






 本文详细介绍了TFRecord格式,包括其用于减少数据IO开销的原因,以及如何制作、读取TFRecord文件,涉及图片、视频数据的编码和解析。此外,还讲解了如何获取TFRecord的特征属性和行数,以及如何进行采样处理,尤其适用于大规模数据集的高效管理。
本文详细介绍了TFRecord格式,包括其用于减少数据IO开销的原因,以及如何制作、读取TFRecord文件,涉及图片、视频数据的编码和解析。此外,还讲解了如何获取TFRecord的特征属性和行数,以及如何进行采样处理,尤其适用于大规模数据集的高效管理。
目录
一、TFRecord简介
1.1 TFRecord格式简介
tfrecord是谷歌专门为tensorflow设计的一种数据格式,tfrecord是一种二进制文件,不仅可以实现对数据的压缩存储,同时也有专门的API可以快速的读取其中存储的内容。一个tfrecord文件内部由很多tf.train.Example组成,这些Example是基于数据压缩编码标准Protobuf进行实现的。每一个Example中包含了一系列的tf.train.Feature属性,每一个feature是一个key-value键值对,其格式如下图所示。
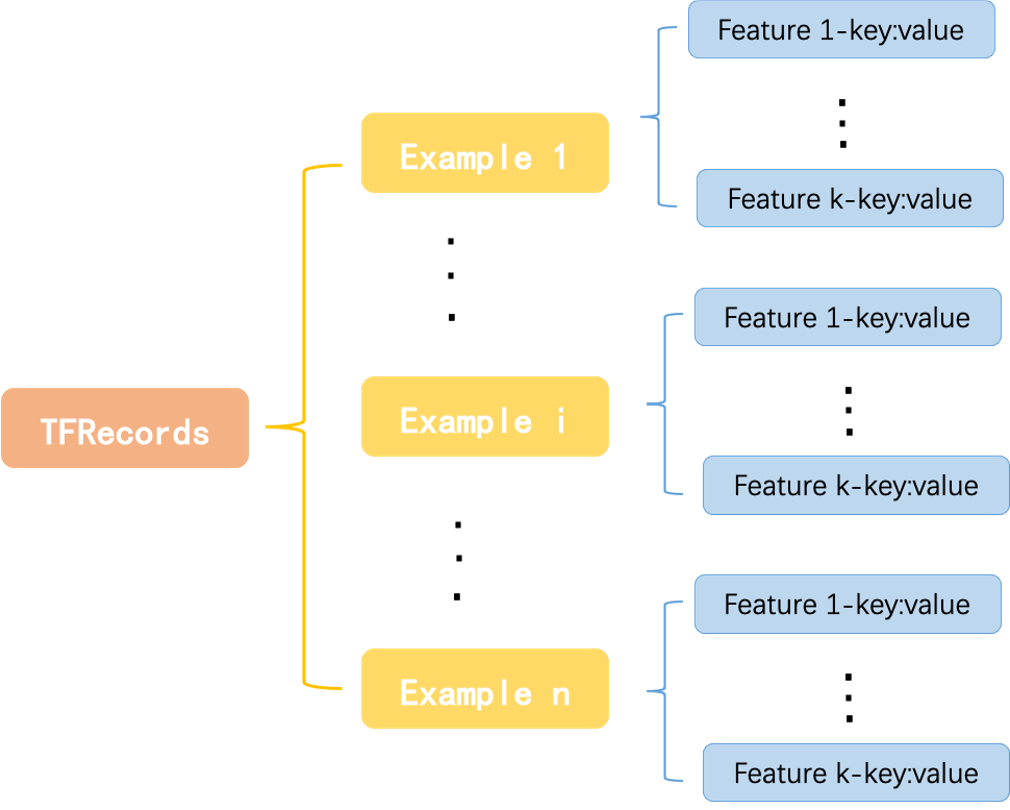
其中key为自定义的sring类型,value可以是如下的类型:
- bytes_list: 可以存储string 和byte两种数据类型。
- float_list: 可以存储float(float32)与double(float64) 两种数据类型 。
- int64_list: 可以存储:bool, enum, int32, uint32, int64, uint64 。
1.2 为什么用TFRecord
tensorflow可以支持多种数据格式,例如可以直接读取图片、视频、文本等数据。在数据集较小时,我们可以把数据全部加在到内存,以便减小数据IO带来的延迟。但当数据量很大时,就只能放在硬盘上一点点读取,如此数据IO会导致整体的速度变慢,同时数据的移动、拷贝也是需要时间的,上述这些情况,将数据制作成TFRecord格式可以得到缓解。
二、TFRecord文件操作
2.1 制作TFRecord文件
# coding=utf-8
import tensorflow as tf
import numpy as np
# The following functions can be used to convert a value to a type compatible
# with tf.Example.
def _bytes_feature(value):
"""Returns a bytes_list from a string / byte."""
if isinstance(value, type(tf.constant(0))):
value = value.numpy() # BytesList won't unpack a string from an EagerTensor.
return tf.train.Feature(bytes_list=tf.train.BytesList(value=[value]))
def _float_feature(value):
"""Returns a float_list from a float / double."""
return tf.train.Feature(float_list=tf.train.FloatList(value=[value]))
def _int64_feature(value):
"""Returns an int64_list from a bool / enum / int / uint."""
return tf.train.Feature(int64_list=tf.train.Int64List(value=[value]))
# 注意如果value值本身是list,那么传递给tf.train.Int64List中的参数是不需要加中括号
def _int64_list_feature(value):
return tf.train.Feature(int64_list=tf.train.Int64List(value=value))
def _bytes_list_feature(value):
# "存放数组"
return tf.train.Feature(bytes_list=tf.train.BytesList(value=[value.astype(np.float32).tostring()]))
# def _int64_list_feature(value):
# return tf.train.Feature(int64_list=tf.train.Int64List(value=[value]))
def serialize_example(feature0, feature1, feature2, feature3, feature4):
"""
Creates a tf.Example message ready to be written to a file.
"""
# Create a dictionary mapping the feature name to the tf.Example-compatible
# data type.
feature = {
'feature0': _int64_feature(feature0),
'feature1': _int64_list_feature(feature1),
'feature2': _bytes_feature(feature2),
'feature3': _float_feature(feature3),
'feature4': _bytes_list_feature(feature4)
}
# Create a Features message using tf.train.Example.
example_proto = tf.train.Example(features=tf.train.Features(feature=feature))
return example_proto.SerializeToString()
filename = 'test.tfrecord'
# Write the `tf.Example` observations to the file.
with tf.io.TFRecordWriter(filename) as writer:
for i in range(10):
example = serialize_example(1, [1, 1, 9], "test", 1.4, np.array([1, 2, 3]))
writer.write(example)
2.2 读取TFRecord文件
# 紧接着上面
feature_description = {
'feature0': tf.io.FixedLenFeature((), tf.int64, default_value=0),
'feature1': tf.io.FixedLenFeature((3), tf.int64, default_value=[-1, -1, -1]),
'feature2': tf.io.FixedLenFeature((), tf.string, default_value=''),
'feature3': tf.io.FixedLenFeature((), tf.float32, default_value=0.0),
'feature4': tf.io.FixedLenFeature((), tf.string)
}
def _parse_function(example_proto):
# Parse the input `tf.Example` proto using the dictionary above.
feature = tf.io.parse_single_example(example_proto, feature_description)
# 注意要对数组就行加码,且数组元素对应的类型一定要同最开始的一样。
feature['feature4'] = tf.decode_raw(feature['feature4'], tf.float32)
return feature
raw_dataset = tf.data.TFRecordDataset('test.tfrecord')
dataset = raw_dataset.map(_parse_function)
dataset = dataset.batch(1)
iterator = dataset.make_one_shot_iterator()
data = iterator.get_next()
with tf.Session() as sess:
init_op = tf.global_variables_initializer()
sess.run(init_op)
datas = []
for i in range(1):
my_data = sess.run([data])
2.3 生成并读取含有图片的TFRecord
上面的例子中,只是示范了如何将标量存储到tfrecord文件中,下面演示一下如何将图片存储到tfrecord中,由于tfrecord文件不支持直接存储数组,但可以存储字节串,因此我们需要以二进制字节吗的形式读取片。
# 生产tfrecord
import tensorflow as tf
import cv2
writer = tf.python_io.TFRecordWriter("my_img.tfrecord")
path = ""
img = cv2.imread("my_image.jpeg")
encode_jpg = tf.io.encode_jpeg(img)
with tf.Session() as sess:
encode_jpg = sess.run([encode_jpg])
tf_example = tf.train.Example(
features=tf.train.Features(
feature={
'image/encoded': tf.train.Feature(bytes_list=tf.train.BytesList(value=[encode_jpg[0]]))
}
))
writer.write(tf_example.SerializeToString())
writer.close()
# 读取tfrecord
features = {
"image/encoded": tf.io.FixedLenFeature([1], tf.string)
}
raw_image_dataset = tf.data.TFRecordDataset('test_1.tfrecord')
def _parse_image_function(example_proto):
data = tf.io.parse_single_example(example_proto, features)
data['image/encoded'] = tf.image.decode_image(data['image/encoded'][0], channels=3)
return data
dataset = raw_image_dataset.map(_parse_image_function)
dataset = dataset.batch(1)
# dataset = dataset.shuffle(1000)
# dataset = dataset.prefetch(buffer_size=10)
iterator = dataset.make_one_shot_iterator()
data = iterator.get_next()
with tf.Session() as sess:
init_op = tf.global_variables_initializer()
sess.run(init_op)
for i in range(1):
my_img = sess.run([data])
2.4 生成并读取含有视频的TFRecord
以下代码来自Video TFRecords: How to Efficiently Load Video Data,略有修改。
# 生成tfrecord
import pathlib
import tensorflow as tf
import numpy as np
import imageio
from tqdm import tqdm
def _int64_feature(value):
return tf.train.Feature(int64_list=tf.train.Int64List(value=[value]))
def _bytes_feature(value):
return tf.train.Feature(bytes_list=tf.train.BytesList(value=[value]))
def mp4_2_numpy(filename):
"""Reads a video and returns its contents in matrix form.
Args:
filename (str): a path to a video
Returns:
np.array(): matrix contents of the video
"""
vid = imageio.get_reader(filename, 'ffmpeg')
# read all of video frames resulting in a (T, H, W, C) matrix
data = np.stack(list(vid.iter_data()))
return data
def line2example(line):
"""Reads a line from the datafile and returns an
associated TFRecords example containing the encoded data.
Args:
line (str): a line from the datafile
(formatted as {filepath} {label})
Returns:
tf.train.SequenceExample: resulting TFRecords example
"""
# extract information on dataexample
fn, label = line.split(' ')
label = int(label)
# read matrix data and save its shape
video_data = mp4_2_numpy(fn)
t, h, w, c = video_data.shape
# save video as list of encoded frames using tensorflow's operation
img_bytes = [tf.image.encode_jpeg(frame, format='rgb') for frame in video_data]
with tf.Session() as sess:
img_bytes = sess.run(img_bytes)
sequence_dict = {}
# create a feature for each encoded frame
img_feats = [tf.train.Feature(bytes_list=tf.train.BytesList(value=[imgb])) for imgb in img_bytes]
# save video frames as a FeatureList
sequence_dict['video_frames'] = tf.train.FeatureList(feature=img_feats)
# also store associated metadata
context_dict = {}
context_dict['filename'] = _bytes_feature(fn.encode('utf-8'))
context_dict['label'] = _int64_feature(label)
context_dict['temporal'] = _int64_feature(t)
context_dict['height'] = _int64_feature(h)
context_dict['width'] = _int64_feature(w)
context_dict['depth'] = _int64_feature(c)
# combine list + context to create TFRecords example
sequence_context = tf.train.Features(feature=context_dict)
sequence_list = tf.train.FeatureLists(feature_list=sequence_dict)
example = tf.train.SequenceExample(context=sequence_context, feature_lists=sequence_list)
return example
def create_tfrecords(datafile_path, save_path):
"""Creates a TFRecords dataset from video files.
Args:
datafile_path (str): a path to the formatted datafiles (includes train.txt, etc.)
save_path (str): where to save the .tfrecord files
"""
save_path = pathlib.Path(save_path)
save_path.mkdir(exist_ok=True, parents=True)
# create a TFRecord for each datasplit
for dset_name in ['train.txt', 'test.txt', 'val.txt']:
# read the lines of the datafile
with open(datafile_path + dset_name, 'r') as f:
lines = f.readlines()
# write each example to a {split}.tfrecord (train.tfrecord, etc.)
record_file = str(save_path/'{}.tfrecord'.format(dset_name[:-4]))
with tf.python_io.TFRecordWriter(record_file) as writer:
for line in tqdm(lines):
example = line2example(line)
writer.write(example.SerializeToString())
# 读取tfrecord
# define the features to decode
sequence_features = {
'video_frames': tf.FixedLenSequenceFeature([], dtype=tf.string)
}
context_features = {
'filename': tf.io.FixedLenFeature([], tf.string),
'height': tf.io.FixedLenFeature([], tf.int64),
'width': tf.io.FixedLenFeature([], tf.int64),
'depth': tf.io.FixedLenFeature([], tf.int64),
'temporal': tf.io.FixedLenFeature([], tf.int64),
'label': tf.io.FixedLenFeature([], tf.int64),
}
IMAGE_SIZE_H = 244
IMAGE_SIZE_W = 224
@tf.function
def resize(img):
return tf.image.resize(img, [IMAGE_SIZE_H, IMAGE_SIZE_W])
def _parse_example(example_proto):
# Parse the input tf.train.Example using the dictionary above.
context, sequence = tf.parse_single_sequence_example(example_proto,
context_features=context_features,
sequence_features=sequence_features)
# extract the expected shape
shape = (context['temporal'], context['height'], context['width'], context['depth'])
## the golden while loop ##
# loop through the feature lists and decode each image seperately
# decoding the first video
video_data = tf.image.decode_image(tf.gather(sequence['video_frames'], [0])[0])
video_data = tf.expand_dims(video_data, 0)
i = tf.constant(1, dtype=tf.int32)
# condition of when to stop / loop through every frame
cond = lambda i, _: tf.less(i, tf.cast(context['temporal'], tf.int32))
# reading + decoding the i-th image frame
def body(i, video_data):
# get the i-th index
encoded_img = tf.gather(sequence['video_frames'], [i])
# decode the image
img_data = tf.image.decode_image(encoded_img[0])
# append to list using tf operations
video_data = tf.concat([video_data, [img_data]], 0)
# update counter & new video_data
return (tf.add(i, 1), video_data)
_, video_data = tf.while_loop(cond, body, [i, video_data],
shape_invariants = [i.get_shape(), tf.TensorShape([None])])
# use this to set the shape + dtype
video_data = tf.reshape(video_data, shape)
video_data = tf.cast(video_data, tf.float32)
# resize each frame in video -- can apply different augmentations etc. like this
video_data = tf.map_fn(resize, video_data, back_prop=False, parallel_iterations=10)
label = context['label']
return video_data, label
# create the dataset
dataset = tf.data.TFRecordDataset('train.tfrecord') \
.map(_parse_example) \
.batch(2)
iterator = dataset.make_one_shot_iterator()
next_element = iterator.get_next()
# use standard tf training setup
with tf.Session() as sess:
batch_vid, batch_label = sess.run(next_element)
print(batch_vid.shape, batch_label)
三、获取TFRecord文件的特征属性以及行数
当我们不知道一个tfrecord文件的特征格式时,就不方便读取在其中的数据,通过如下的代码,可以获取到tfrecord文件中有哪些特征字段及格式。
def getTFRecordFormat(files):
# files: [file_path1, file_path2,....]
with tf.Session() as sess:
# filenames = [path]
# 加载TFRecord数据
ds = tf.data.TFRecordDataset(files)
ds = ds.batch(1)
ds = ds.prefetch(buffer_size=tf.contrib.data.AUTOTUNE)
iterator = ds.make_one_shot_iterator()
# 为了加快速度,仅仅简单拿一组数据看下结构
batch_data = iterator.get_next()
while True:
res = sess.run(batch_data)
for serialized_example in res:
example_proto = tf.train.Example.FromString(serialized_example)
features = example_proto.features
for key in features.feature:
feature = features.feature[key]
if len(feature.bytes_list.value) > 0:
ftype = 'bytes_list'
fvalue = feature.bytes_list.value
if len(feature.float_list.value) > 0:
ftype = 'float_list'
fvalue = feature.float_list.value
if len(feature.int64_list.value) > 0:
ftype = 'int64_list'
fvalue = feature.int64_list.value
result = '{0} : {1} {2}'.format(key, ftype, len(fvalue))
print(result)
break
print("*"*20)
break
获取tfrecord文件中的数据行数
count = 0
for record in tf.python_io.tf_record_iterator(file):
count += 1
print(count)
五、对TFRecord文件进行采样
在推荐广告领域,负样本占了绝大多数,如果直接在所有的数据上训练,很有可能会对模型的性能带来负面影响,因此有必要对负样本进行降采样,假设是对已经生成好的tfrecord文件进行采样10%。
import tensorflow as tf
import random
feature_map = {
'label':tf.FixedLenFeature([1], tf.float32),
'dense':tf.FixedLenFeature([215], tf.float32),
'cat': tf.FixedLenFeature([50], tf.int64)
}
def _parse_example(example):
feat_tensor_maps = tf.parse_single_example(example, feature_map)
return feat_tensor_maps
def input_layer():
filenames = tf.placeholder(tf.string, shape=[None])
dataset = tf.data.TFRecordDataset(filenames)
dataset = dataset.map(_parse_example) # Parse the record into tensors.
dataset = dataset.batch(1000)
dataset = dataset.prefetch(buffer_size=tf.contrib.data.AUTOTUNE)
#dataset = dataset.repeat() # Repeat the input indefinitely.
iterator = dataset.make_initializable_iterator()
return filenames, iterator, iterator.get_next()
tf_writer = tf.python_io.TFRecordWriter('sampled_sample.tfrecords')
tfrecord_path = 'all_sample.tfrecords'
filenames_tensor, iterator, ele_tensor = input_layer()
i = 0
try:
with tf.Session() as sess:
sess.run(iterator.initializer, feed_dict={filenames_tensor: [tfrecord_path]})
while True:
i += 1
fea_label, = sess.run([ele_tensor])
cat_fea = fea_label['cat']
dense_fea = fea_label['dense']
label = fea_label['label']
example = tf.train.Example()
for i in range(label.shape[0]):
if label[i][0] == 0 and random.randint(1, 10) != 1:
continue
features = tf.train.Features(
feature={
"cat": tf.train.Feature(
int64_list=tf.train.Int64List(value=cat_fea[i])),
"label": tf.train.Feature(
float_list=tf.train.FloatList(value=label[i])),
'dense': tf.train.Feature(float_list=tf.train.FloatList(value=dense_fea[i]))
}
)
tf_example = tf.train.Example(features=features)
serialized = tf_example.SerializeToString()
tf_writer.write(serialized)
except Exception as e:
print(e)
tf_writer.close()
[1]: 高效的数据压缩编码方式 Protobuf
[2]: 深度学习12-TFRecord详解
[3]: TFRecord 和 tf.Example

















 746
746

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









