







 本文探讨了在MySQL中,从大量数据表中使用LIMIT进行分页查询的性能问题。通过对比`LIMIT 0,100`和`LIMIT 10000000,100`的查询效率,指出后者存在明显性能下降。提出使用子查询和筛选条件作为优化方案,以提高查询速度。"
7421979,173622,Lua编程入门指南,"['脚本语言', 'Lua编程', '编程基础', '动态类型', '函数']
本文探讨了在MySQL中,从大量数据表中使用LIMIT进行分页查询的性能问题。通过对比`LIMIT 0,100`和`LIMIT 10000000,100`的查询效率,指出后者存在明显性能下降。提出使用子查询和筛选条件作为优化方案,以提高查询速度。"
7421979,173622,Lua编程入门指南,"['脚本语言', 'Lua编程', '编程基础', '动态类型', '函数']
使用子查询和筛选条件能够很好地避免这个问题
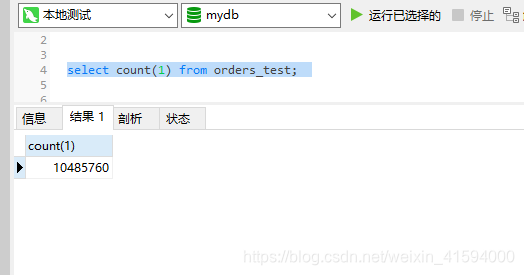
首先我们有个需求,从10000000 万数据量的orders_test表里取出100条数据,至于怎么取没有要求。
表结构如下:
CREATE TABLE `orders_test` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`o_date` date DEFAULT NULL,
`c_id` varchar(50) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=10944333 DEFAULT CHARSET=utf8表数据量:
使用以下语句来取100条看看:
select * from orders_test order by id limit 10,100;
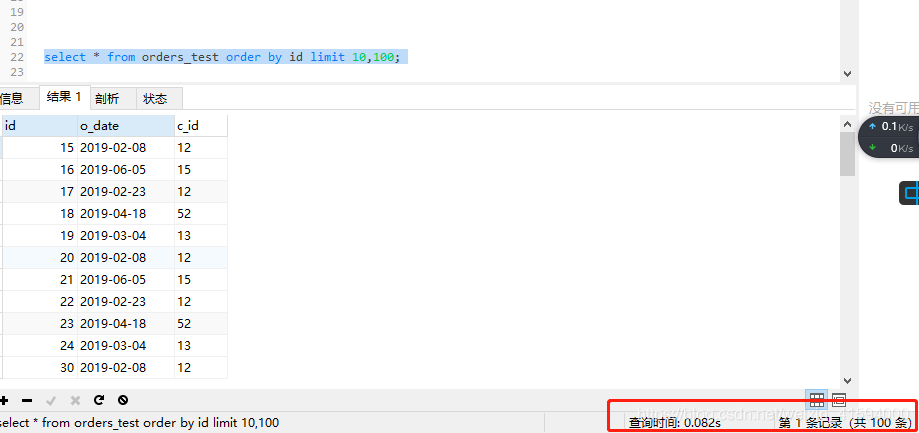
可以看到还是比较快的
使用以下语句试试看:
select * from orders_test order by id limit 10000000,100;
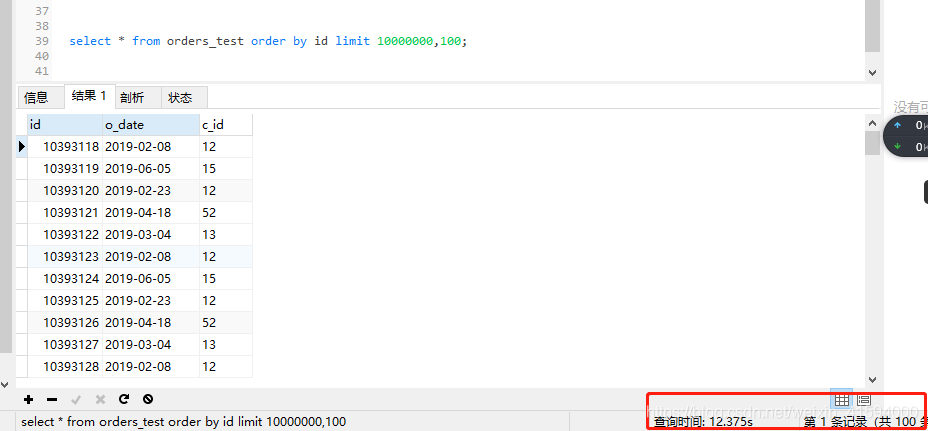
可以看到该语句用时较长
优化方案:
使用子查询和筛选条件能够很好地避免这个问题
select * from orders_test a where a.id >=
(select id from orders_test b where id > 9999999 ORDER BY b.id limit 1)
limit 100
> OK
> 时间: 0.036s
这里效率有一定的提升

















 3976
3976

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









