







论文笔记4:两篇利用SVD去噪论文
An Efficient SVD-Based Method for Image Denoising(cite:147)
引言
《统计学习方法(第二版)》李航





- 空间域方法:保结构局部滤波器(SUSAN)、非局部平均(NLM)、空间自适应迭代滤波(SAIF)、基于patch的局部最优wiener滤波器(PLOW)、双向非局部变分模型(TDNL)等。
- 变换域方法:K-SVD等。
- 混合方法:BM3D、BM3D-SAPCA、局部像素分组(LPG-PCA)、ASVD、空间自适应迭代奇异值阈值法(SAIST)等。
线性图像表示

方法
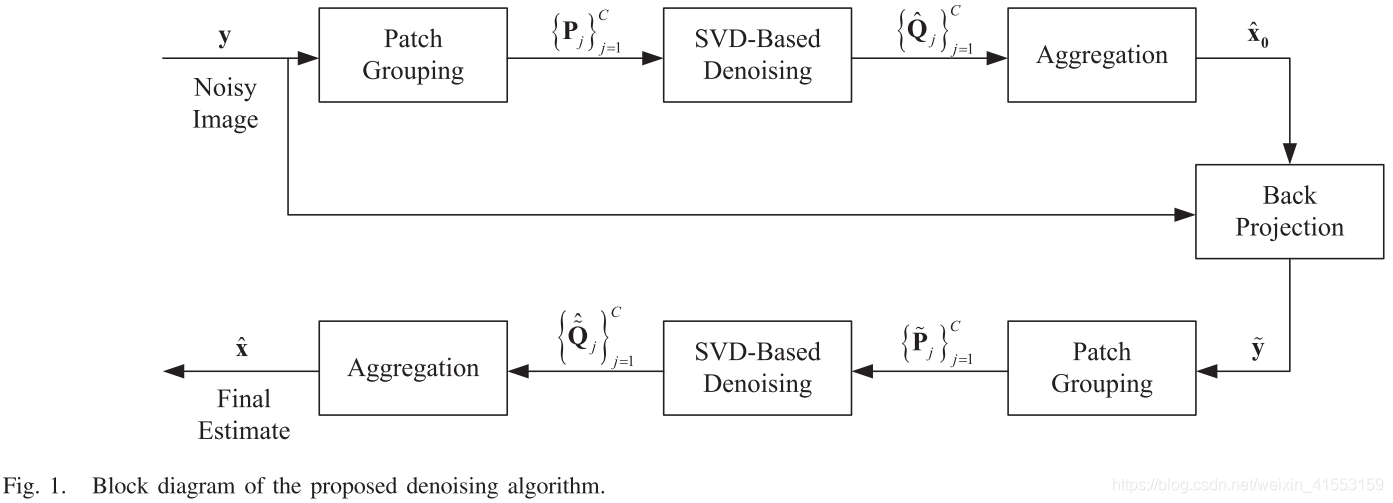
Patch Grouping

SVD-based Denoising

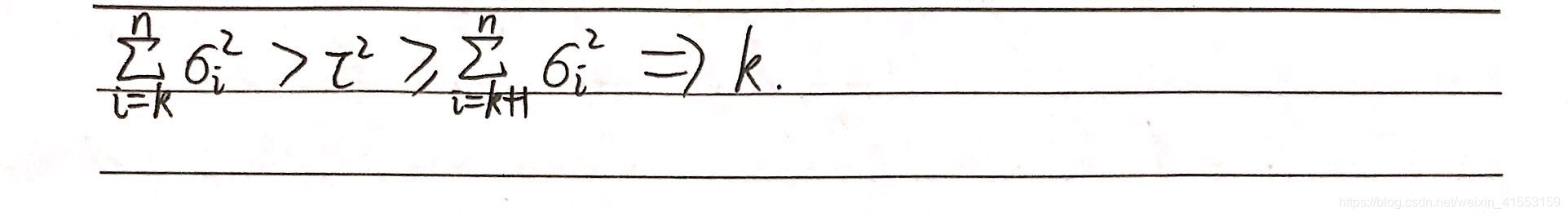

Aggregating

Back Projection

算法流程

实验与讨论
实验细节
PSNR和SSIM的定义:https://www.cnblogs.com/seniusen/p/10012656.html
FSIM的定义:https://blog.csdn.net/xiaoxifei/article/details/84949594
- 10幅大小为512×512图像, τ \tau τ:10-50,pixel:0-255
- 指标:PSNR、FSIM
- 对比方法:PLOW、K-SVD、LPG-PCA、SAIST、BM3D-SAPCA
- 最优参数:L=85, δ \delta δ=0.5, γ \gamma γ=0.65
-
p
a
t
c
h
s
i
z
e
=
{
9
×
9
τ
<
20
10
×
10
20
⩽
τ
<
40
11
×
11
τ
⩾
40
patch\,size=\begin{cases} 9\times \text{9 }\,\,\,\,\,\,\,\,\,\,\tau <20\\ 10\times \text{10 }\,\,\,\,20\leqslant \tau <40\\ 11\times \text{11 }\,\,\,\,\tau \geqslant 40\\ \end{cases}
patchsize=⎩⎪⎨⎪⎧9×9 τ<2010×10 20⩽τ<4011×11 τ⩾40
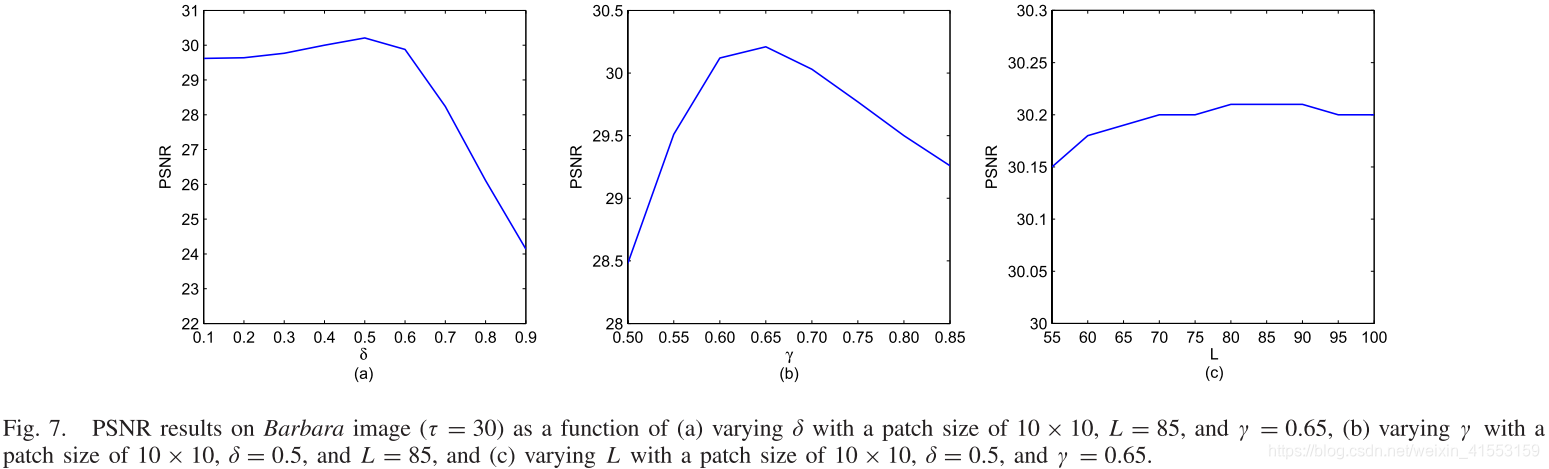
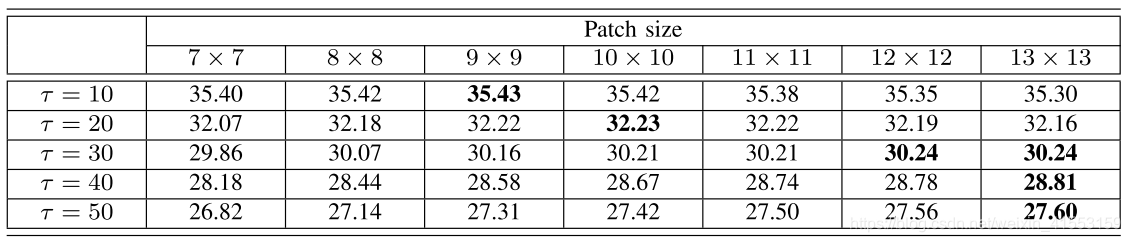
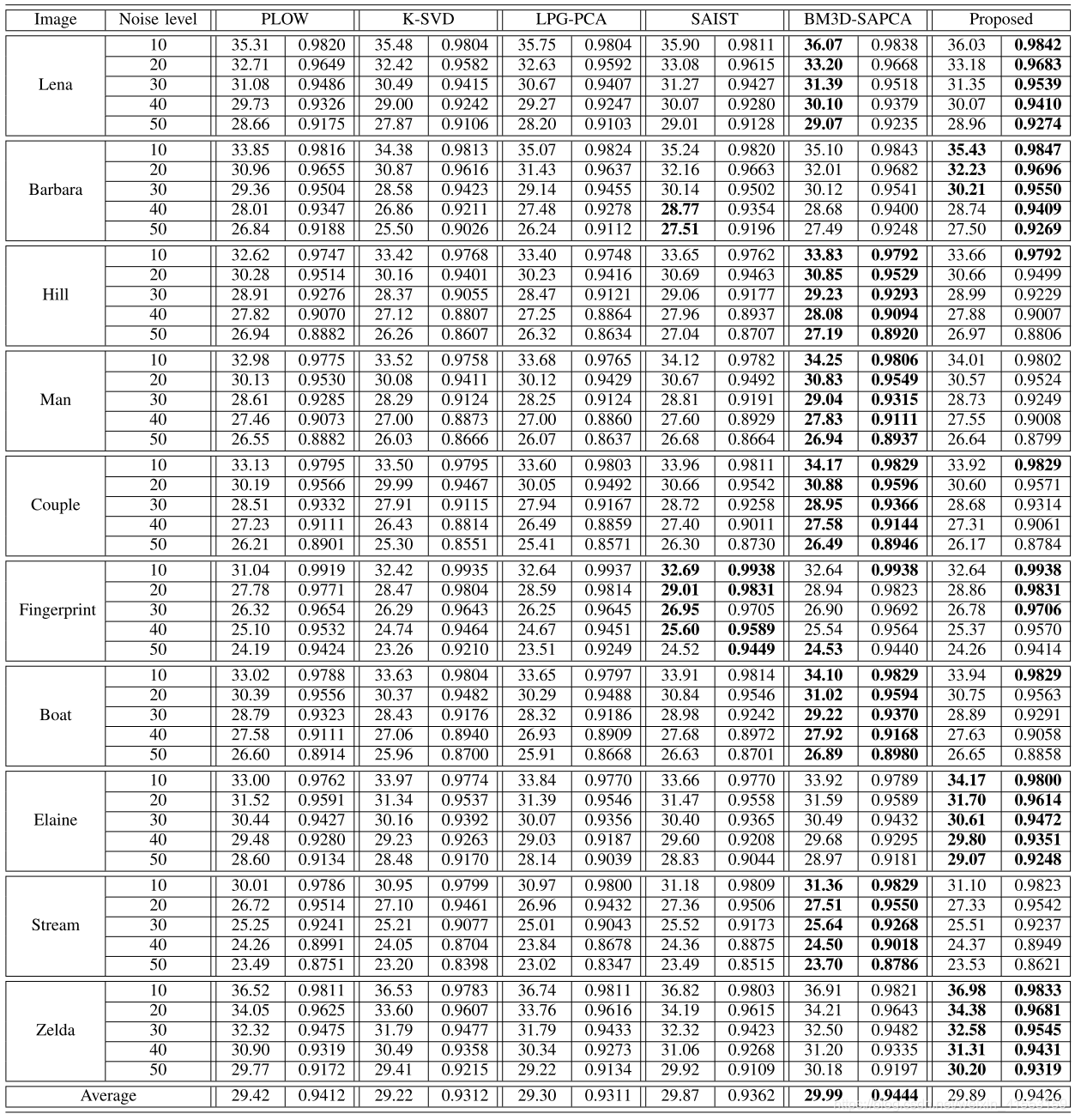
BM3D-SAPCA被认为是图像去噪的最新技术,平均达到了最高的PSNR值,并且略优于我们的方法。然而,我们的方法在具有高重复模式的图像上表现得更好,例如Elaine、Zelda和Barbara。这是因为我们的方法充分利用了这些图像在块分组过程中的非局部冗余性。另一方面,我们的方法比其他方法(除了BM3D-SAPCA)具有更高的FSIM测量值。综上所述,本方法的定量结果与BM3D-SAPCA和SAIST相比具有一定的竞争力,明显优于LPG-PCA、PLOW和K-SVD。

该方法在视觉上接近SAIST和LPG-PCA,优于BM3D-SAPCA、PLOW和K-SVD,尤其是在边缘和纹理区域。
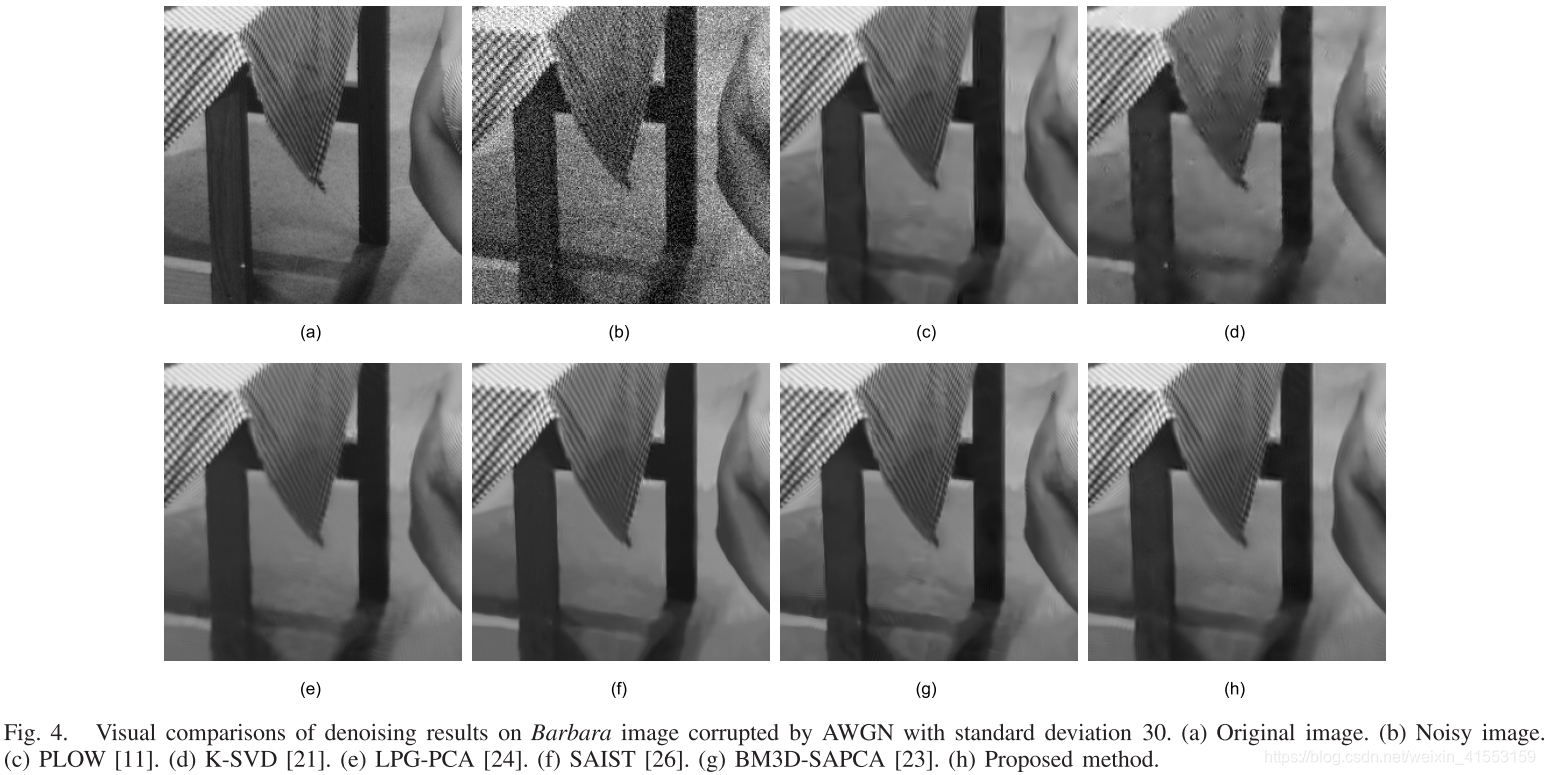
SAIST、LPG-PCA和所提出的去噪方法在真实的视觉感知上非常相似,其中一些边缘和纹理得到了较好的保留,引入的伪影较少。我们注意到,虽然BM3D-SAPCA比我们的方法有更高的PSNR和FSIM测量值,但是BM3D-SAPCA的去噪结果在边缘和平滑区域包含了比我们的结果更明显的伪影。其主要原因是BM3D-SAPCA利用正交变换来表示相似的图像块,并通过阈值化表示系数来降低噪声,从而产生明显的可见伪影。

对于真实噪声图像,我们的方法可以有效地降低噪声,同时保持更精细的特征。

这些方法的三个不同点:
- 图像表示的基本功能是不同的。BM3D使用固定的三维基函数(联合小波和余弦基),这些函数对边缘和纹理的适应性较差。为了提高去噪性能,BM3D-SAPCA将PCA应用于形状自适应小块组,但计算量大。我们的方法使用了一个由奇异值分解得到的自适应基,它比BM3D和BM3D-SAPCA更好地保持了局部的几何结构。
- BM3D利用距离变换系数的欧几里德距离来识别相似的方形块,提高了块匹配的鲁棒性。在BM3D-SAPCA中,通常的方形块被形状自适应的块匹配块所代替,但这会导致复杂的聚集过程,计算量大。与BM3D和BM3D-SAPCA不同,该方法基于欧几里德距离直接在空间域计算相似性度量。
- 在BM3D和BM3D-SAPCA中,第二阶段去噪直接应用于原始含噪图像上,根据第一阶段去噪图像的块相似性将其分组为三维数据阵列。然而,由于噪声的影响,第一阶段的去噪可能包含分组误差,从而导致对噪声图像的基本估计不正确。与BM3D和BM3D-SAPCA不同,我们的第二个去噪阶段是在基本估计值中加入一部分残差图像,即反投影得到的新的含噪图像。新的噪声图像包含了比第一阶段输出更多的结构细节,提高了SVD域中块分组和LRA的精度。
代码
demo(p文件):http://qguo.weebly.com 网站挂了
下载地址:https://download.csdn.net/download/weixin_41553159/85646407
Image Denoising Using Hybrid Singular Value Thresholding Operators(cite:1)
引言
- NLM → \rightarrow →BM3D
- K-SVD,稀疏编码
- LRA-SVD、WNNM
- Gauss混合模型
- DnCNN、FFDNet、CBDNet
软阈值算子
Ref:J.-F. Cai, E. J. Candès, and Z. Shen, ‘‘A singular value thresholding algorithm for matrix completion,’’ SIAM J. Optim., vol. 20, no. 4,pp. 1956–1982, Jan. 2010.


硬阈值算子
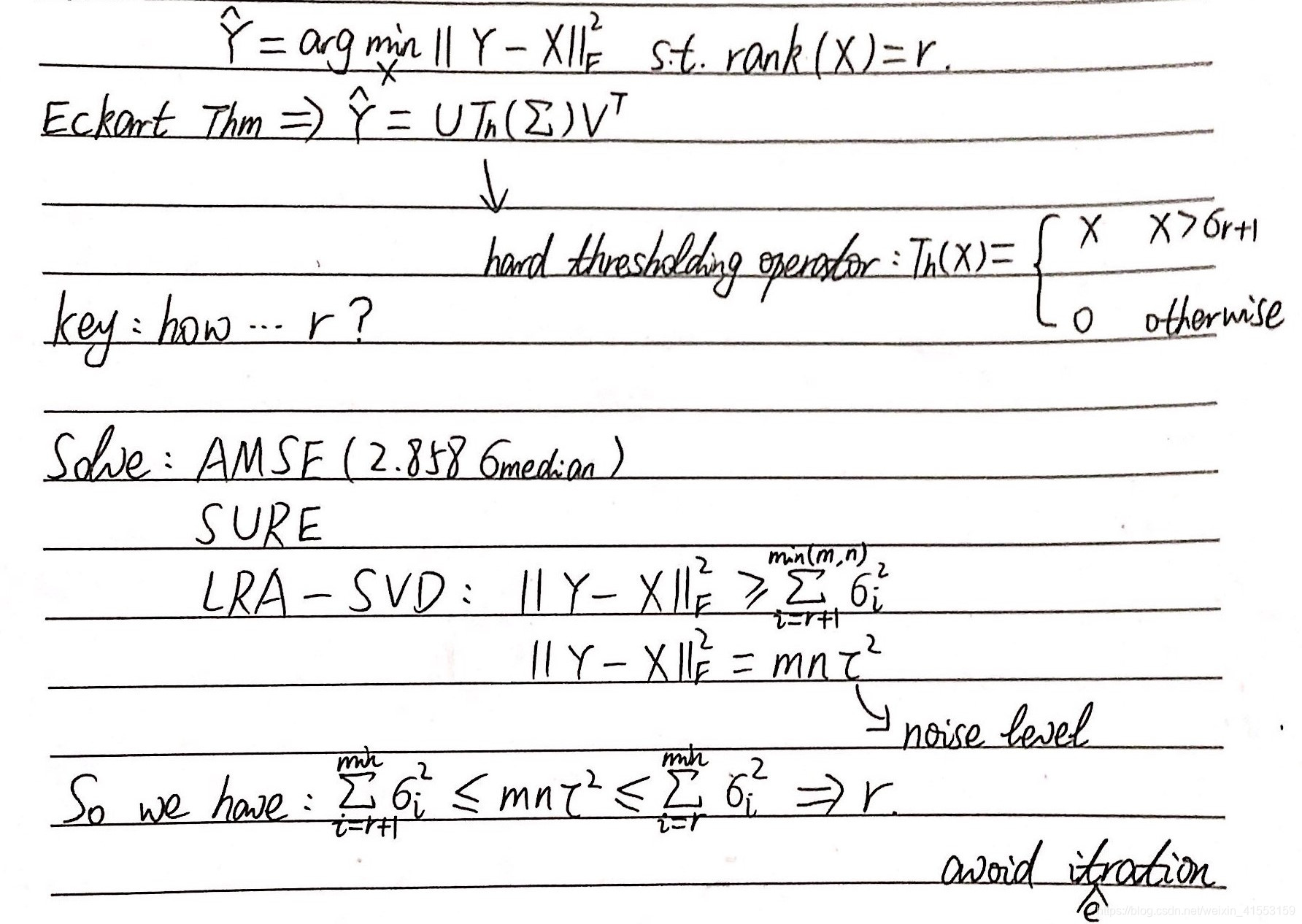
方法:软硬兼施+NSS
本质:对上面一篇论文的改进
噪声残差
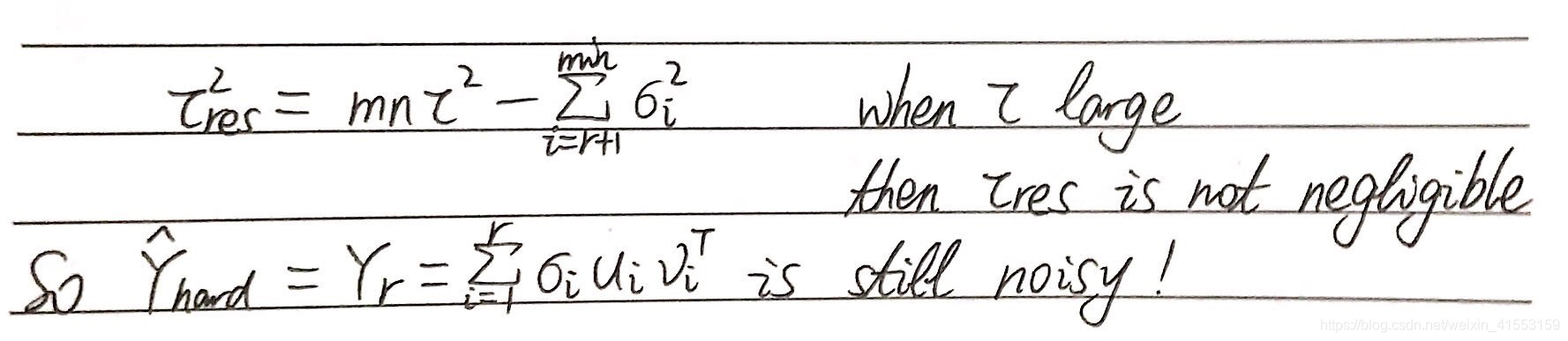
奇异值收缩
Ref:S. H. Jensen, P . C. Hansen, S. D. Hansen, and J. A. Sørensen, ‘‘Reduction of broad-band noise in speech by truncated QSVD,’’ IEEE Trans. Speech Audio Process., vol. 3, no. 6, pp. 439–448, Nov. 1995.
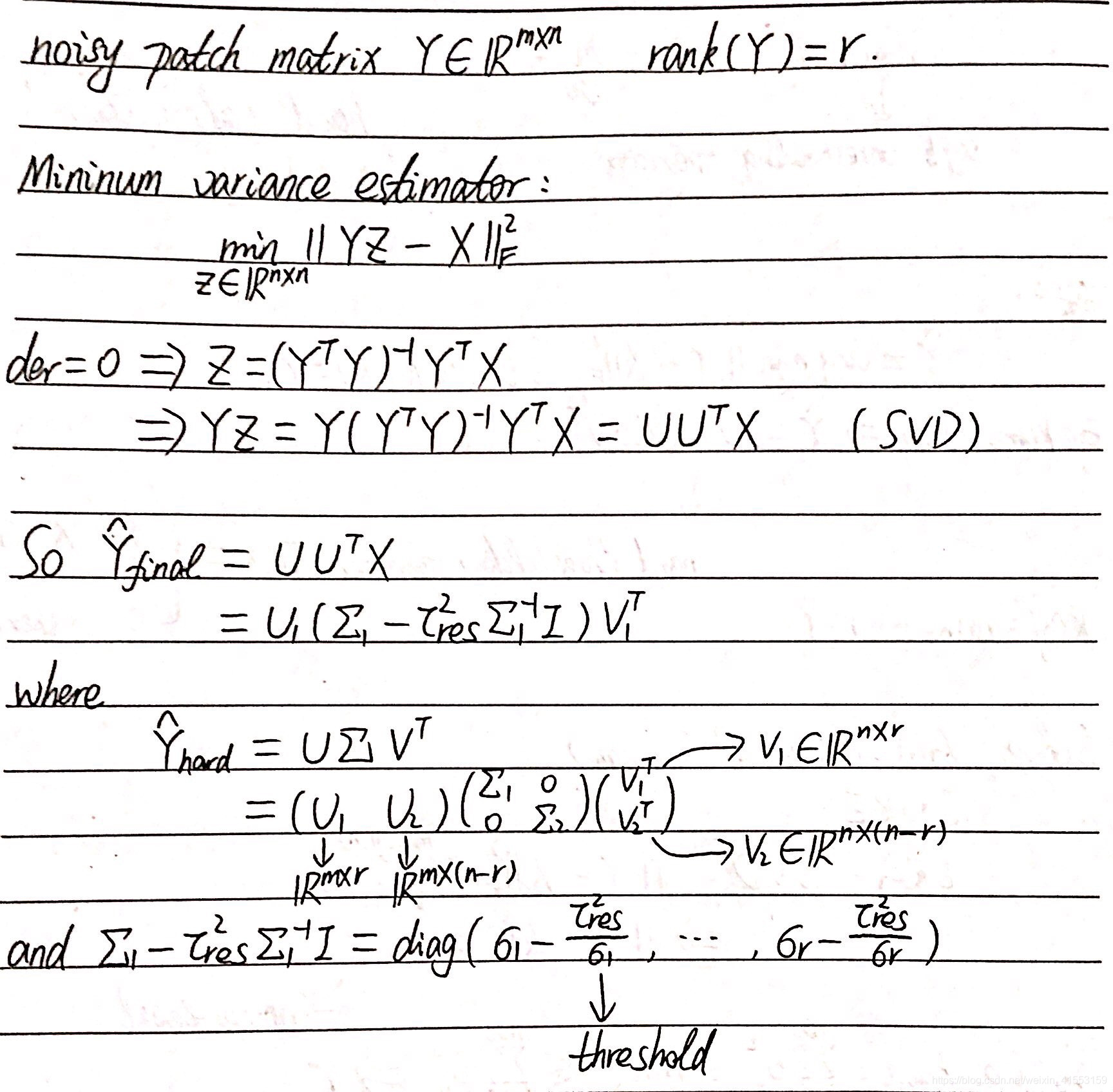
算法流程

实验
- 10幅大小为512×512图像, τ ∈ [ 50 , 100 ] \tau\in[50,100] τ∈[50,100]
- 对比方法:NLM、LRA-SVD、LRA-SVD-S
- 噪声水平: [ 50 , 100 ] [50,100] [50,100]
- 评估指标:PSNR,SSIM
- 参数设置:

所提出的去噪方法有效地提高了LRA-SVD的性能:

所提出的混合方法优于LRA-SVD-S:
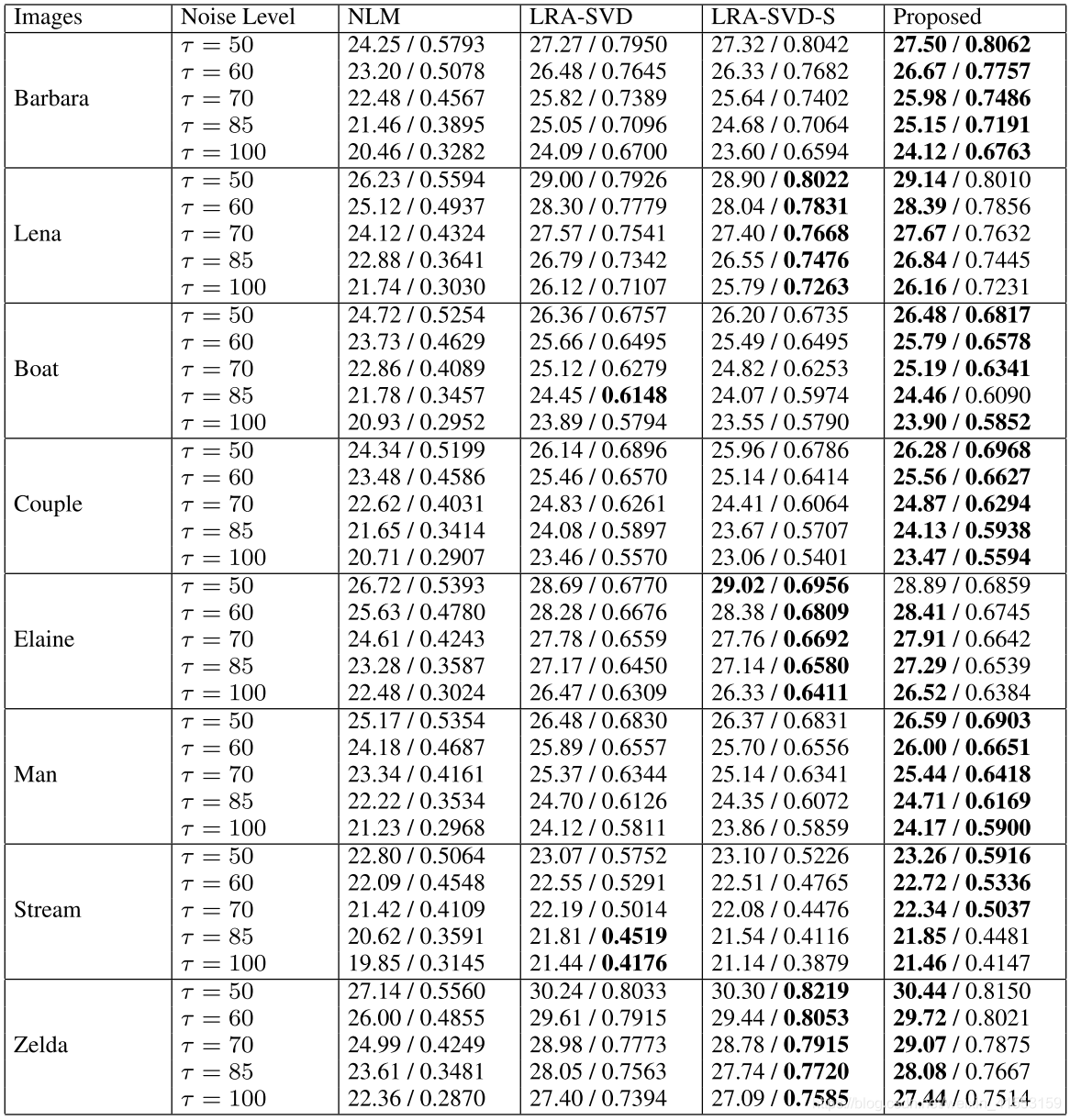



高强度噪声严重破坏了图像的结构信息和纹理细节,四种去噪方法都能有效地抑制噪声。我们的方法略优于LRA-SVD和LRA-SVD-S,在去噪图像的视觉质量方面明显优于NLM。值得注意的是,尽管LRA-SVD、LRASVD-S和我们的方法可以提供更好的降噪性能,但它们也会引入一些视觉伪影。这种限制来自于使用固定的方形小块。


















 1209
1209

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









