







Mysql培训第三天
索引
索引:索引的出现的就是为了提高数据的查询效率,就像书的目录一样。没有目录找想看的东西就好比全表扫描。
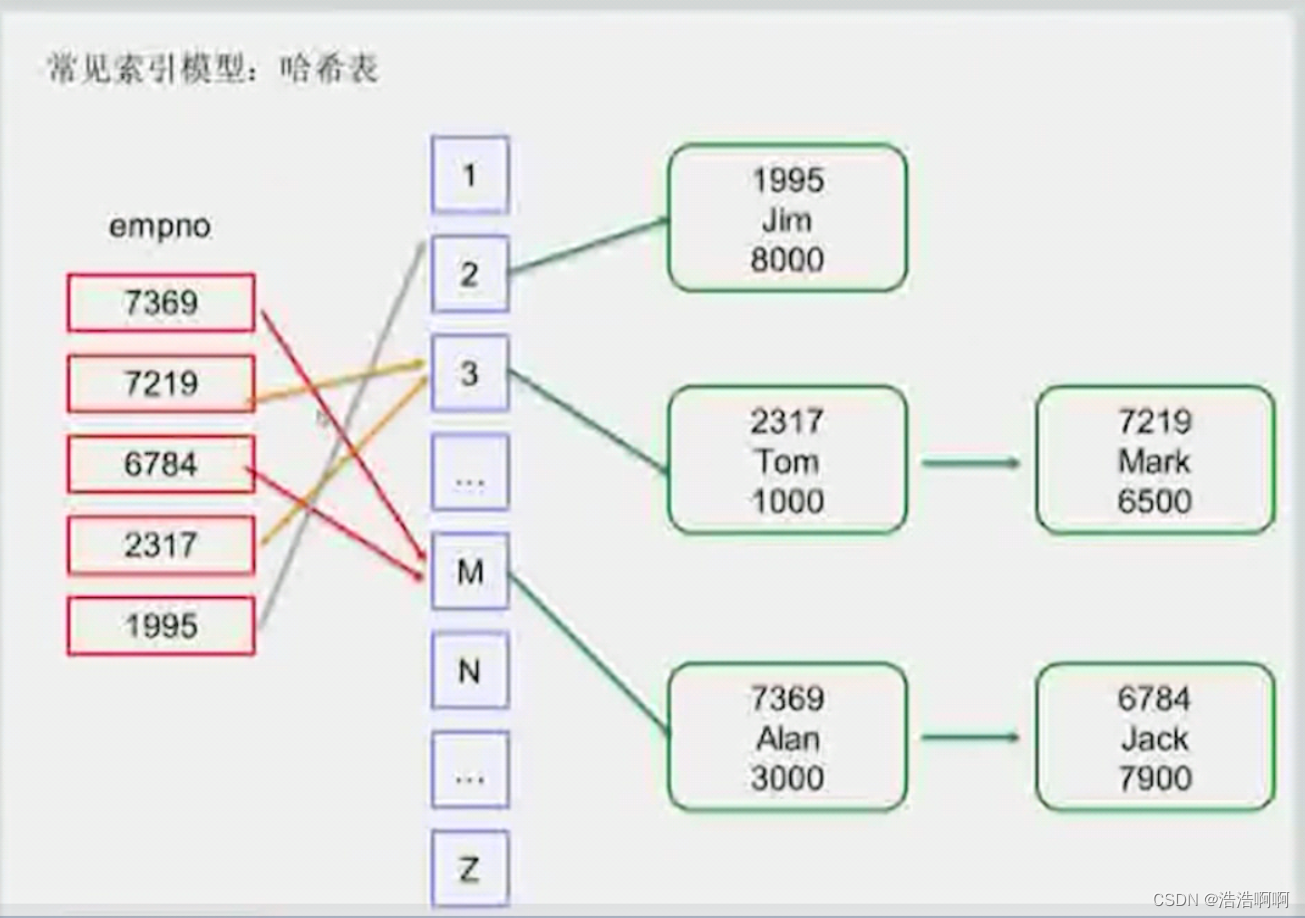
常见索引模型:哈希表
最简单的哈希算法: 一千万行员工编号数据,对它整除100然后取模,就可以把它分成100份,放在100个哈希桶中。
进入同一个哈希桶内,叫哈希碰撞,哈希表后面有链表,发生哈希碰撞后,把所有发生碰撞的数串联在后面。
好处: 插入数据特别快(直接插到相应的哈希桶后面就行)
坏处: 1.没有办法做范围查询
2.更新不给力(比如:2317我要做一个update,将2317改成7555,这时候的7555就不应该在3后面的哈希桶了,所以当我 更新的时候,就得将这个2317拿下来,然后重新构建这个哈希表)
哈希表一般用在内存型的数据库里,在关系型的数据库里一般都不用了
检索时:在哈希桶后面的链表挨个查询就行
现出现一种情况:select *from empno where empno>7000;
这时候数据库就需要在大于7000的所有的表进行遍历。此时哈希表索引就用不了了。
哈希表这样结构只适用于只有等值查询的场景,比如Memcached及其他一些NoSQL引擎。
常见的索引模型:有序数组(范围查找最给力)
**坏处:**插入和更新的时候就头疼了
插入时:当插入2000的时候,后面的都要往后移。
更新时:当7219更新为2111时,就要把7219拿下来然后往前放。
适合静态存储引擎(历史表):比如移动联通的数据仓库,数据仓库里放着大家的通话记录,只存在在数据的末尾进行插入。交易表就不合适了。

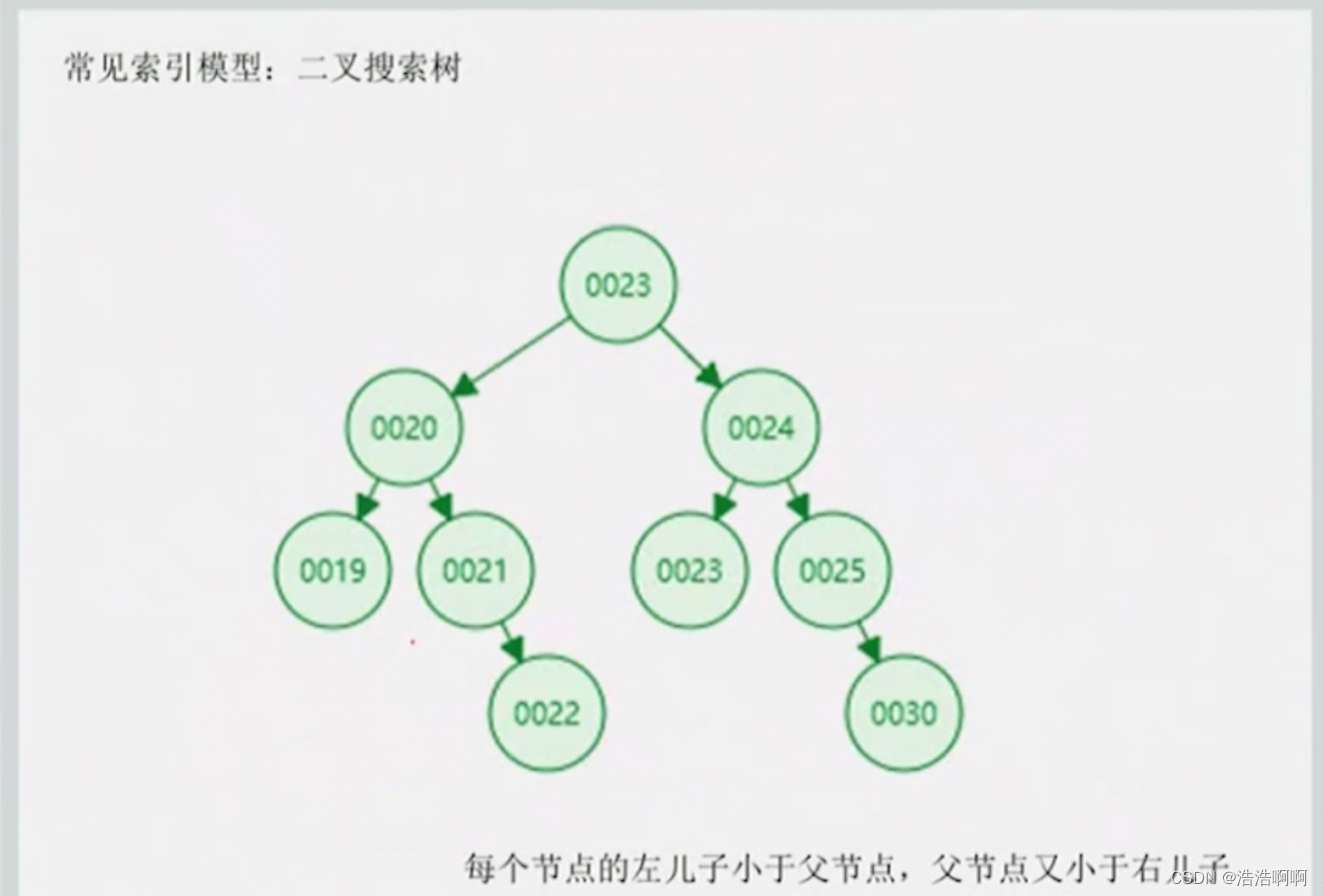
常见索引模型:二叉搜索树
根和分支都存储的是索引值,都是起导向作用,是起到能够迅速的定位到叶子的作用。
(比如找22这个值:如果我们用的是MyISAM(非聚簇)存储引擎,那么这个22除了存储值,还存储指针;如果是Innodb引擎,如果22是个主键,那么存储的就是数据,如果是个二级索引或者辅助索引,那么存储的就是主键索引)
为什么根和分支不存数据: 因为根和分支起导向作用
为什么23这个根上不能存数据,为什么已经有23的根了,还要弄一个23的叶子: 尽量减少根和分支的体积,减少索引的体积(假如23上存储了数据,那么每次索引的时候都得从根节点进入,那么每次也都得读取根节点的数据)
**为什么没有一款数据库用二叉树做搜索:**因为二叉树只有左右两个分支,当数据多的时候,那么树高就会变的很深。
用索引来检索数据的时候,索引的效率和什么有关:
1.和根的体积有关
2.树的高度(假如我想找30,读取一次根,一次IO,根和分支中间是指针的状态,根中间的数据有可能不是挨着的,有可能在不同的数据页上,23–>24一次IO,24–>25一次IO,25–>30一次IO,那么合起来就是找一行数据就需要4次IO操作,那如果这个树越高,那么我需要的IO就越多)

常见索引模型:N叉搜索树(B+树)
相当于将二叉索引进行了压缩,以前我的每个分支节点只能挂两个,现在我的每个分支节点我都可以挂无穷多个(和我的数据页有关,读数据库,我读的最小单位就是一个数据页,一个数据页就是16K,那么就看这个16K能放多少个索引值,如果能放的索引值越多,假如都是整数,比如7,16,一下能放100个,那么ok,那么下面就可以有100个分支。所以这就是为什么我的根节点不能存数据,这样才能放更多的索引值,当我的索引值越多,那么我的索引层数就越少)

**好处1:**如上图,如果树高为4,那么我索引取一行,就需要4次IO,树高是多少,那么我就需要多少次IO,那么我就可以评估出索引效率。
**好处2:**当树高非常矮时,一次读一个跟节点,那么我怎么读数据。当一次索引结束,当我树高越矮,那么我块
每一个索引在InnoDB里面对应一颗B+树

索引模型和我的表对上了:
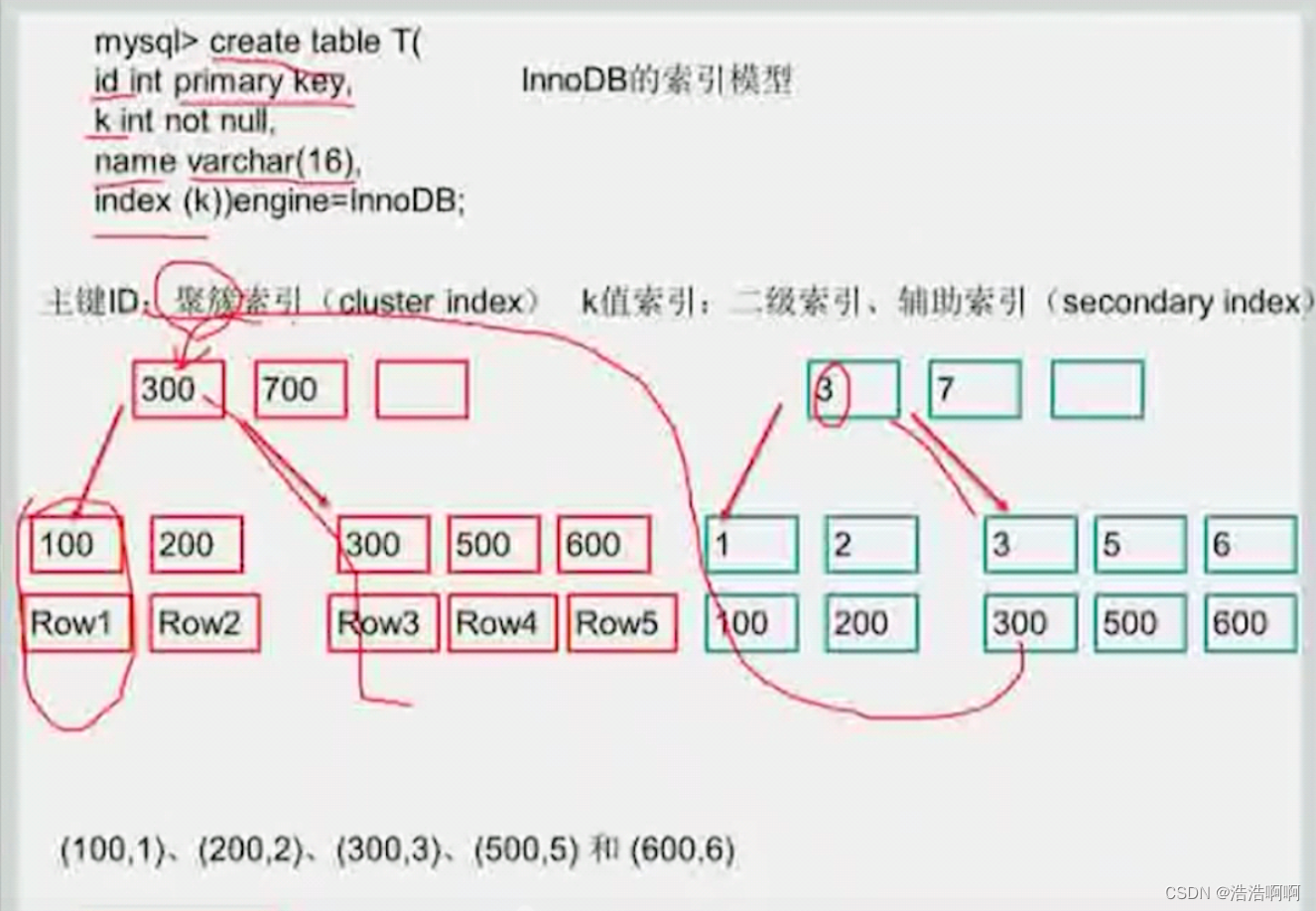
具体操作:
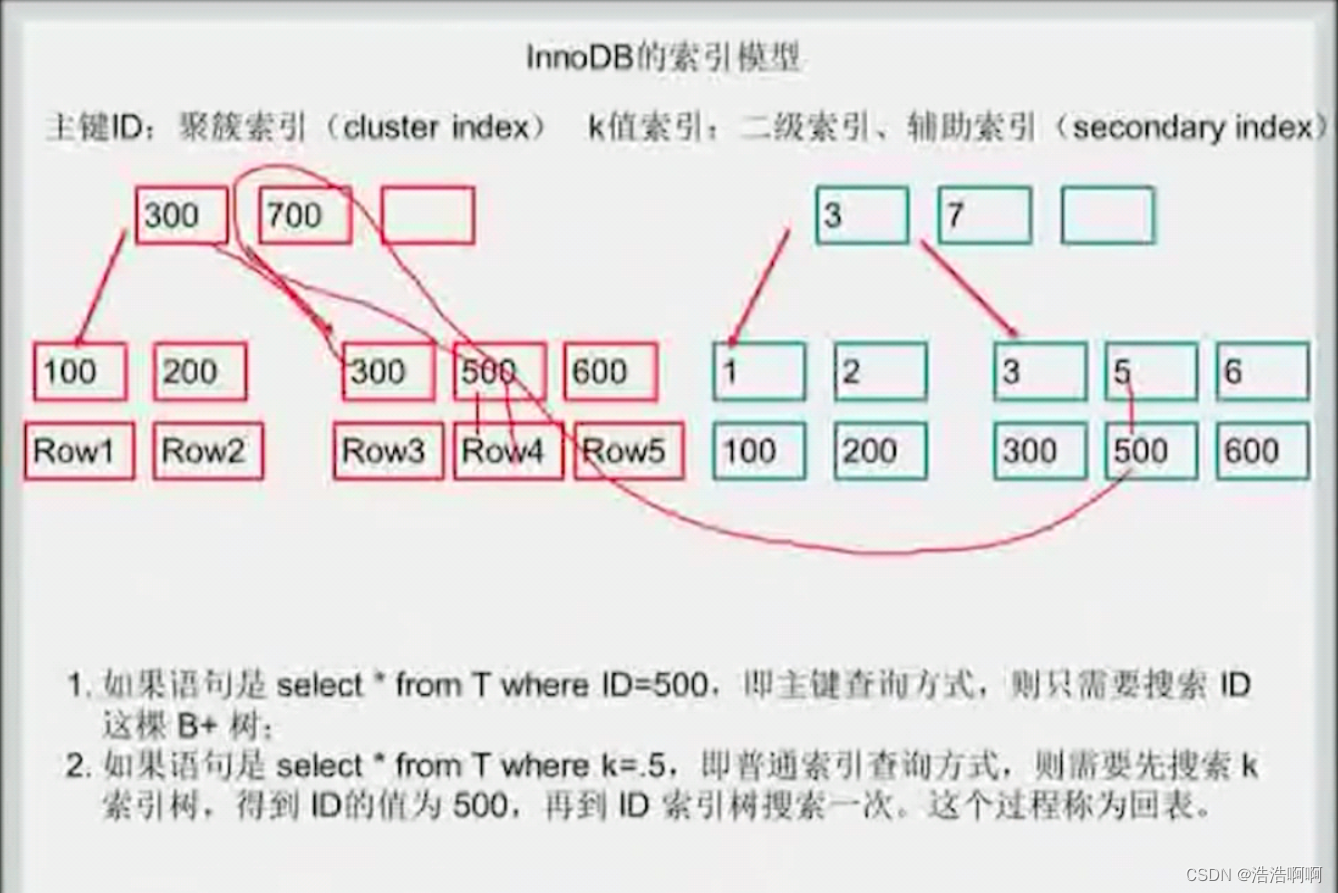
索引插入:
每一列之间都有一个双向指针的链表
在调优的过程中,尽量还是在末尾进行插入,不要在中间插入,即使中间是指针,只要修改指针即可,但中间插入的操作也远比末尾插入更耗CPU。
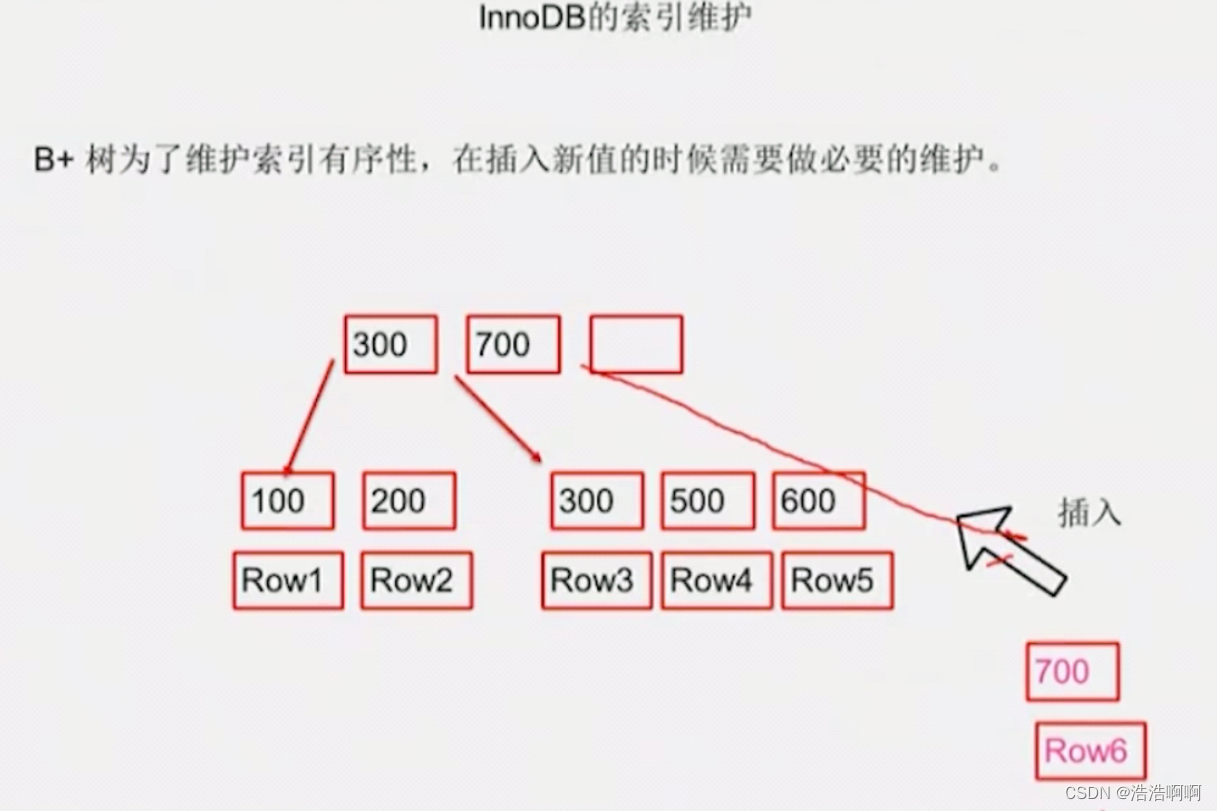

页分裂:当数据页满的时候,此时还要插入400,那么600就需要被移出去了,这时候就会产生磁盘IO,这就是页分裂(微观上,不好控制,但不经常发生)
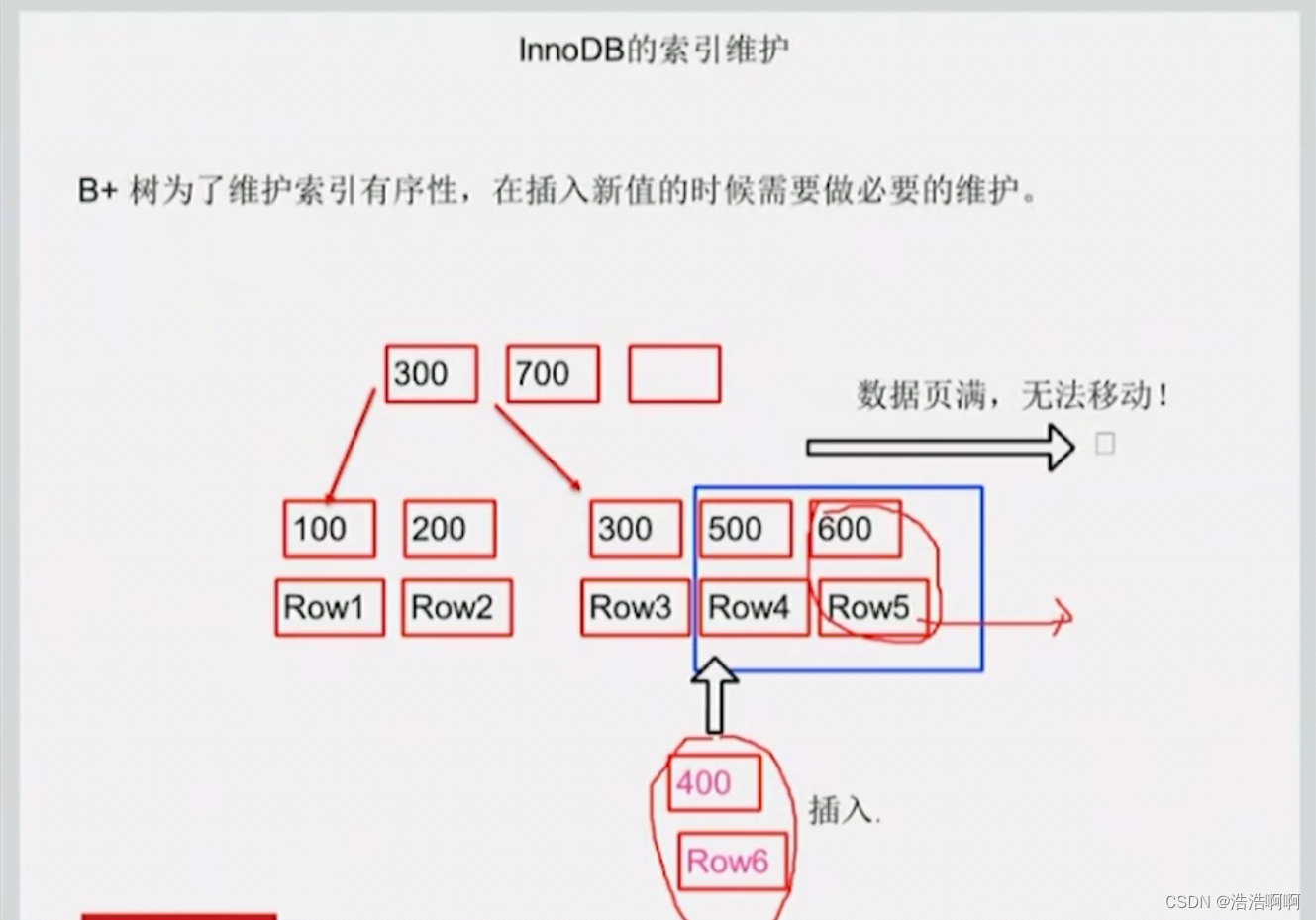
**某些公司有些规范:
**

正常我们建表

阿里等部门要求加一个无关业务的自增主键

这样,每次我要插入的值都会插到索引的最后,因为我的id列每次都会生成一个最大的值,,都是插入到最后。
**此规范的目的:**为的是每次插入都直接挂在最后面,这样就不会改变已经有的树的结构。


问题:


Mysql里的Innodb实际流程:
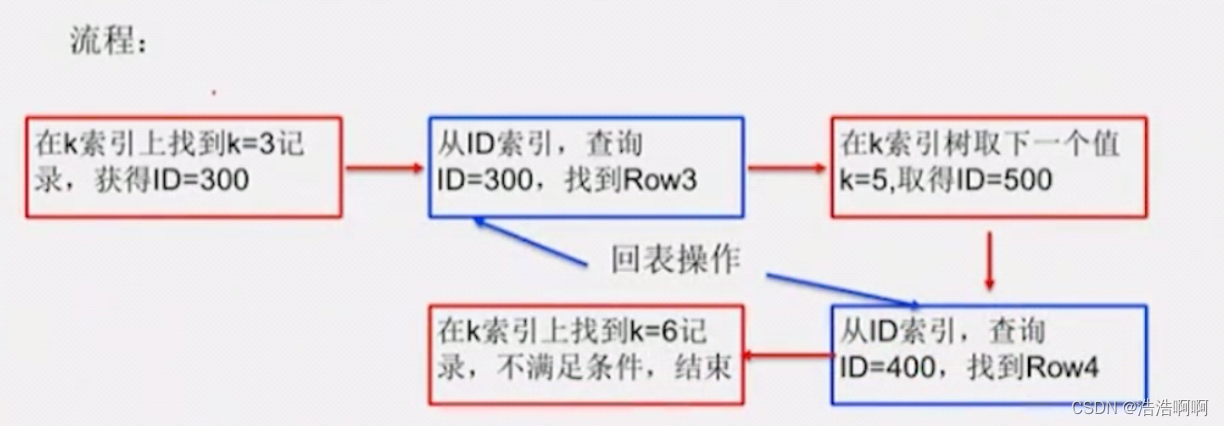 先找到3,然后顺着找到了300,大家都是这样的,但后面该找5了,这时候就会出现了分歧。
先找到3,然后顺着找到了300,大家都是这样的,但后面该找5了,这时候就会出现了分歧。
**ORACLE派说法 : **叶子结点中都有一个指针,我找>3的,那我只要顺着3往后找不就都>3了嘛,到了5了,满足条件,到了6,发现不满足条件,那结束了
存储引擎派说法 : 没用到来年表指针,先取第一值,3是满足的,找第二个值的时候,继续回到3根结点,再找下一个5,满足条件,从IO的角度看,找一个值要用2次IO,现在已经4次IO了,我现在已经找到了5,还没完,5后面可能还是5,所以我得继续找一下,回到3出发,到了6,发现不满足,那么后面都不满足了,一共耗了6次IO。
这么一看,当然第一种方法很好,但Innodb用了第二种方法,有的一些书上(Innodb存储引擎),也写了它会利用叶子之间得存储引擎,但看下源码就可以发现,实际上Innodb没有使用
**原因:**是Mysql本身的多存储引擎的设计造成的
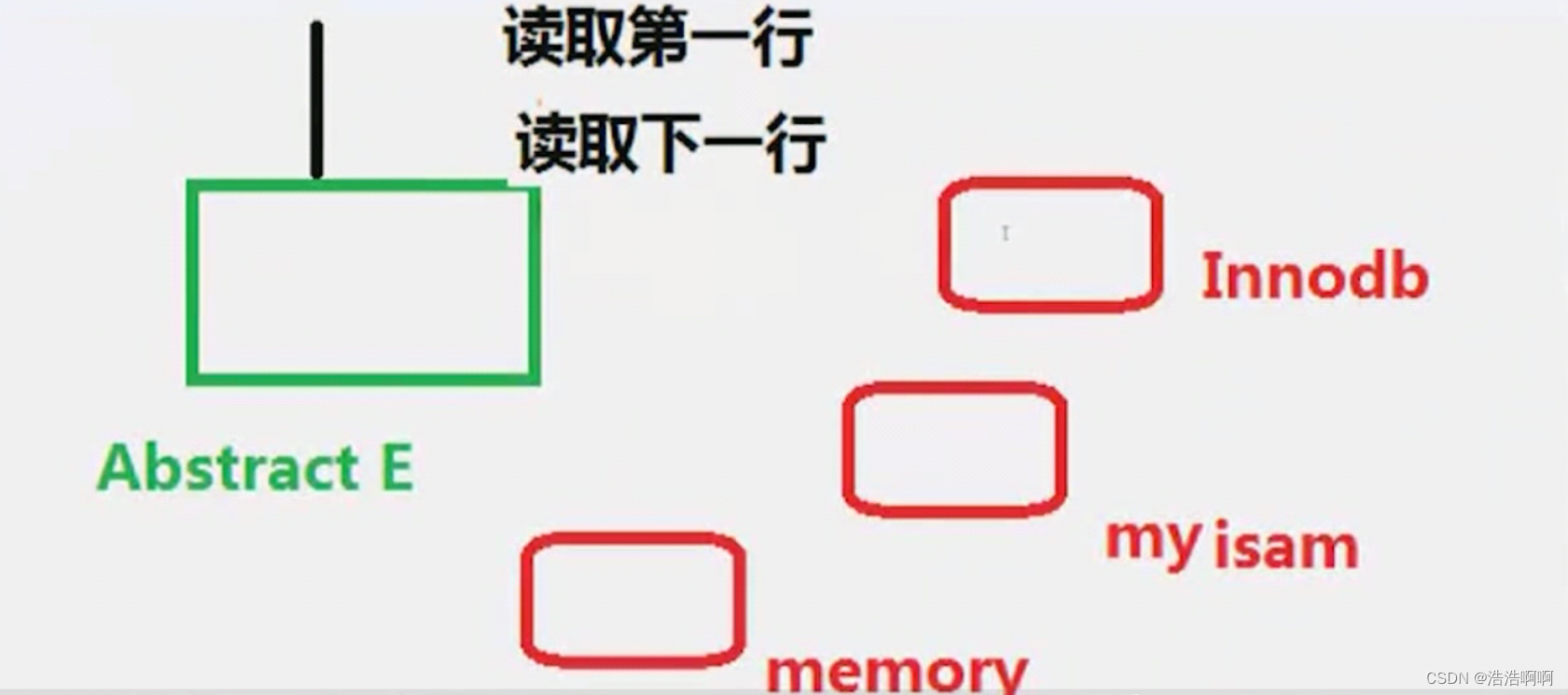
Mysql一上来是一个抽象存储引擎Abstract E,然后后面包括了众多存储引擎,有Innodb,Myisam,memory等,但你搜索3-5,这些数据只能在Innodb或者myisam里面吧,因为memory里面都没有索引。好比Java里面的抽象类是所有子类所共通的方法,共通的方法是select,update,我的抽象存储引擎有一个select接口,我的Innodb也实现一个select接口,实际上没那么简单。
实际上:
1.没有索引的情况:抽象存储引擎实现了 (它实现的,那么下面其他所有的存储引擎都可以照着办)全表扫描的接口,读取第一行、读取下一行,它实现的是这种更细粒度接口,而不是实现了select接口
2.有索引的情况:读取满足条件的第一行 这时候就可以回答上面的答案了,Innocentdb里面有链表,但不是所有引擎里面都有链表吧,所以我为了支持共通性,所以我的下一个接口是读取满足条件的下一行,这就是为什么Innodb要使用这种笨办法,就是为了支持共通性。
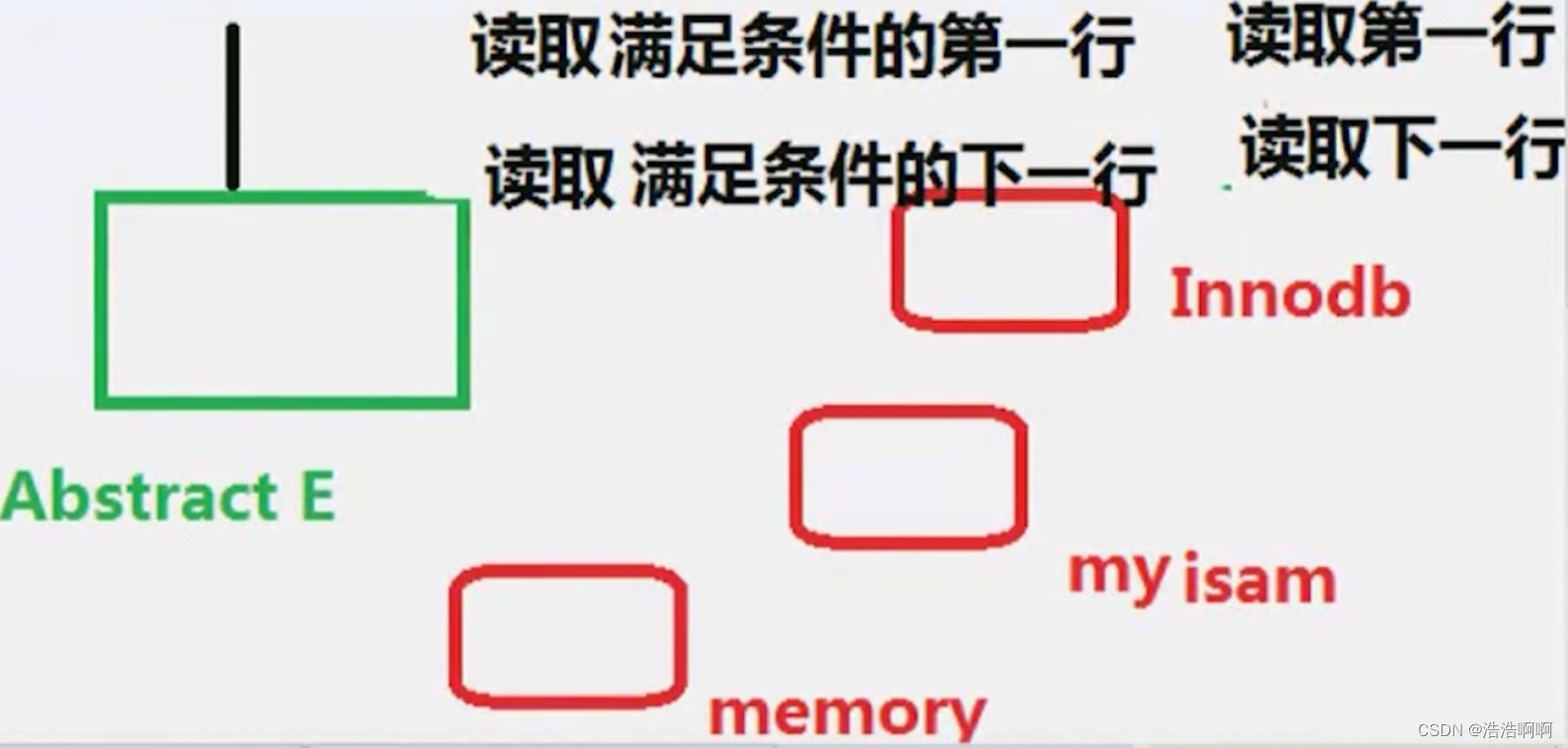
随着时代的发展,越来越多的在用MySQL的时候,只用Innodb,所以现在Mysql正朝着抛弃多存储引擎的方向发展(只用Innodb)Mysql8.0已经就朝着这方向发展了但 这种索引读还没有被舍弃
优化:覆盖索引
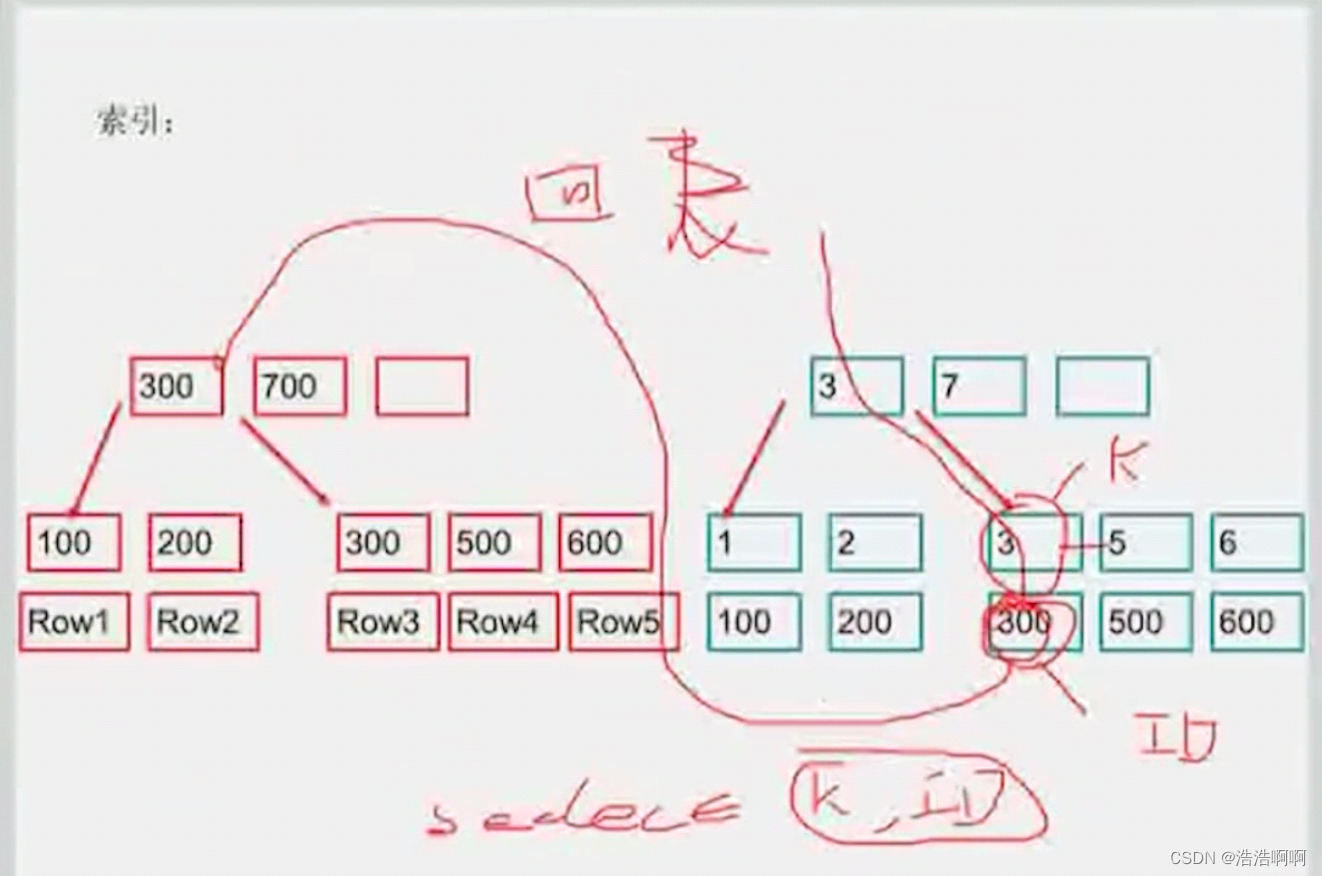
回表:每次都回到主键再开始。
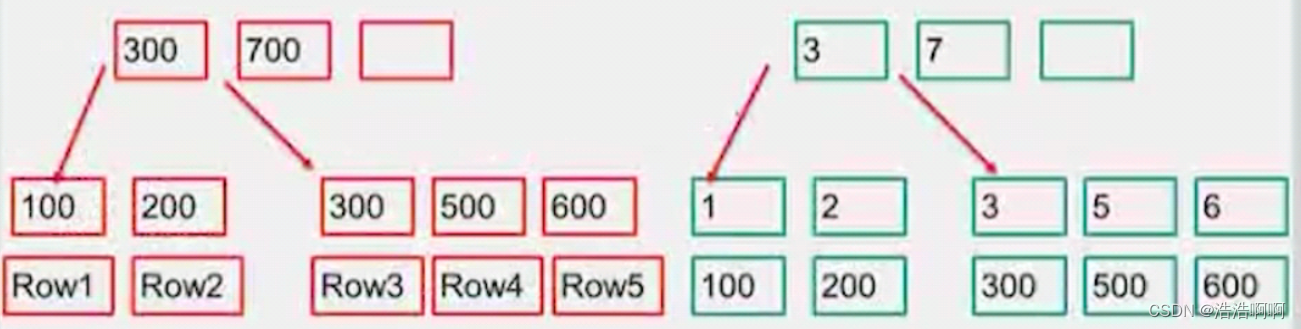
3是K值,300是ID值
这时候如果sql语句这样写:select K_ID from emp where…,这时候只要返回K和ID值,那么这时候需要回表嘛,不需要啊, 我的二级索引已经都包含了,直接在辅助索引找就完事了,都不用顺着去主键索引找
覆盖索引下的联合索引: Key’name_age’(‘name’,‘age’)
本来是:Tom,20 Tom,15 Jack,22 ,一开始会默认前两个一样,但当用了来联合索引,这时候就变成了Tom20,Tom15,Jack22,这样前两个就不一样了。

因为叶子结点存储了主键,那么(‘name’,‘age’)这个叶子里面也就储存了id这个主键,那么最后一条语句其实也就隐藏了id这一重要的点,这时候只要想找id、name、age当中的随便哪两个,都不用再设置了,也就都不用再进行回表操作了。
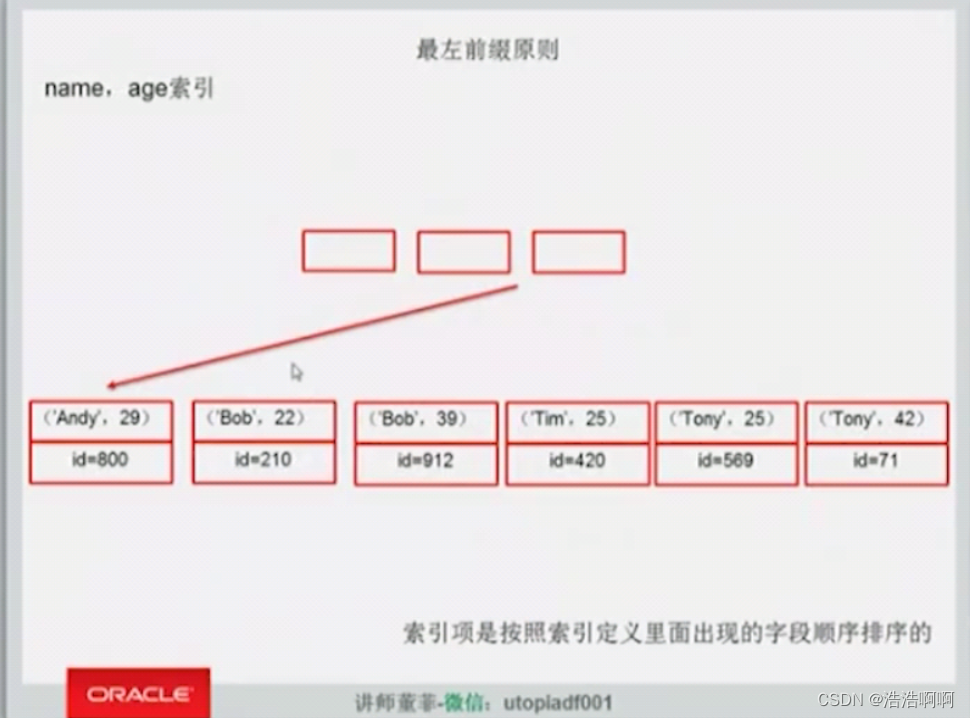
最左前缀原则:
下面的 where age=35; where name like ‘%o’;都没办法走索引,相当于全表扫描了。
在这里面,只要name先出现,我的age才可以走索引,这是Mysql里的极为重要的一个原则。
















 1422
1422











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









