









1. 关键信息说明
:指n个样本,每个样本有p个维度
:指n个样本所形成的矩阵的转置,为n*p维矩阵,即样本矩阵
:指X所代表的的分布中的未知参数
2. 频率派
2.1 核心思想
已知X的分布,找到未知参数θ,使得P(x|θ)最大。即最大似然估计MLE:
2.2 简单案例
2.2.1 已知参数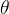
以两个箱子中的黑白球举例,和
分别为两个箱子中黑球的概率 ,此处
也就是p
1号箱子内有5个黑球和5个白球,2号箱子内有7个黑球和3个白球。
也就是说,p(黑球|1号箱子) = 1/2,p(白球|1号箱子) = 1/2,p(黑球|2号箱子) = 7/10,p(白球|2号箱子) = 3/10。
经过某一个箱子的10次有放回抽样,我们得到了8个黑球,2个白球。这些样本来自于哪个箱子呢?我们通常会认为来自于2号箱子的概率大,但是这是我们的经验判断,那么可观依据在哪呢?这就是最大似然估计思想的由来。
来看1号箱子得到该样本分布的概率,
即p(黑球|1号箱子)^8 * p(白球|1号箱子)^2 = (1/2)^8*(1/2)^2 = 0.000977
来看2号箱子得到该样本分布的概率,
即p(黑球|2号箱子)^8 * p(白球|2号箱子)^2 = (7/10)^8*(3/10)^2 = 0.005188
可以看出p(黑球|2号箱子)^8 * p(白球|2号箱子)^2 > p(黑球|1号箱子)^8 * p(白球|1号箱子)^2
从而判断该样本来自2号箱子。
2.2.2 未知参数
同样,我们再从一个仅含黑白球的箱子中有放回抽样十次,不同的是,此时我们并不知道箱子中黑白球的个数,即 是未知参数。
经过抽样,我们得到7个黑球,3个白球。那么我们能否得知P(黑球|箱子)和P(白球|箱子)的概率分别为多少呢?这也就是我们要找的未知参数θ。
通过极大似然估计,我们要找到一个θ,使得p(黑球|箱子)^7*p(白球|箱子)^3 = θ^7 * (1-θ)^3最大。
经过计算后,我们会得到θ的估计值,也就是7/10,这告诉我们,该箱子的黑白球很可能满足 = 0.7的二项分布。 这就是频率派要做的事。
2.3 频率派中的一维正态分布(高斯分布)
2.3.1 无偏估计
一维高斯中,我们已知正态分布的概率密度函数:
其中,
若直观理解,当 为何值时,
会取最大呢?
我们已知高斯分布是一个钟形,如图所示,

显然,若要使最大,以该图为例,
需位于X轴的0点处,这时钟最高,表示
最大。细心的朋友也可以发现,此时,
,也就是说
是样本均值。
若要严格推导,则需要使用MLE的方法。
推导说明如下:
- 首先,得到与
有关的式子
-
其次,对
-
最后,验证
推导过程如下:
1. 得到与有关的式子

2. 对求偏导,从而计算出

3. 验证的无偏性

2.3.2 有偏估计
推导说明如下:
- 首先,得到与
-
其次,对
求偏导,从而计算出
-
最后,验证
推导过程如下:
1. 得到与有关的式子

2. 对求偏导,从而计算出

3. 验证 的有偏性

可以发现,样本方差的期望(可以理解为均值)对于总体方差,是有偏的。为了得到无偏的总体方差的估计值,我们通常将样本方差除以N-1。
2. 贝叶斯派
2.1 核心思想MAP
频率派仅根据样本最后的频率来找到参数从而使P(X|θ)最大。
贝叶斯派不仅要使P(X|θ)最大,同时还要使得P(θ)最大,使得后验P(θ|X) = P(X|θ)P(θ)最大0。
之所以忽略了P(X)这一边缘概率,是因为它的作用是归一化,然而我们的目的是比较后验概率,选择后验概率最大的那个参数,因此它也失去了作用。
通俗的理解是,在频率派的思想中,我们就想找到唯一一个θ,使得P(X|θ)最大,但这时我们要根据自身的经验,给P(X|θ)加一个权重P(θ),也就是 P(X|θ)P(θ)。此时P(X|θ)最大,但相乘起来并不一定最大。
2.2 案例说明
拿经典的抛硬币的案例作为说明,在频率派的视角中,假如对硬币抛了十次,获得7次正面,3次反面的样本,那么最终计算的θ为7/10和1-θ为3/10。这显然有一定问题,频率派没有考虑到该硬币是否是均匀的,仅根据样本结果进行了参数估计。而在贝叶斯派看来,在计算P(X|θ)的同时,还得考虑先验概率P(θ),即考虑硬币是否是均匀的的概率,使得P(X|θ)P(θ)达到最大。
2.3 贝叶斯估计
目的:对p(θ|X)建模
和MAP不同的是,贝叶斯估计将先验P(θ)的参数θ当做一个随机变量,P(θ)表示的是参数θ的分布,也就是我们所说的先验分布。似然P(X|θ)也服从某一分布。若这两个分布为连续型,则表示为f(θ)和f(X|θ)。
可以发现,原本的后验概率P(θ|X)=P(X|θ)P(θ)。此时后验概率的参数θ也会服从某一分布。我们称之为后验分布。
2.4 共轭先验
共轭先验指的是后验p(θ|X)的分布与先验p(θ)的分布一致,则p(θ)是p(X|θ)的共轭先验。若如2.3所说,后验概率的参数θ也会服从于某一分布,具体是什么分布未知。但如果f(θ)是f(X|θ)的共轭先验,后验分布会与先验分布一致,只是参数发生了变化。常见的,似然为二项分布,先验Beta分布是似然的共轭先验;正态分布是自身的共轭先验。
2.5 贝叶斯预测
目的:预测newX
知道了参数θ的后验分布,我们自然要用后验分布来做预测。
假设我们要预测newX
通俗的理解是,将旧样本训练出的后验分布p(θ|X)作为新的先验,得到X和θ条件下的newX的分布,再通过p(newX|θ, X)p(θ|X)求得边缘概率p(newX|X),这就是我们对newX的预测。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









