ma and Runyuan Ma and Zerun Ma and Wenchang Ning and Linke Ouyang and Jiantao Qiu and Yuan Qu and Fukai Shang and Yunfan Shao and Demin Song and Zifan Song and Zhihao Sui and Peng Sun and Yu Sun and Huanze Tang and Bin Wang and Guoteng Wang and Jiaqi Wang and Jiayu Wang and Rui Wang and Yudong Wang and Ziyi Wang and Xingjian Wei and Qizhen Weng and Fan Wu and Yingtong Xiong and Chao Xu and Ruiliang Xu and Hang Yan and Yirong Yan and Xiaogui Yang and Haochen Ye and Huaiyuan Ying and Jia Yu and Jing Yu and Yuhang Zang and Chuyu Zhang and Li Zhang and Pan Zhang and Peng Zhang and Ruijie Zhang and Shuo Zhang and Songyang Zhang and Wenjian Zhang and Wenwei Zhang and Xingcheng Zhang and Xinyue Zhang and Hui Zhao and Qian Zhao and Xiaomeng Zhao and Fengzhe Zhou and Zaida Zhou and Jingming Zhuo and Yicheng Zou and Xipeng Qiu and Yu Qiao and Dahua Lin},
year={2024},
eprint={2403.17297},
archivePrefix={arXiv},
primaryClass={cs.CL}
}



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









