GoogLeNet代码解读
概述
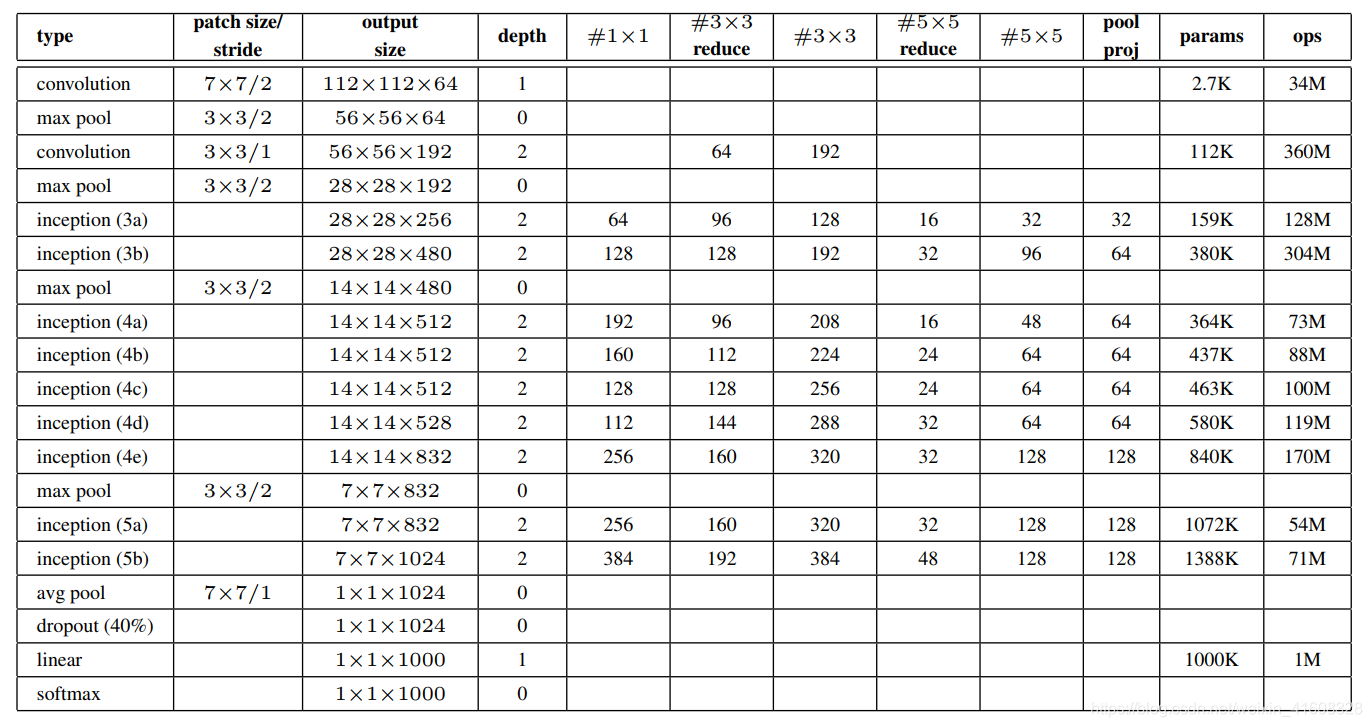
GooLeNet网络结构图
1)从输入到第一层inception
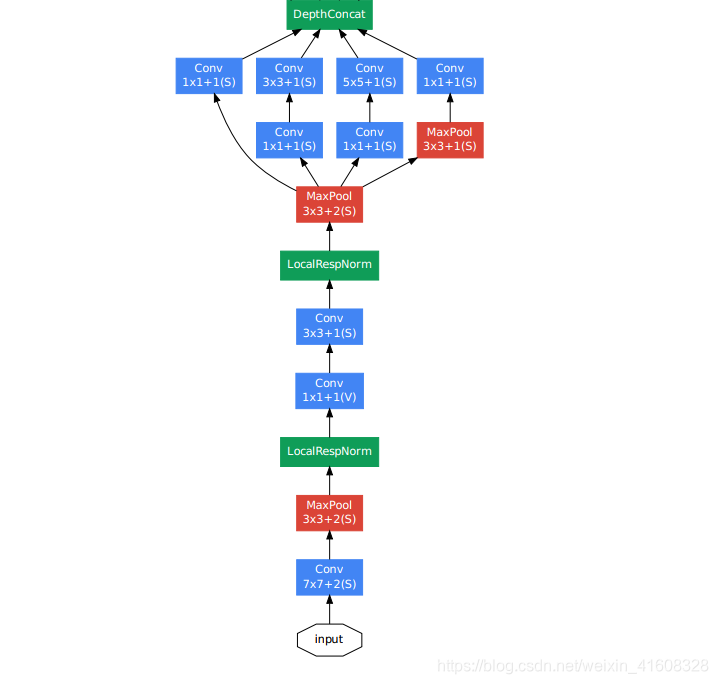
2)从第2层inception到第4层inception
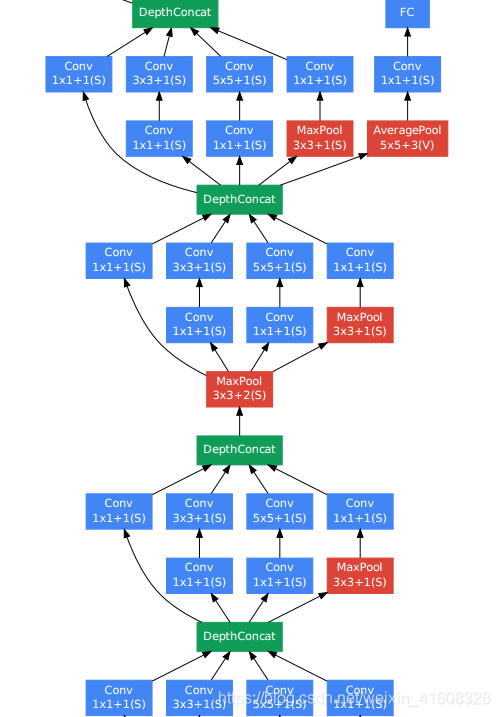
3)从第5层inception到第7层inception
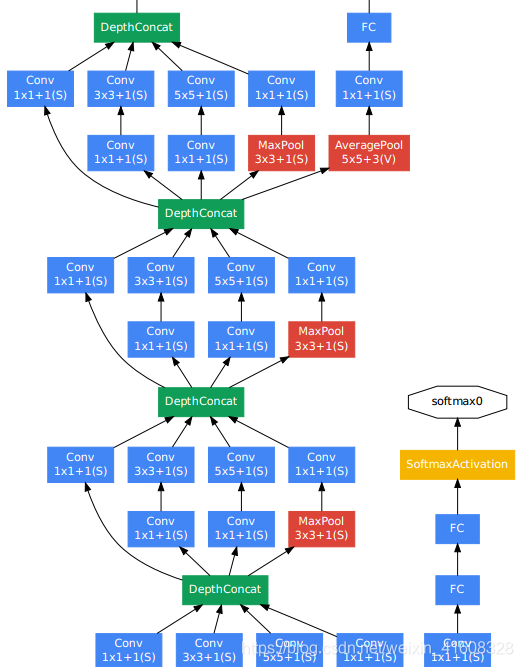
4)从第8层inception到输出
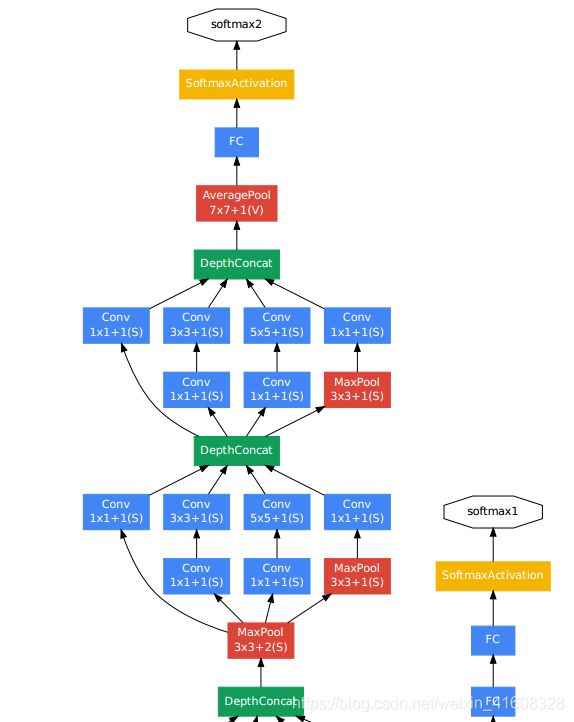
GooLeNet架构搭建
代码细节分析
from collections import namedtuple
import warnings
import torch
from torch import nn, Tensor
import torch.nn.functional as F
from .utils import load_state_dict_from_url
from typing import Callable, Any, Optional, Tuple, List
# 可供下载的googlenet预训练模型名称
__all__ = ['GoogLeNet','googlenet','GoogLeNetOutputs','_GoogLeNetOutputs']
# 预训练权重下载
model_urls = {'googlenet':'https://download.pytorch.org/models/googlenet-1378be20.pth',}
GoogLeNetOutputs = namedtuple('GoogLeNetOutputs',['logits','aux_logits2','aux_logits1'])
GoogLeNetOutputs.__annotations__ = {'logits': Tensor, 'aux_logits2': Optional[Tensor],
'aux_logits1': Optional[Tensor]}
_GoogLeNetOutputs = GoogLeNetOutputs
def googlenet(pretrained = False, progress = True, **kwargs):
if pretrained:
if 'transform_input' not in kwargs:
kwargs['transform_input'] = True
if 'aux_logits' not in kwargs:
kwargs['aux_logits'] = False
if kwargs['aux_logits']:
warnings.warn('auxiliary heads in the pretrained googlenet model are NOT pretrained, '
'so make sure to train them')
orginal_aux_logits = kwargs['aux_logits']
kwargs['aux_logits'] = True
kwargs['init_weights'] = False
model = GoogLeNet(**kwargs)
# 下载googlenet模型并加载
state_dict = load_state_dict_from_url(model_urls['googlenet'],progress = progress)
model.load_state_dict(state_dict)
if not original_aux_logits:
model.aux_logits = False
model.aux1 = None
model.aux2 = None
return model
return GoogLeNet(**kwargs)
class GoogLeNet(nn.Module):
__constants__ = ['aux_logits','transform_input']
def __init__(self,
num_classes = 1000,
aux_logits = True,
trandform_input = False,
init_weights = None,
blocks = None):
super(GoogLeNet,self).__init__()
if blocks is None:
blocks = [BasicConv2d, Inception, InceptionAux]
if init_weights is None:
warnings.warn('The default weight initialization of GoogleNet will be changed in future releases of '
'torchvision. If you wish to keep the old behavior (which leads to long initialization times'
' due to scipy/scipy#11299), please set init_weights=True.', FutureWarning)
init_weights = True
assert len(blocks)==3
conv_block = blocks[0]
inception_block = blocks[1]
inception_aux_block = blocks[2]
self.aux_logits = aux_logits
self.transform_input = transform_input
# 从输入到第一层inception的卷积、池化处理
self.conv1 = conv_block(3,64,kernel_size = 7, stride = 3, padding = 3)
self.maxpool1 = nn.MaxPool2d(3,stride = 2, ceil_mode = True)
self.conv2 = conv_block(64,64,kernel_size = 1)
self.conv3 = conv_block(64,192,kernel_size = 3, padding = 1)
self.maxpool2 = nn.MaxPool2d(3,stride = 2, ceil_mode = True)
# 一系列的inception模块
self.inception3a = inception_block(192,64,96,128,16,32,32)
self.inception3b = inception_block(256, 128, 128, 192, 32, 96, 64)
self.maxpool3 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.inception4a = inception_block(480, 192, 96, 208, 16, 48, 64)
self.inception4b = inception_block(512, 160, 112, 224, 24, 64, 64)
self.inception4c = inception_block(512, 128, 128, 256, 24, 64, 64)
self.inception4d = inception_block(512, 112, 144, 288, 32, 64, 64)
self.inception4e = inception_block(528, 256, 160, 320, 32, 128, 128)
self.maxpool4 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
self.inception5a = inception_block(832, 256, 160, 320, 32, 128, 128)
self.inception5b = inception_block(832, 384, 192, 384, 48, 128, 128)
# 辅助分类模块
if aux_logits:
self.aux1 = inception_aux_block(512, num_classes)
self.aux2 = inception_aux_block(528, num_classes)
else:
self.aux1 = None # type: ignore[assignment]
self.aux2 = None # type: ignore[assignment]
# 平均池化、dropout防止过拟合
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.dropout = nn.Dropout(0.2)
self.fc = nn.Linear(1024, num_classes)
if init_weights:
self._initialize_weights()
def _initialize_weights(self) -> None:
# 初始化权重和偏置参数
for m in self.modules():
if isinstance(m, nn.Conv2d) or isinstance(m, nn.Linear):
import scipy.stats as stats
X = stats.truncnorm(-2, 2, scale=0.01)
values = torch.as_tensor(X.rvs(m.weight.numel()), dtype=m.weight.dtype)
values = values.view(m.weight.size())
with torch.no_grad():
m.weight.copy_(values)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
# 给input增加一个维度并作中心化
def _transform_input(self, x: Tensor) -> Tensor:
if self.transform_input:
x_ch0 = torch.unsqueeze(x[:, 0], 1) * (0.229 / 0.5) + (0.485 - 0.5) / 0.5
x_ch1 = torch.unsqueeze(x[:, 1], 1) * (0.224 / 0.5) + (0.456 - 0.5) / 0.5
x_ch2 = torch.unsqueeze(x[:, 2], 1) * (0.225 / 0.5) + (0.406 - 0.5) / 0.5
x = torch.cat((x_ch0, x_ch1, x_ch2), 1)
return x
# 构建googlenet网络
def _forward(self, x: Tensor) -> Tuple[Tensor, Optional[Tensor], Optional[Tensor]]:
# N x 3 x 224 x 224
x = self.conv1(x)
# N x 64 x 112 x 112
x = self.maxpool1(x)
# N x 64 x 56 x 56
x = self.conv2(x)
# N x 64 x 56 x 56
x = self.conv3(x)
# N x 192 x 56 x 56
x = self.maxpool2(x)
# N x 192 x 28 x 28
x = self.inception3a(x)
# N x 256 x 28 x 28
x = self.inception3b(x)
# N x 480 x 28 x 28
x = self.maxpool3(x)
# N x 480 x 14 x 14
x = self.inception4a(x)
# N x 512 x 14 x 14
aux1: Optional[Tensor] = None
if self.aux1 is not None:
if self.training:
aux1 = self.aux1(x)
x = self.inception4b(x)
# N x 512 x 14 x 14
x = self.inception4c(x)
# N x 512 x 14 x 14
x = self.inception4d(x)
# N x 528 x 14 x 14
aux2: Optional[Tensor] = None
if self.aux2 is not None:
if self.training:
aux2 = self.aux2(x)
x = self.inception4e(x)
# N x 832 x 14 x 14
x = self.maxpool4(x)
# N x 832 x 7 x 7
x = self.inception5a(x)
# N x 832 x 7 x 7
x = self.inception5b(x)
# N x 1024 x 7 x 7
x = self.avgpool(x)
# N x 1024 x 1 x 1
x = torch.flatten(x, 1)
# N x 1024
x = self.dropout(x)
x = self.fc(x)
# N x 1000 (num_classes)
return x, aux2, aux1
@torch.jit.unused
def eager_outputs(self, x: Tensor, aux2: Tensor, aux1: Optional[Tensor]) -> GoogLeNetOutputs:
if self.training and self.aux_logits:
return _GoogLeNetOutputs(x, aux2, aux1)
else:
return x # type: ignore[return-value]
def forward(self, x: Tensor) -> GoogLeNetOutputs:
x = self._transform_input(x)
x, aux1, aux2 = self._forward(x)
aux_defined = self.training and self.aux_logits
if torch.jit.is_scripting():
if not aux_defined:
warnings.warn("Scripted GoogleNet always returns GoogleNetOutputs Tuple")
return GoogLeNetOutputs(x, aux2, aux1)
else:
return self.eager_outputs(x, aux2, aux1)
# inception模块
class Inception(nn.Module):
def __init__(
self,
in_channels: int,
ch1x1: int,
ch3x3red: int,
ch3x3: int,
ch5x5red: int,
ch5x5: int,
pool_proj: int,
conv_block: Optional[Callable[..., nn.Module]] = None
) -> None:
super(Inception, self).__init__()
if conv_block is None:
conv_block = BasicConv2d
self.branch1 = conv_block(in_channels, ch1x1, kernel_size=1)
self.branch2 = nn.Sequential(
conv_block(in_channels, ch3x3red, kernel_size=1),
conv_block(ch3x3red, ch3x3, kernel_size=3, padding=1)
)
self.branch3 = nn.Sequential(
conv_block(in_channels, ch5x5red, kernel_size=1),
# Here, kernel_size=3 instead of kernel_size=5 is a known bug.
# Please see https://github.com/pytorch/vision/issues/906 for details.
conv_block(ch5x5red, ch5x5, kernel_size=3, padding=1)
)
self.branch4 = nn.Sequential(
nn.MaxPool2d(kernel_size=3, stride=1, padding=1, ceil_mode=True),
conv_block(in_channels, pool_proj, kernel_size=1)
)
def _forward(self, x: Tensor) -> List[Tensor]:
branch1 = self.branch1(x)
branch2 = self.branch2(x)
branch3 = self.branch3(x)
branch4 = self.branch4(x)
outputs = [branch1, branch2, branch3, branch4]
return outputs
def forward(self, x: Tensor) -> Tensor:
outputs = self._forward(x)
return torch.cat(outputs, 1)
# 辅助的inception模块,用于分类
class InceptionAux(nn.Module):
def __init__(
self,
in_channels: int,
num_classes: int,
conv_block: Optional[Callable[..., nn.Module]] = None
) -> None:
super(InceptionAux, self).__init__()
if conv_block is None:
conv_block = BasicConv2d
self.conv = conv_block(in_channels, 128, kernel_size=1)
self.fc1 = nn.Linear(2048, 1024)
self.fc2 = nn.Linear(1024, num_classes)
def forward(self, x: Tensor) -> Tensor:
# aux1: N x 512 x 14 x 14, aux2: N x 528 x 14 x 14
x = F.adaptive_avg_pool2d(x, (4, 4))
# aux1: N x 512 x 4 x 4, aux2: N x 528 x 4 x 4
x = self.conv(x)
# N x 128 x 4 x 4
x = torch.flatten(x, 1)
# N x 2048
x = F.relu(self.fc1(x), inplace=True)
# N x 1024
x = F.dropout(x, 0.7, training=self.training)
# N x 1024
x = self.fc2(x)
# N x 1000 (num_classes)
return x
# 将卷积、bn、激活封装成一个函数,其实这里不封装也行,分成3步来写
class BasicConv2d(nn.Module):
def __init__(
self,
in_channels: int,
out_channels: int,
**kwargs: Any
) -> None:
super(BasicConv2d, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, bias=False, **kwargs)
self.bn = nn.BatchNorm2d(out_channels, eps=0.001)
def forward(self, x: Tensor) -> Tensor:
x = self.conv(x)
x = self.bn(x)
return F.relu(x, inplace=True)























 497
497











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









