







决策树Decision Tree
决策树的三种算法:

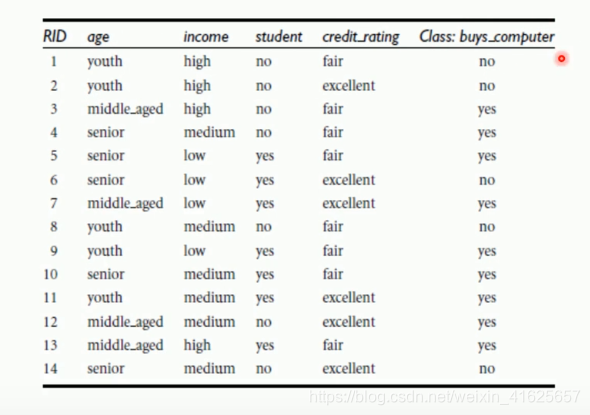
举个栗子:
熵entropy的概念:
信息熵越大,不确定性越大。信息熵越小,不确定性越小。

其实就是排列组合之中的概率,概率相乘得到其中一个组合,我们想把乘号换成加号,则加一个log,(log(ab)=loga+logb)因为连乘一般不会得到很好的结果,特别是数据非常多的时候。
 骰子计算结果:
骰子计算结果:
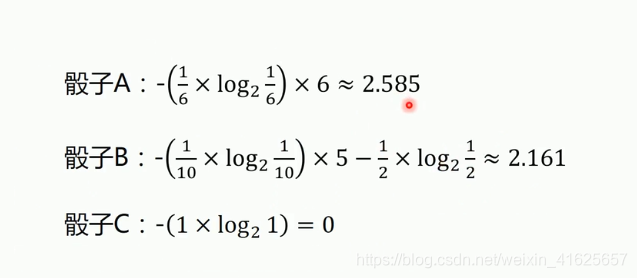
ID3算法(根据信息熵来决定):

选择根节点ID3算法:
首先以结果buys_computer来计算总的信息熵D。
然后计算年龄的信息熵,只看年龄的部分,年轻的5/14,然后查看年龄中的buys_computer,2/5是yes,3/5是no;中年的4/14,中年中买的,和不买的。再查看老年,老年中买的和不买的;他们的和即是总的信息熵。
信息增益就是D的熵减去年龄的熵。

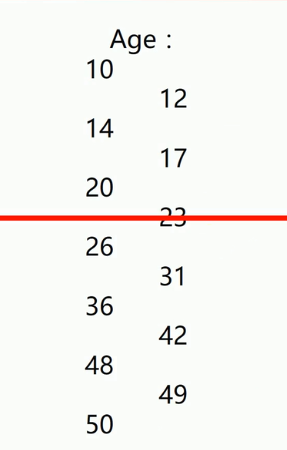
连续变量的处理:
两列数据,左边是一列,右边是一列。右边是两个数之间的平均值。
这里的每一个中间值,如果都切一刀,那么每一个值都可以计算一次信息增益。
那一个节点的信息增益计算出来越大,那么就将这个节点作为分界点,大于23为一类,小于23为一个分类。把连续型数据处理成离散数据。
C4.5算法
C4.5偏爱取值数目少的属性。
ID3算法(信息增益)会出现一个问题:
往往会选择分叉比较多的那一个作为节点。

实例:
数据文件:

注意:当制作数据时,不要直接再xls的后缀中直接修改为csv这样会导致编码错误,需要另存为csv文件。
from sklearn.feature_extraction import DictVectorizer
from sklearn import tree
from sklearn import preprocessing
import csv
#读入数据,用csv来读数据,是专门来读取该文件的,这个方式可以读取各式各样的字符。
Dtree = open(r'All.csv','r')
reader = csv.reader(Dtree)
#获取第一行数据,即为表头。
headers = reader.__next__()
#定义两个列表,保存特征和标签
featureList = []
labelList = []
for row in reader:
#把label存入List,拿到这一行的最后一个元素
labelList.append(row[-1])
rowDict = {}
#计算了行的长度,除了第一列和标签之外
for i in range(1,len(row)-1):
#建立一个数据字典,就是将表头和表头的值相互对应来形成键值对
rowDict[headers[i]] = row[i]
#把数据字典存入list
featureList.append(rowDict)
#把数据转换成01表示
#把所有属性的所有情况写出来,依次排列,0为这种属性没有,1为有
vec = DictVectorizer()
x_data = vec.fit_transform(featureList).toarray()
print("x_data:"+str(x_data))
#打印属性名称
print(vec.get_feature_names())
print("labelList:"+str(labelList))
#把标签换成01表示
lb = preprocessing.LabelBinarizer()
y_data = lb.fit_transform(labelList)
print("y_data:"+str(y_data))
#创建决策树模型,算法使用C4.5entropy
model = tree.DecisionTreeClassifier(criterion='entropy')
#输入要建立的模型
model.fit(x_data,y_data)
#测试
x_test = x_data[0]#选一个样本作为测试数据
print("x_test:"+str(x_test))
predict = model.predict(x_test.reshape(1,-1))#将x_test变成一个二维的数据
print("predict:"+str(predict))
#画图
import graphviz
dot_data = tree.export_graphviz(model,
out_file=None,
#特征的名字,要设置
feature_names = vec.get_feature_names(),
class_names=lb.classes_,
filled=True,
rounded=True,
special_characters=True)
graph = graphviz.Source(dot_data)
graph.render('computer')
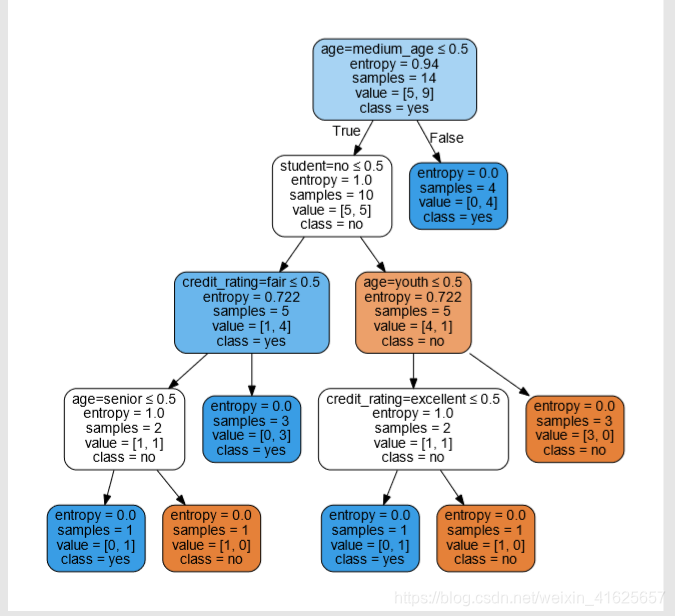
所显示的决策树。决策树一般是二叉树的样子,左边默认True,右边为False
决策树CART算法
首先确定划分节点的节点类。

举个栗子:
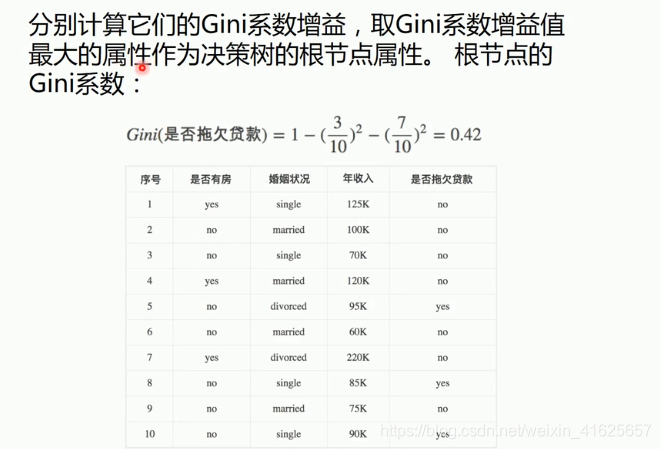 是否有房这个节点的基尼指数 =
是否有房这个节点的基尼指数 =
gini{总的是否拖欠贷款} - 是否有房中有房的概率 * gini{有房} - 是否有房子无房的概率 * gini{无房}
gini{有房} = 1- 有房中拖欠贷款概率的平方 - 有房中未拖欠贷款概率的平方
gini{无房} = 1 - 无房中拖欠贷款概率的平方 - 无房中未拖欠贷款概率的平方
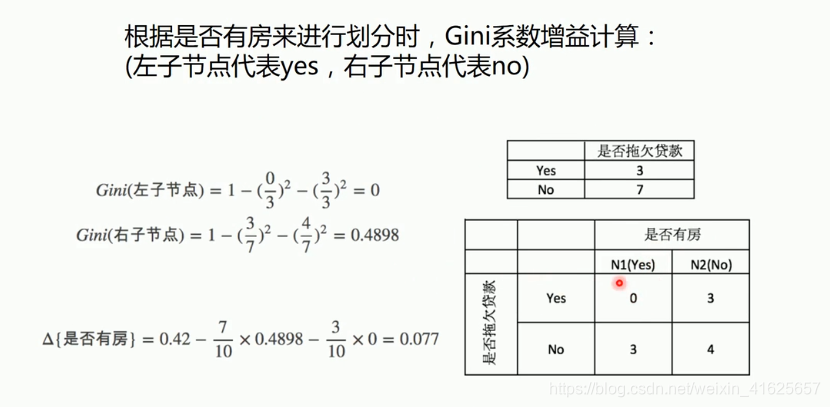
根据婚姻状况来划分,因为基尼指数只能进行二分类,所以三种情况下的话就定一类情况为主,而另外两种合并,看作一种情况;再计算定的那一类的基尼指数。分别定三种情况为三个主类,计算三次各个情况的基尼指数。

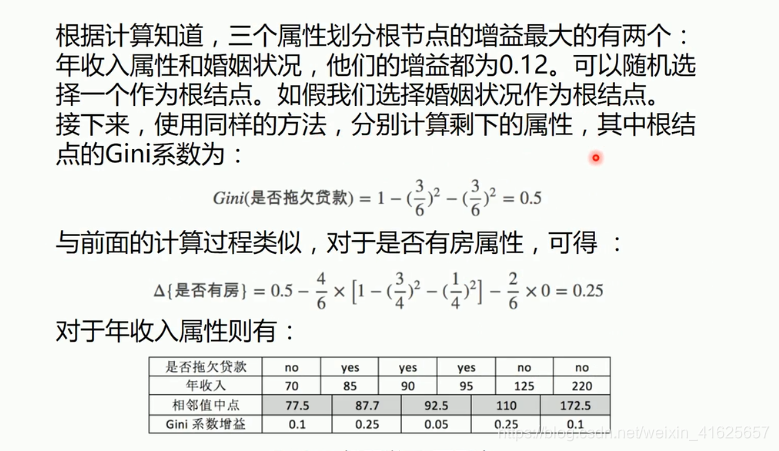
计算年收入情况。要将连续型数据化为离散型,计算每两个值之间的平均值,把每一个中点作为它的分割点来计算它的基尼指数:在65这里切一刀,大于65为一种情况,小于65为一种情况。最后找所有情况中的最大值作为分割点。

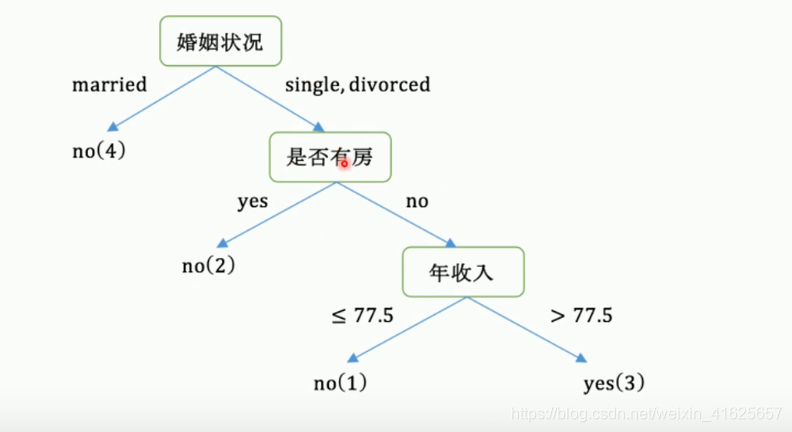
最后创建的决策树:
决策树的剪枝
为了减少决策树的复杂度。
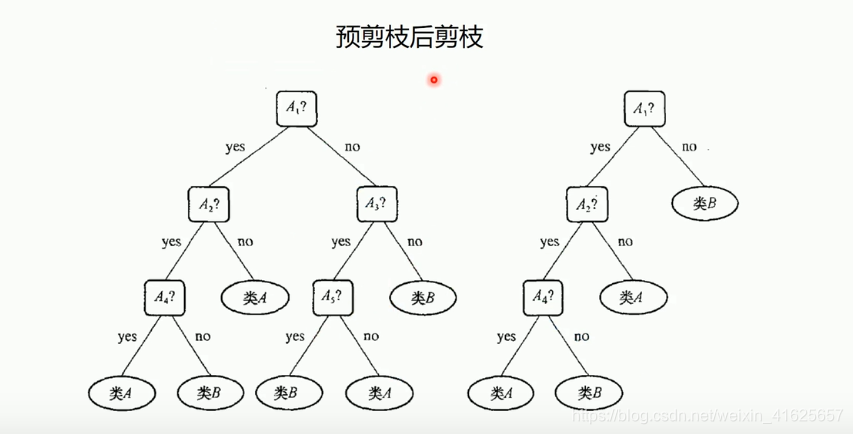
预剪枝:根据经验自己判断,把觉得没有用的属性先去掉,边构建,边剪枝(防止过拟合风险)
后剪枝:构建完决策树之后,我们再砍掉一部分。在判断条件几乎不影响分类时,比如100个样本,有90个样本都属于一类,而10个属于另一类。10个的类可能还会继续判断,那么就把这个10类别直接减掉,判断全部为90的类。
决策树优缺点:

实战
from sklearn import tree
import numpy as np
#载入数据
data = np.genfromtxt("cart.csv",delimiter=",")
x_data = data[1:,1:-1]
y_data = data[1:,-1]
#创建决策树模型,不传任何参数,就是默认使用基尼系数来计算
model = tree.DecisionTreeClassifier()
#输入数据建立模型
model.fit(x_data,y_data)
#导出决策树
import graphviz
dot_data = tree.export_graphviz(model,
out_file=None,
#特征的名字,要设置
feature_names = ['house_yes','house_no','single','married','divorced','income'],
class_names=['no','yes'],
filled=True,
rounded=True,
special_characters=True)
graph = graphviz.Source(dot_data)
graph.render('cart')
如果算出来基尼指数出现相同的值时,就会出现不同的结果,因为基尼指数相同时,它时随机选择其中一个作为一个节点。
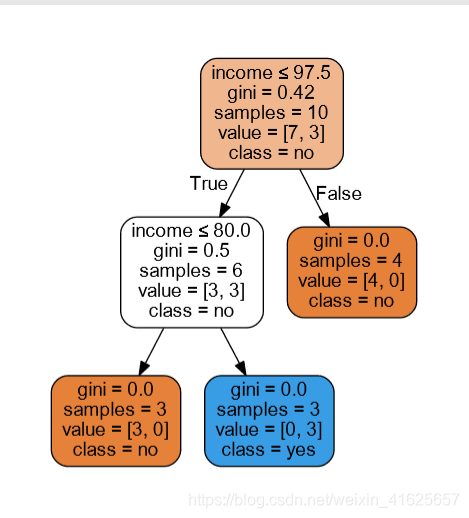
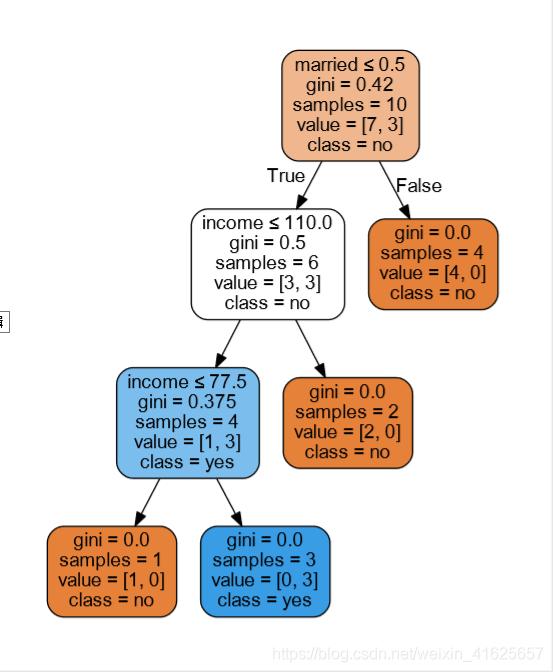















 1486
1486











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









