







正则化
深度学习在训练的时候会出现一些误差,而这个误差的概率必须要在我们所能接受的范围内,不能欠拟合也不能过拟合,所以在误差较大时我们出现了偏差和方差的概念。
通过训练误差和验证集误差判断算法偏差或方差是否偏高。
高偏差:算法并没有在训练集中得到很好训练,如果训练数据的拟合度不高,就是数据欠拟合,就可以说这种算法偏差比较高
高方差:训练集设置得非常好,而验证集设置相对较差,我们可能过度拟合了训练集,在某种程度上,验证集并没有充分利用交叉验证集的作用,像这种情况,我们称之为“高方差”。
正则化就是用来解决高方差问题,避免过拟合。
L1,L2正则化
范数:范数是衡量某个向量空间(或矩阵)中的每个向量以长度或大小。范数的一般化定义:对实数p>=1, 范数定义如下:
- L1范数
当p=1时,是L1范数,其表示某个向量中所有元素绝对值的和。 - L2范数(暂时写为这个名字)
当p=2时,是L2范数, 表示某个向量中所有元素平方和再开根, 也就是欧几里得距离公式
之前我们学习到的机器学习的代价函数是:
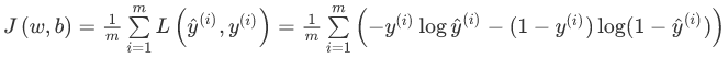
在目标函数后面添加一个系数的“惩罚项”是正则化的常用方式,为了防止系数过大从而让模型变得复杂。在加了正则化项之后的目标函数为:
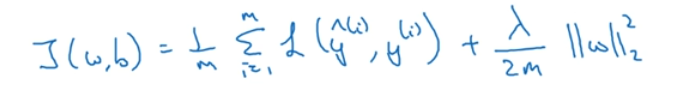
在L2正则化中,加入的是欧几里得距离,也就是w的平方,但这不叫L2范数,叫弗罗贝尼乌斯范数;而在L1中就是将平方去掉,只加元素的绝对值的和。
L1的w矩阵会比较稀疏,它的优良性质是能产生稀疏性,导致 W 中许多项变成零。 稀疏的解除了计算量上的好处之外,更重要的是更具有“可解释性”。
L2有时候也被称为“权重衰减”,因为在反向传播计算中,权值w每一次更新都减去了α(λ/m)*w,都在使权值慢慢减小。
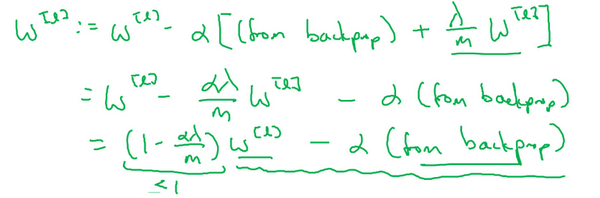
公式中的lamda是正则化参数,我们通常使用验证集或交叉验证集来配置这个参数,尝试各种各样的数据,寻找最好的参数,我们要考虑训练集之间的权衡,把参数设置为较小值,这样可以避免过拟合,所以λ是另外一个需要调整的超级参数,
我们添加正则项,它可以避免数据权值矩阵过大,这就是弗罗贝尼乌斯范数,为什么压缩弗罗贝尼乌斯范数或者参数可以减少过拟合?直观上理解就是如果正则化λ设置得足够大,权重矩阵W被设置为接近于0的值,就是把多隐藏单元的权重设为0,于是基本上消除了这些隐藏单元的许多影响。如果是这种情况,这个被大大简化了的神经网络会变成一个很小的网络,小到如同一个逻辑回归单元,可是深度却很大,它会使这个网络从过度拟合的状态更接近欠拟合的高偏差状态。

在tanh的激活函数中,如果w很小,那么我们就可以把l层的输入值控制在红色部分,就不会出现由于z过大或过小造成训练结果趋近于直线,保证学习效率一直是线性。
Dropout正则化
什么是Dropout?
在2012年,Hinton在其论文《Improving neural networks by preventing co-adaptation of feature detectors》中提出Dropout。当一个复杂的前馈神经网络被训练在小的数据集时,容易造成过拟合。是为了防止过拟合,通过阻止特征检测器的共同作用来提高神经网络的性能。
它是一种正则化的方式,是改变神经网络本身来实现的,是训练数据时的一种技巧。

Dropout在每个训练批次中,通过忽略一部分的特征检测器(让一部分的隐层节点值为0),可以明显地减少过拟合现象。这种方式可以减少特征检测器(隐层节点)间的相互作用(指某些检测器依赖其他检测器才能发挥作用)。
Dropout说的简单一点就是:我们在前向传播的时候,让某个神经元的激活值以一定的概率p停止工作,这样可以使模型泛化性更强,因为它不会太依赖某些局部的特征。


Dropout的实现方法-inverted dropout(反向随机失活)
用一个三层l=3网络来举例说明:
首先要定义向量d3,表示一个三层的dropout向量
keep_prob=0.8
d3 = np.random.rand(a3.shape[0],a3.shape[1])<keep_prob

接下来要做的就是从第三层中获取激活函数,这里我们叫它a3,a3含有要计算的激活函数,a3等于上面的a3乘以d3,
a3 =np.multiply(a3,d3)
乘法运算最终把d3中相应元素输出,即让d3中0元素与a0中相对元素归零。
a3/=keep_prob
反向随机失活(inverted dropout)方法通过除以keep_prob,确保a3的期望值不变。
我们假设第三隐藏层上有50个单元或50个神经元,在一维上a3是50,因式分解为50*m维的矩阵,则dropout后得到![]()
为了不影响它的原始期望值,我们把为1的0.8概率的部分除以0.8即可。
直观上理解:dropout不要依赖于任何一个特征,因为该单元的输入可能随时被清除,因此该单元通过这种方式传播下去,并为单元的四个输入增加一点权重,通过传播所有权重,dropout将产生收缩权重的平方范数的效果,和之前讲的L2正则化类似;实施dropout的结果是它会压缩权重,并完成一些预防过拟合的外层正则化;L2对不同权重的衰减是不同的,它取决于激活函数倍增的大小。

不能依靠任何特征,因为特征都有可能被随机清除,或者说该单元的输入也都可能被随机清除。我不愿意把所有赌注都放在一个节点上,不愿意给任何一个输入加上太多权重,因为它可能会被删除,因此该单元将通过这种方式积极地传播开,并为单元的四个输入增加一点权重,通过传播所有权重,dropout将产生收缩权重的平方范数的效果。

dropout一大缺点就是代价函数不再被明确定义,每次迭代,都会随机移除一些节点,如果再三检查梯度下降的性能,实际上是很难进行复查的。定义明确的代价函数每次迭代后都会下降,因为我们所优化的代价函数实际上并没有明确定义,或者说在某种程度上很难计算,所以我们失去了调试工具来绘制这样的图片。
总结一下,如果你担心某些层比其它层更容易发生过拟合,可以把某些层的keep-prob值设置得比其它层更低,缺点是为了使用交叉验证,你要搜索更多的超级参数,另一种方案是在一些层上应用dropout,而有些层不用dropout,应用dropout的层只含有一个超级参数,就是keep-prob。
我通常会关闭dropout函数,将keep-prob的值设为1,运行代码,确保J函数单调递减。然后打开dropout函数。
其他正则化方法(Other regularization methods)
数据扩增(data augmentation)

early stopping

运行梯度下降时,我们可以绘制训练误差,或只绘制代价函数的优化过程,在训练集上用0-1记录分类误差次数,呈单调下降趋势。
在训练过程中,我们希望训练误差,代价函数都在下降,通过early stopping,我们不但可以绘制上面这些内容,还可以绘制验证集误差,它可以是验证集上的分类误差,或验证集上的代价函数,逻辑损失和对数损失等,你会发现,验证集误差通常会先呈下降趋势,然后在某个节点处开始上升
正则化是为了防止过拟合,是在验证集发挥大作用的,都是为了有更好的模型。















 133
133











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









