








摘要
最近,Muon 优化器 在训练小规模语言模型方面取得了很好的效果,但对更大规模模型的可扩展性尚未得到证实。我们发现了两种扩展 Muon 的关键技术:
- 重量衰减:对于扩展到更大的模型至关重要
- 一致性均方根更新:对模型更新执行一致的均方根。
这些技术使 Muon 能够在大规模训练中开箱即用,无需进行超参数调整。缩放规律实验表明,Muon 是 ∼ 2 × \sim2\times ∼2×比亚当计算最优训练的采样效率更高。
基于这些改进,我们推出了Moonlight,一个使用 Muon 以 5.7T 标记训练的 3B/16B 参数专家混合(MoE)模型。与之前的模型相比,我们的模型改进了当前的帕累托前沿,以更少的训练 FLOP 实现了更好的性能。
我们开源了我们的Muon实现,该实现具有内存优化和通信效率高的特点。我们还发布了预训练、指令调整和中间检查点,以支持未来的研究。
我们的代码可在 MoonshotAI/Moonlight 上获取。

主要成分
我们的工作以 Muon 为基础,同时系统地识别并解决了其在大规模训练场景中的局限性。我们的技术贡献包括
-
Muon有效扩展的分析:通过大量分析,我们发现权重衰减对Muon的可扩展性起着至关重要的作用。此外,我们还建议通过参数化更新规模调整,在不同的矩阵和非矩阵参数中保持一致的更新均方根(RMS)。这种调整大大增强了训练的稳定性。
-
高效分布式实现:我们开发了具有 ZeRO-1 风格优化的分布式 Muon 版本,在保留算法数学特性的同时,实现了最佳内存效率并减少了通信开销。
-
缩放定律验证:我们进行了缩放规律研究,将 Muon 与强大的 AdamW 基线进行了比较,结果显示 Muon 的性能更优越(见图 1)。根据缩放规律结果,Muon 的性能与经过 AdamW 训练的对应程序相当,而所需的训练 FLOP 仅为后者的约 52%。
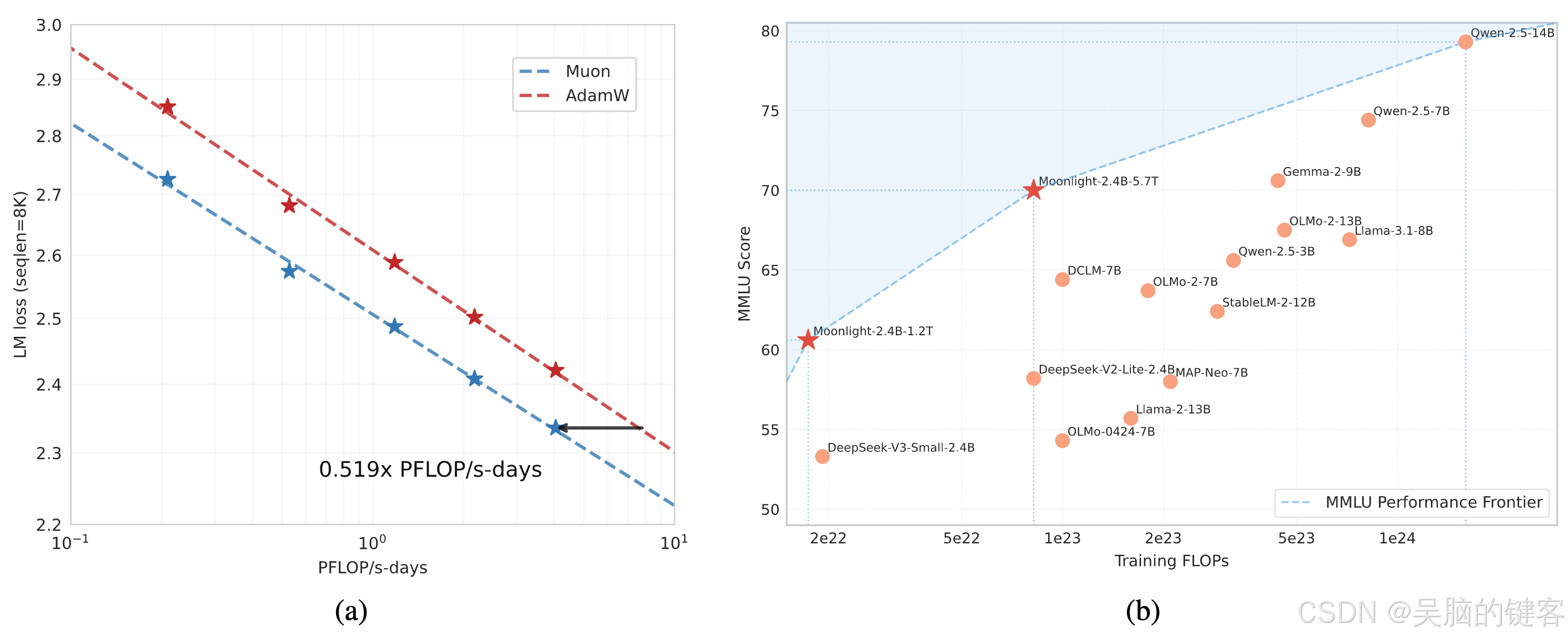
性能
我们将 "月光 "与比例相近的 SOTA 公共模型进行了比较:
- LLAMA3-3B是一个使用 9T 标记训练的 3B 参数密集模型
- Qwen2.5-3B 是一个使用 18T 标记训练的 3B 参数密集模型
- Deepseek-v2-Lite 是一个 2.使用 5.7T 标记训练的 4B/16B 参数 MOE 模型。
| Benchmark (Metric) | Llama3.2-3B | Qwen2.5-3B | DSV2-Lite | Moonlight | |
|---|---|---|---|---|---|
| Activated Param† | 2.81B | 2.77B | 2.24B | 2.24B | |
| Total Params† | 2.81B | 2.77B | 15.29B | 15.29B | |
| Training Tokens | 9T | 18T | 5.7T | 5.7T | |
| Optimizer | AdamW | * | AdamW | Muon | |
| English | MMLU | 54.75 | 65.6 | 58.3 | 70.0 |
| MMLU-pro | 25.0 | 34.6 | 25.5 | 42.4 | |
| BBH | 46.8 | 56.3 | 44.1 | 65.2 | |
| TriviaQA‡ | 59.6 | 51.1 | 65.1 | 66.3 | |
| Code | HumanEval | 28.0 | 42.1 | 29.9 | 48.1 |
| MBPP | 48.7 | 57.1 | 43.2 | 63.8 | |
| Math | GSM8K | 34.0 | 79.1 | 41.1 | 77.4 |
| MATH | 8.5 | 42.6 | 17.1 | 45.3 | |
| CMath | - | 80.0 | 58.4 | 81.1 | |
| Chinese | C-Eval | - | 75.0 | 60.3 | 77.2 |
| CMMLU | - | 75.0 | 64.3 | 78.2 |
Qwen 2 & 2.5 报告未披露其优化器信息。报告的参数数不包括嵌入参数。 我们使用全套 TriviaQA 测试了所有列出的模型。
示例用法
型号下载
| Model | #Total Params | #Activated Params | Context Length | Download Link |
|---|---|---|---|---|
| Moonlight-16B-A3B | 16B | 3B | 8K | 🤗 Hugging Face |
| Moonlight-16B-A3B-Instruct | 16B | 3B | 8K | 🤗 Hugging Face |
Hugging Face Transformers 的推理
我们将介绍如何在推理阶段使用转换器库来使用我们的模型。建议使用 python=3.10、torrent>=2.1.0 和 transformers=4.48.2 作为开发环境。
对于我们的预训练模型(Moonlight-16B-A3B):
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "moonshotai/Moonlight-16B-A3B"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto",
trust_remote_code=True,
)
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
prompt = "1+1=2, 1+2="
inputs = tokenizer(prompt, return_tensors="pt", padding=True, truncation=True).to(model.device)
generated_ids = model.generate(**inputs, max_new_tokens=100)
response = tokenizer.batch_decode(generated_ids)[0]
print(response)
对于我们的 Instruct 模型(Moonlight-16B-A3B-Instruct):
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "moonshotai/Moonlight-16B-A3B-Instruct"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto",
trust_remote_code=True
)
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
messages = [
{"role": "system", "content": "You are a helpful assistant provided by Moonshot-AI."},
{"role": "user", "content": "Is 123 a prime?"}
]
input_ids = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt").to(model.device)
generated_ids = model.generate(inputs=input_ids, max_new_tokens=500)
response = tokenizer.batch_decode(generated_ids)[0]
print(response)
Moonlight 采用与 DeepSeek-V3 相同的架构,许多流行的推理引擎(如 VLLM 和 SGLang)都支持该架构。因此,我们的模型也可以轻松地使用这些工具进行部署。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









