







先说两个名词:编码格式、字符集:
按照一定规则把符号和 二进制码 对应起来,这就是 编码格式; 像我们常说的ASCII,UTF8,GBK都是常用的编码格式;而把n多这种已经编码的字符聚在一起,就是我们常说的 字符集 。 比如 utf-8字符集 就是所有utf-8编码格式的字符的合集。
在当前文章中,我们可以简单的认为 字符集 == 编码格式,以下文章中,也并未做刻意的区分。
源码字符集:就是你的源代码文本文件的字符集(确切的说是编译器认为的源码文件的编码方式),如果你手头有NodePad++这样类似的文本编辑器你可以打开看一下你的字符集,或者用Windows记事本另存为的时候也会显示文本格式。要知道,你的源代码文本文件是以二进制的形式躺在硬盘里的,无论中文英文都一样,当你输入一个汉字后保存关闭,这个汉字就是按照你指定的字符集转换成二进制编码保存下去的,当你在以这个格式打开文件时候,就再按照你指定的字符集把二进制转回来。如果两次使用不同的字符集,也就会出现乱码了。
执行字符集:可执行应用程序采用的编码格式;在C++里 char* str= “我”;执行字符集决定了这行代码在编译器进行编译的时候str存储的二进制到底是什么,你可能会说源码字符集不是已经决定了这个”我”的二进制表示了么,没错,但是这个执行字符集就是让你在这里对它再解释一次。比如我源码字符集可能是UTF8的,但是我可以通过执行字符集来让最终ptr存储的是GBK的字节编码。
编译器会对比源文件字符集和可执行文件字符集
如果一致,编译器会直接将源文件中的中文字符编码拷贝到可执行程序中;
如果不一致,编译器会将源文件中的中文字符串按照它认为的源文件的编码方式解码,然后将解码得到的中文字符,再使用执行字符集进行编码,存储到可执行文件中去。
- MSVC2013编译程序时,处理源码字符集时,有BOM标识符的则正确识别(实际上目前就是有无BOM的utf-8),无BOM则使用本地Locale字符集(随系统设置而变),执行字符集默认用本地Locale字符集
- Windows平台的Locale字符集默认为GBK(中国地区)、ASCII(又称为ANSI,美国地区)
- Linux平台的Locale字符集默认为UTF-8
看以下代码,在Windows平台使用QtCreator + MSVC编译器,配合Notepad++中的Hex Editor插件,进行如下几个测试,先说结论,再进行验证:
MainWindow::MainWindow(QWidget *parent)
: QMainWindow(parent)
, ui(new Ui::MainWindow)
{
this->setWindowTitle("测试");
}
前提须知:"测试"这两个字的UTF-8编码后的十六进制为:e6 b5 8b e8 af 95;使用GBK编码后的十六进制为:b2 e2 ca d4
测试一:源文件使用 UTF-8 无BOM编码,如果是奇数个数中文,则会编译报错;因为UTF-8编码中,一个汉字是三个字节,GBK编码,一个汉字为两个字节,由于源文件的编码方式并没有带BOM标记,所以编译器会认为源文件的编码方式为Local(GBK),编译器在解析源文件的时候会把中文后面的引号也算到中文中去,导致编译报错,"常量中有换行符"
测试二:源文件使用 UTF-8无BOM编码,偶数个数中文,可以编译通过,也不会乱码;验证如下:
- 在源文件中,搜索UTF-8编码后的十六进制数,可以搜索到,即表示,源文件的编码方式是UTF-8,与前提一致,如图:
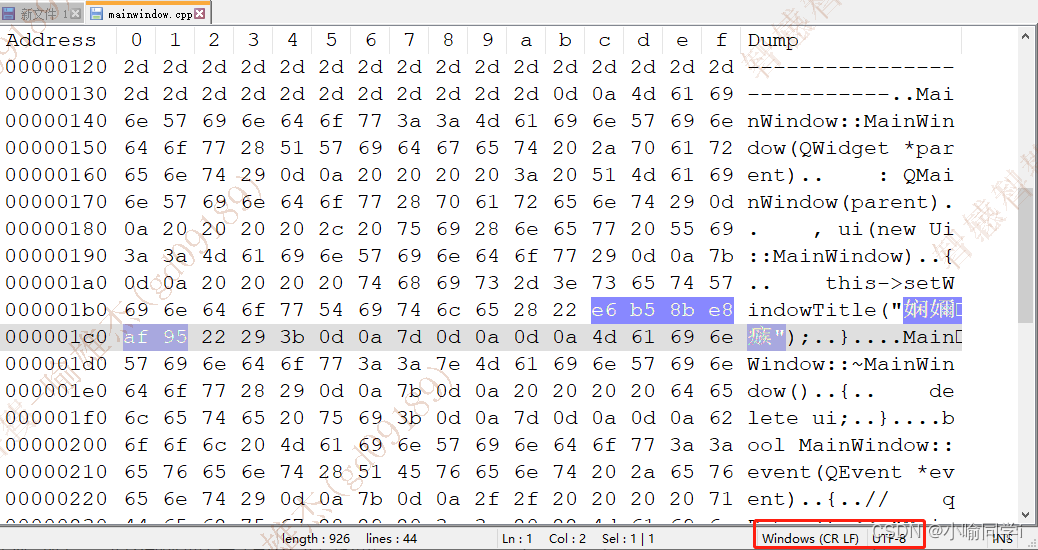
- 在可执行程序中,搜索UTF-8编码后的十六进制数,可以搜索到;搜索GBK编码后的二进制数,搜索不到;但是实际上可执行程序的编码方式其实是为GBK,如图:
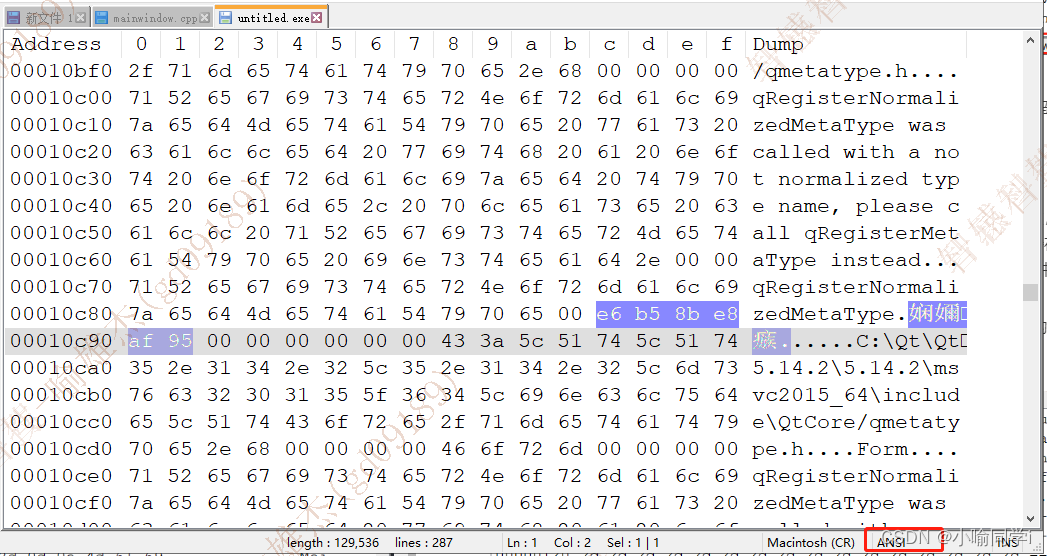
这是因为,源文件编码方式为UTF-8无BOM,所以编译器不能正确的识别到源文件的编码方式,它还是认为源码是以Locale(GBK)方式编码;由于我们也没有指定可执行程序编码方式,所以编译器默认可执行程序编码方式为Local(GBK),编译器此时认为 源文件字符集与可执行文件字符集一致,所以会直接将源文件里面,即将中文字符的二进制编码e6 b5 8b e8 af 95拷贝到生成的可执行文件中;
在程序运行时:QString如何处理 可执行文件中的 e6 b5 8b e8 af 95呢?
QString是按照UTF-8格式读取二进制字节流来解析,所以解析出来就是正常的,
QString::fromLocal8bit()是按照本地编码来解析字节流,也就是GBK,所以解析出来就是乱码
测试三:源文件使用UTF-8无BOM编码,程序中使用中文处,添加预处理宏,指定 执行字符集为UTF-8,此时程序会乱码,分析如下:
- 在源文件中,搜索UTF-8编码后的十六进制数
e6 b5 8b e8 af 95,可以搜索到,说明源文件是使用UTF-8编码,与前提对应,如下: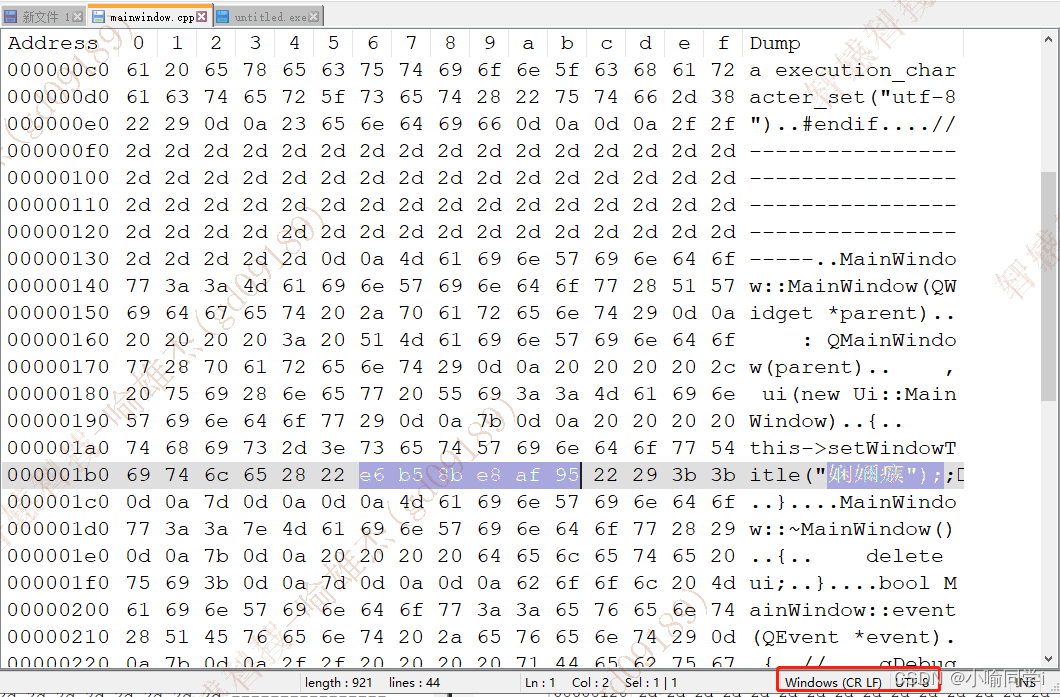
由于源文件格式为UTF-8无BOM,所以MSVC编译器无法正确识别到源文件的编码格式,它认为源文件的编码格式为Locale(GBK);由于此时我们手动指定了执行字符集为 UTF-8,所以编译器认为源文件的编码格式与应用程序的编码格式不一致,需要将源文件中的中文字符编码,由GBK转为UTF-8存储到可执行程序中;所以编译器会将源文件中的e6 b5 8b e8 af 95以GBK的格式进行解码,解码后得到中文字符"娴嬭瘯";然后再将此中文字符,以UTF-8的格式进行编码(得到e5 a8 b4 e5 ac ad e7 98 af)存储到可执行程序中

我们在可执行程序中搜索e5 a8 b4 e5 ac ad e7 98 af,可以搜索到,如图:
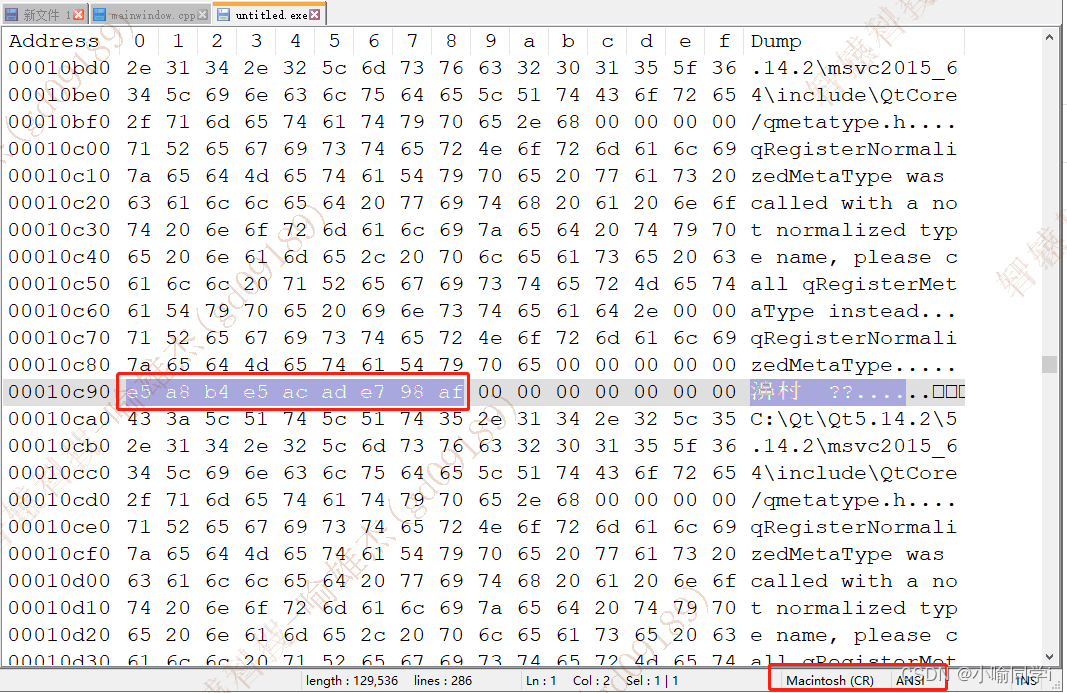 - 在程序运行时:
- 在程序运行时:QString如何处理 可执行文件中的e5 a8 b4 e5 ac ad e7 98 af呢?
QString是按照UTF-8格式读取二进制字节流来解析,所以解析出来就是乱码了(“娴嬭瘯”);
QString::fromLocal8bit()是按照本地编码来解析字节流,也就是GBK,所以解析出来也是乱码(“濞村鐦?”);

测试四:源文件使用UTF-8带BOM编码,无论中文个数为奇数还是偶数个,都可以编译过,但是如果没有使用预处理指令指定执行程序字符集,MSVC编译器会默认执行字符集为GBK,所以编译器在生成可执行程序时,编译器会进行转码,将UTF-8编码的"测试"两个字,转为GBK编码存储到应用程序中,验证如下:
- 在源文件中,搜索UTF-8编码后的十六进制数,可以搜索到,即表示,源文件的编码方式就是UTF-8,这也和我们的前提一致,如图:
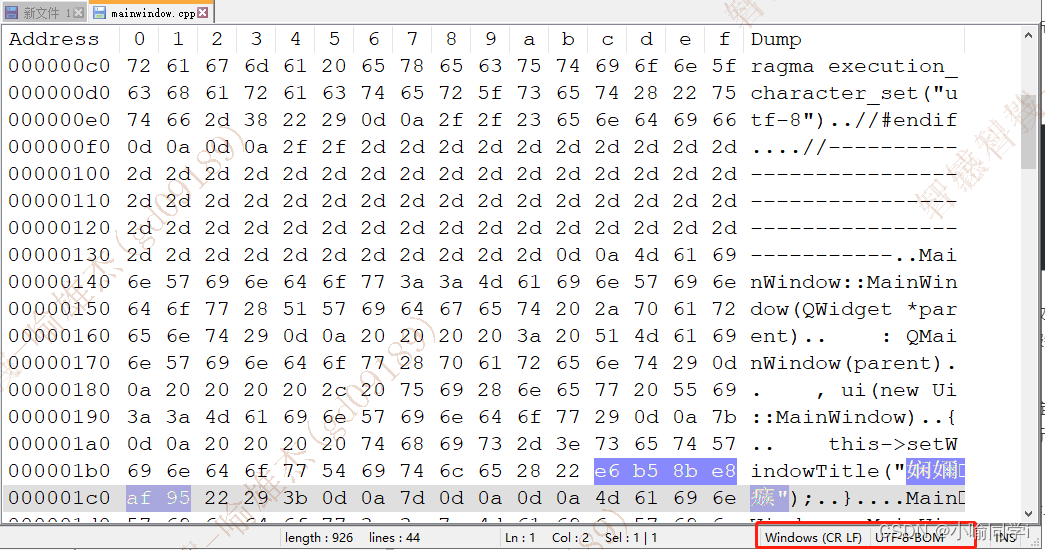
- 在生成的可执行程序中,搜索UTF-8编码后的十六进制数,搜索不到;但是搜索GBK编码后的十六进制数,可以搜索到,则表明可执行程序的编码方式为GBK编码;这就是编译器检测到 执行文件字符集与源文件字符集不一致,就将中文字符串使用源文件的编码方式进行解码,然后再使用 执行文件字符集重新编码到可执行文件中去;
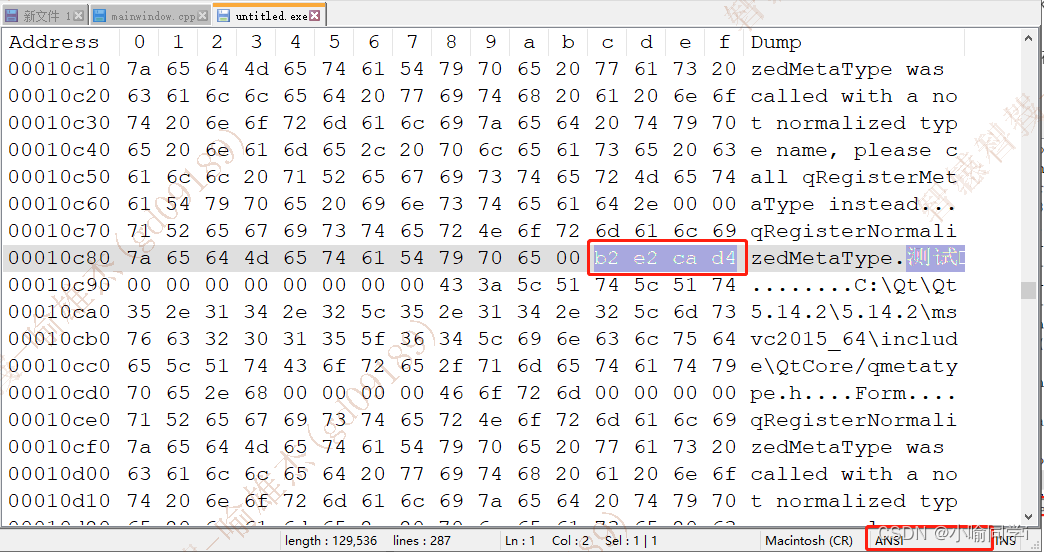
- 在程序运行时:
QString如何处理 可执行文件中的b2 e2 ca d4呢?
QString是按照UTF-8格式读取二进制字节流来解析,所以解析出来就是乱码了,
QString::fromLocal8bit()是按照本地编码来解析字节流,也就是GBK,所以可以正常显示
乱码的统一解决方案:
1.如果源文件采用的UTF-8不带BOM的编码格式,一般可执行程序不会出现中文乱码(编译器错误的认为源文件的编码方式为GBK,且执行字符集也为GBK,编译器是直接拷贝中文字符的编码到可执行程序,恰好QString的解析字符集为UTF-8,所以歪打正着,不会出现乱码);如果UTF-8不带BOM的编码格式,加上#pragma execution_character_set("utf-8")预处理,则会出现乱码
2.如果源文件采用UTF-8带BOM的编码格式,中文出现乱码,有如下解决方案:
1. 强制 MSVC 编译器采用 UTF-8 的编码格式来生成可执行文件,需要在每个使用到中文字符串的头文件和源程序文件的前部加入如下的语句:
#if defined(_MSC_VER) && (_MSC_VER >= 1600)
# pragma execution_character_set("utf-8")
#endif
1.可以将以上代码放入一个单独的头文件,在需要使用处,包含此头文件;
2.或是将以上代码写入到预编译头文件中去:
//.pro文件中指定预编译头文件,预编译头文件写入以上内容
CONFIG += c++11
#可以在项目中使用预编译头文件的支持
CONFIG += precompile_header
#预编译头文件路径
PRECOMPILED_HEADER = $$PWD/stdafx.h
2.另外一种解决方案:给MSVC编译器指定源码的字符集和执行字符集,在项目的.pro文件中加入以下代码:
编译器认为源码字符集和执行字符集都是UTF-8, 即相同,则是直接拷贝源码中的中文字符的二进制到可执行文件中去,而QString的解析字符集又正好是UTF-8,则正好不会乱码
msvc{
QMAKE_CXXFLAGS += /source-charset:utf-8 /execution-charset:utf-8
}
execution-charest表示执行字符集,source-charset表示源码字符集
注意:msvc必须是小写,亲测大写MSVC无效。另外,运行之前,建议清除一下,重新构建,删除之前的缓存。
参考:
https://www.cnblogs.com/Esfog/p/MSVC_UTF8_CHARSET_HANDLE.html
https://blog.csdn.net/qq_20821119/article/details/120170353















 871
871











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









