







上海阶跃星辰智能科技有限公司宣布开源其最新的图生视频模型——Step-Video-TI2V。这一模型是基于30B参数的Step-Video-T2V训练而成,能够生成102帧、5秒、540P分辨率的视频,具有运动幅度可控和镜头运动可控两大核心特点,尤其在动漫效果方面表现出色。与现有的开源图生视频模型相比,Step-Video-TI2V不仅在参数规模上提供了更高的上限,其运动幅度可控能力还能平衡视频生成结果的动态性和稳定性,为创作者提供了更灵活的选择。
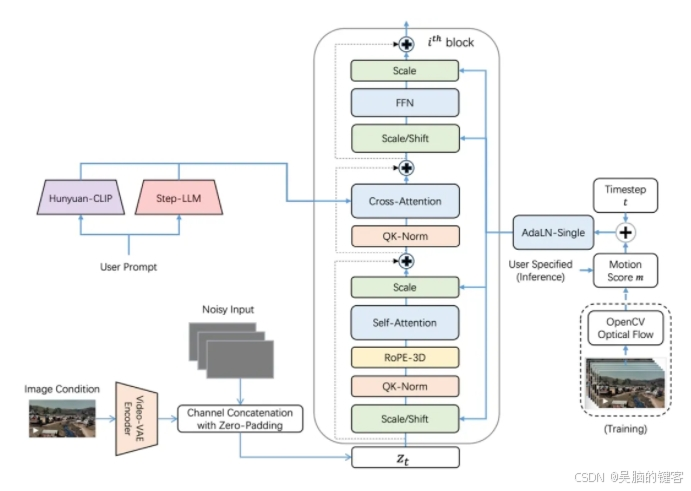
Step-Video-TI2V的开发过程中,团队进行了两大关键优化。首先,引入图像条件以提高生成视频与原图的一致性。与传统的cross-attention方法不同,该模型采用了更直接的方式,将图像对应的向量表示与DiT第一帧对应的向量表示直接进行channel维度的拼接,从而确保生成的视频与输入图片高度一致。其次,通过AdaLN模块引入视频动态性打分信息,使用户在生成视频时可以指定不同的运动级别,精准控制视频的动态幅度,从而平衡动态性、稳定性和一致性。此外,团队还对主体动作和镜头运动进行了专项精准标注,进一步提升了模型在主体动态性和运镜效果上的表现。
Step-Video-TI2V的核心特点包括运动幅度可控、多种运镜控制、动漫效果优异以及支持多尺寸生成。用户可以根据创作需求自由切换动态与稳定画面,生成从基本的推拉摇移、升降到复杂电影级运镜效果的视频。该模型在动漫类任务上的表现尤为突出,非常适合动画创作和短视频制作等应用场景。同时,它支持多种尺寸的图生视频,无论是横屏、竖屏还是方屏,都能满足不同平台的需求。
GitHub:
https://github.com/stepfun-ai/Step-Video-TI2V
Github-ComfyUI:
https://github.com/stepfun-ai/ComfyUI-StepVideo


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









