










问题描述:使用串口队列中,发现有时候队列接收到的数据长度与真实的不符合。应该是中断和主流程冲突导致,所以记录此文。以下是嵌入式编程中解决竞态条件的常见方法及代码实例(以C语言为例):
一、基础同步机制
1. 互斥锁 (Mutex)
最常见的保护共享资源方式,通过加锁/解锁实现串行访问
1// FreeRTOS示例
2SemaphoreHandle_t mutex = xSemaphoreCreateMutex();
3
4void task1(void *pvParam) {
5 xSemaphoreTake(mutex, portMAX_DELAY); // 获取锁
6 // 操作共享资源
7 xSemaphoreGive(mutex); // 释放锁
8}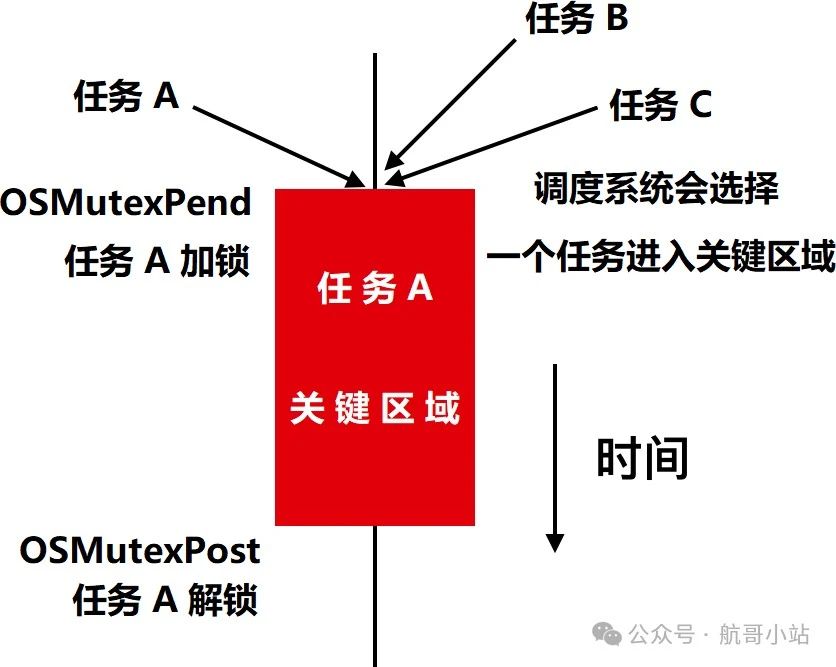
2. 自旋锁 (Spinlock)
适用于多核场景的忙等待锁
1// Linux内核示例
2spinlock_t my_lock;
3spin_lock(&my_lock);
4// 临界区操作
5spin_unlock(&my_lock);二、原子操作
1. C11标准原子操作
1#include <stdatomic.h>
2atomic_int counter = ATOMIC_VAR_INIT(0);
3
4void increment(void) {
5 atomic_fetch_add(&counter, 1);
6}2. 内联汇编实现(ARM Cortex-M)
1__asm volatile("ldrex r0, [%0] \n"
2 "add r0, r0, #1 \n"
3 "strex r1, r0, [%0]"
4 ::"r"(&counter));三、高级防御策略
1. 中断屏蔽
1// STM32 HAL库示例
2uint32_t primask = __get_PRIMASK();
3__disable_irq(); // 关中断
4// 临界区操作
5__set_PRIMASK(primask); // 恢复中断状态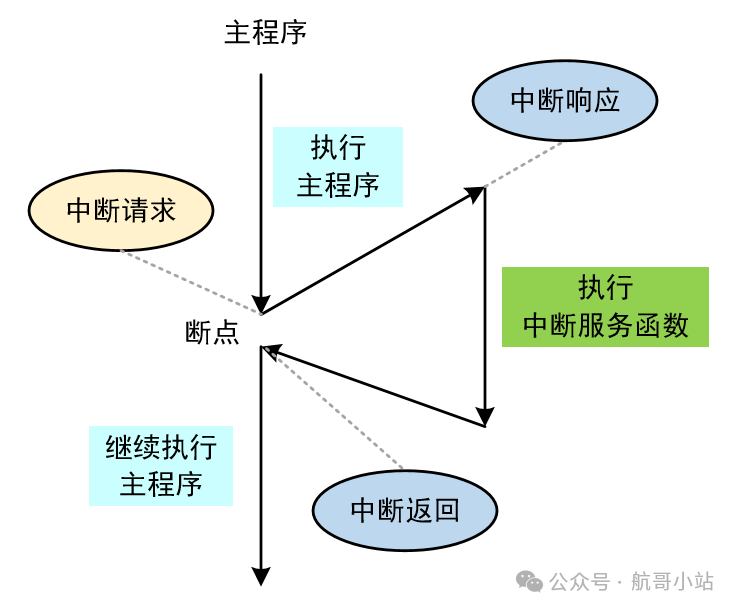
2. 内存屏障 (Memory Barrier)
1// 防止编译器/CPU重排序
2__asm volatile("dmb ish" ::: "memory"); // ARM数据存储屏障3. 无锁数据结构
CAS(Compare-And-Swap)实现队列:
1struct node {
2 int data;
3 struct node *next;
4};
5
6void push(struct node **head, int data) {
7 struct node *new_node = malloc(sizeof(struct node));
8 new_node->data = data;
9 do {
10 new_node->next = *head;
11 } while(!__sync_bool_compare_and_swap(head, new_node->next, new_node));
12}
四、特殊场景解决方案
1. 双缓冲技术
适用于数据采集-处理分离场景:
1volatile uint8_t active_buffer = 0;
2uint32_t buffer[2][256];
3
4// 采集中断服务程序
5void ADC_IRQHandler() {
6 static uint16_t index = 0;
7 buffer[active_buffer][index++] = ADC_VALUE;
8 if(index >= 256) {
9 index = 0;
10 active_buffer ^= 1; // 切换缓冲区
11 }
12}2. 资源副本技术
1// 主程序读取副本
2static struct SensorData working_copy;
3
4void update_data(void) {
5 struct SensorData temp;
6 memcpy(&temp, &shared_data, sizeof(temp)); // 原子拷贝
7 // 使用temp副本处理数据
8}总结表格
| 方法 | 适用场景 | 性能影响 | 实现复杂度 |
|---|---|---|---|
| 互斥锁 | 通用共享资源保护 | 中 | 低 |
| 原子操作 | 简单变量操作 | 低 | 中 |
| 中断屏蔽 | 单核中断敏感操作 | 高 | 低 |
| 无锁结构 | 高并发读写场景 | 极低 | 高 |
| 双缓冲 | 生产者-消费者模式 | 低 | 中 |
实际开发中需要根据实时性要求(如中断延迟容忍度)、性能需求(吞吐量要求)和资源限制(内存/CPU能力)综合选择方案。对于关键系统,建议组合使用多种机制(如原子操作+内存屏障)实现多重保护。
五、关闭中断和使用原子操作来处理竞态条件,哪一个更加优秀一点?
关闭中断和使用原子操作都可以用于处理竞态条件,但它们各有优劣,在不同场景下有不同的适用性,很难简单地说哪一个更加优秀,下面从多个方面对它们进行对比分析:
1. 性能方面
- 关闭中断
- 优点:实现简单,对于一些简单的临界区代码,关闭中断可以快速地保证操作的原子性,避免中断干扰,减少上下文切换的开销。
- 缺点:关闭中断会影响整个系统的实时性,因为在中断关闭期间,其他所有的中断请求都会被延迟处理,可能导致一些紧急事件无法及时响应。如果关闭中断的时间过长,还可能会影响系统的稳定性。
- 原子操作
- 优点:原子操作通常是由硬件直接支持的,执行速度非常快,不会像关闭中断那样影响系统的实时性,因为它不会阻止其他中断的响应。在多核处理器中,原子操作可以在不影响其他核心的情况下完成对共享资源的访问。
- 缺点:原子操作的实现依赖于硬件支持,对于复杂的操作可能无法直接使用原子操作来完成。而且,原子操作的指令通常比较复杂,使用不当可能会导致性能下降。
2. 代码复杂度方面
- 关闭中断
- 优点:代码实现简单,只需要在临界区前后分别调用关闭和打开中断的函数即可。例如,在 ARM Cortex - M 系列中,可以使用
__disable_irq()和__enable_irq()函数来关闭和打开中断。__disable_irq(); // 关闭中断 // 临界区代码 shared_variable++; __enable_irq(); // 打开中断 - 缺点:如果临界区代码嵌套过多,或者在临界区中调用了可能会再次触发中断的函数,可能会导致代码逻辑混乱,增加调试难度。
- 优点:代码实现简单,只需要在临界区前后分别调用关闭和打开中断的函数即可。例如,在 ARM Cortex - M 系列中,可以使用
- 原子操作
- 优点:在支持原子操作的硬件平台上,使用原子操作可以使代码更加简洁明了,只需要调用相应的原子操作函数即可完成对共享资源的访问。例如,在 ARM 架构中,可以使用
__LDREXW和__STREXW函数来实现原子加载和存储操作。uint32_t temp; do { temp = __LDREXW(&shared_variable); // 原子加载 } while (__STREXW(temp + 1, &shared_variable)); // 原子存储 - 缺点:原子操作的使用需要对硬件和编译器有一定的了解,对于一些复杂的操作,可能需要组合多个原子操作来实现,增加了代码的复杂度。
- 优点:在支持原子操作的硬件平台上,使用原子操作可以使代码更加简洁明了,只需要调用相应的原子操作函数即可完成对共享资源的访问。例如,在 ARM 架构中,可以使用
3. 可移植性方面
- 关闭中断
- 优点:关闭中断是一种比较通用的方法,大多数处理器都提供了关闭和打开中断的机制,因此代码的可移植性相对较高。
- 缺点:不同处理器的中断控制指令和函数可能有所不同,需要根据具体的处理器进行调整。而且,在一些实时操作系统中,关闭中断的操作可能会受到系统的限制。
- 原子操作
- 优点:如果使用的是标准的 C11 原子操作库(如
stdatomic.h),代码的可移植性会比较好,因为这些库函数在不同的编译器和硬件平台上都有较好的支持。 - 缺点:一些特定的硬件平台可能有自己独特的原子操作指令和函数,如果使用了这些特定的指令和函数,代码的可移植性会受到影响。
- 优点:如果使用的是标准的 C11 原子操作库(如
适用场景总结
- 关闭中断适用于:临界区代码非常简单,执行时间很短,并且对系统实时性要求不高的场景。例如,在一些简单的嵌入式系统中,对一个共享变量的简单读写操作可以使用关闭中断的方式来保证原子性。
- 原子操作适用于:对系统实时性要求较高,临界区代码比较复杂,或者需要在多核处理器上进行并发访问的场景。例如,在多线程或多任务的实时操作系统中,对共享资源的访问可以使用原子操作来提高性能和保证数据的一致性。
本人在HC32F460芯片上尝试测试,使用原子操作,串口最高1.5Mb正常使用;使用开关中断的方式,1Mb以及以上的速率就会出现问题。
(欢迎关注我的个人公众号,领取更多粉丝福利)

















 817
817

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









