







最近参加了伯禹平台和Datawhale等举办的《动手学深度学习PyTorch版》课程,对word2vec,词嵌入进阶做下笔记。
词嵌入基础
one-hot 词向量无法准确表达不同词之间的相似度,如我们常常使用的余弦相似度,Word2Vec 词嵌入工具的提出正是为了解决上面这个问题,它将每个词表示成一个定长的向量,并通过在语料库上的预训练使得这些向量能较好地表达不同词之间的相似和类比关系,以引入一定的语义信息。基于两种概率模型的假设,我们可以定义两种 Word2Vec 模型:
Skip-Gram 跳字模型:假设背景词由中心词生成,即建模 P(wo∣wc),其中 wc 为中心词,wo 为任一背景词;
比如计算由loves (中心词)生成the,man,his,son四个词的概率
CBOW (continuous bag-of-words) 连续词袋模型:假设中心词由背景词生成,即建模 P(wc∣Wo),其中 Wo 为背景词的集合。
比如计算由the,man,his,son四个词生成loves (中心词)的概率
建立词语索引:index to token ,token to index
将数据集数字化
二次采样
文本数据中一般会出现一些高频词,如英文中的“the”“a”和“in”。通常来说,在一个背景窗口中,一个词(如“chip”)和较低频词(如“microprocessor”)同时出现比和较高频词(如“the”)同时出现对训练词嵌入模型更有益。因此,训练词嵌入模型时可以对词进行二次采样。 具体来说,数据集中每个被索引词 wi 将有一定概率被丢弃,该丢弃概率为
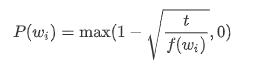
其中 f(wi) 是数据集中词 wi 的个数与总词数之比,常数 t 是一个超参数(实验中设为 10−4)。可见,只有当 f(wi)>t 时,我们才有可能在二次采样中丢弃词 wi,并且越高频的词被丢弃的概率越大。
提取中心词和背景词
对每个中心词其背景词的窗口大小时随机选取的,中心词需要被排出背景词外
Skip-Gram 跳字模型
在跳字模型中,每个词被表示成两个 d 维向量,用来计算条件概率。假设这个词在词典中索引为 i ,当它为中心词时向量表示为 vi∈Rd,而为背景词时向量表示为 ui∈Rd 。设中心词 wc 在词典中索引为 c,背景词 wo 在词典中索引为 o,我们假设给定中心词生成背景词的条件概率满足下式:
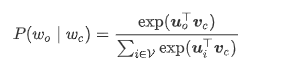 即内积+softmax
即内积+softmax
embed = nn.Embedding(num_embeddings=10, embedding_dim=4)
print(embed.weight)
x = torch.tensor([[1, 2, 3], [4, 5, 6]], dtype=torch.long)
print(embed(x))
Parameter containing:
tensor([[-0.7417, -1.9469, -0.5745, 1.4267],
[ 1.1483, 1.4781, 0.3064, -0.2893],
[ 0.6840, 2.4566, -0.1872, -2.2061],
[ 0.3386, 1.3820, -0.3142, 0.2427],
[ 0.4802, -0.6375, -0.4730, 1.2114],
[ 0.7130, -0.9774, 0.5321, 1.4228],
[-0.6726, -0.5829, -0.4888, -0.3290],
[ 0.3152, -0.6827, 0.9950, -0.3326],
[-1.4651, 1.2344, 1.9976, -1.5962],
[ 0.0872, 0.0130, -2.1396, -0.6361]], requires_grad=True)
tensor([[[ 1.1483, 1.4781, 0.3064, -0.2893],
[ 0.6840, 2.4566, -0.1872, -2.2061],
[ 0.3386, 1.3820, -0.3142, 0.2427]],
[[ 0.4802, -0.6375, -0.4730, 1.2114],
[ 0.7130, -0.9774, 0.5321, 1.4228],
[-0.6726, -0.5829, -0.4888, -0.3290]]], grad_fn=<EmbeddingBackward>)
PyTorch 预置的 Embedding 层
输入2*3的张量,输出2*3*4的张量,把每个数字变成embedding后的维度
Skip-Gram 模型的前向计算
def skip_gram(center, contexts_and_negatives, embed_v, embed_u):
'''
@params:
center: 中心词下标,形状为 (n, 1) 的整数张量
contexts_and_negatives: 背景词和噪音词下标,形状为 (n, m) 的整数张量
embed_v: 中心词的 embedding 层
embed_u: 背景词的 embedding 层
@return:
pred: 中心词与背景词(或噪音词)的内积,之后可用于计算概率 p(w_o|w_c)
'''
v = embed_v(center) # shape of (n, 1, d)
u = embed_u(contexts_and_negatives) # shape of (n, m, d)
pred = torch.bmm(v, u.permute(0, 2, 1)) # bmm((n, 1, d), (n, d, m)) => shape of (n, 1, m)
return pred由于 softmax 运算考虑了背景词可能是词典 V 中的任一词,对于含几十万或上百万词的较大词典,就可能导致计算的开销过大。我们将以 skip-gram 模型为例,介绍负采样 (negative sampling) 的实现来尝试解决这个问题。
负采样方法用以下公式来近似条件概率:
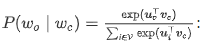
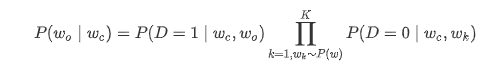
其中 P(D=1∣wc,wo)=σ(uo⊤vc),σ(⋅) 为 sigmoid 函数。对于一对中心词和背景词,我们从词典中随机采样 K 个噪声词(实验中设 K=5)。根据 Word2Vec 论文的建议,噪声词采样概率 P(w) 设为 w 词频与总词频之比的 0.75 次方。
训练模型
损失函数
应用负采样方法后,我们可利用最大似然估计的对数等价形式将损失函数定义为如下
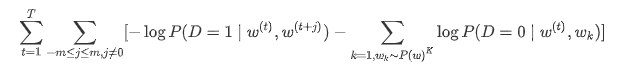
根据这个损失函数的定义,我们可以直接使用二元交叉熵损失函数进行计算:
class SigmoidBinaryCrossEntropyLoss(nn.Module):
def __init__(self):
super(SigmoidBinaryCrossEntropyLoss, self).__init__()
def forward(self, inputs, targets, mask=None):
'''
@params:
inputs: 经过sigmoid层后为预测D=1的概率
targets: 0/1向量,1代表背景词,0代表噪音词
@return:
res: 平均到每个label的loss
'''
inputs, targets, mask = inputs.float(), targets.float(), mask.float()
res = nn.functional.binary_cross_entropy_with_logits(inputs, targets, reduction="none", weight=mask)
res = res.sum(dim=1) / mask.float().sum(dim=1)
return res词嵌入进阶
虽然 Word2Vec 已经能够成功地将离散的单词转换为连续的词向量,并能一定程度上地保存词与词之间的近似关系,但 Word2Vec 模型仍不是完美的,它还可以被进一步地改进:
- 子词嵌入(subword embedding):FastText 以固定大小的 n-gram 形式将单词更细致地表示为了子词的集合,而 BPE (byte pair encoding) 算法则能根据语料库的统计信息,自动且动态地生成高频子词的集合;
- GloVe 全局向量的词嵌入: 通过等价转换 Word2Vec 模型的条件概率公式,我们可以得到一个全局的损失函数表达,并在此基础上进一步优化模型。
实际中,我们常常在大规模的语料上训练这些词嵌入模型,并将预训练得到的词向量应用到下游的自然语言处理任务中。
GloVe 全局向量的词嵌入
GloVe 模型
让我们先回顾一下word2vec中的跳字模型。将跳字模型中使用softmax运算表达的条件概率
记作
,即
其中
和
分别是索引为
的词
作为中心词和背景词时的向量表示,
为词典索引集。
对于词
,它在数据集中可能多次出现。我们将每一次以它作为中心词的所有背景词全部汇总并保留重复元素,记作多重集(multiset)
。一个元素在多重集中的个数称为该元素的重数(multiplicity)。举例来说,假设词
在数据集中出现2次:文本序列中以这2个
作为中心词的背景窗口分别包含背景词索引
和
。那么多重集
,其中元素1的重数为2,元素2的重数为4,元素3和5的重数均为1。将多重集
中元素
的重数记作
:它表示了整个数据集中所有以
为中心词的背景窗口中词
的个数。那么,跳字模型的损失函数还可以用另一种方式表达:
我们将数据集中所有以词
为中心词的背景词的数量之和
记为
,并将以
为中心词生成背景词
的条件概率
记作
。我们可以进一步改写跳字模型的损失函数为
上式中,
计算的是以
为中心词的背景词条件概率分布
和模型预测的条件概率分布
的交叉熵,且损失函数使用所有以词
为中心词的背景词的数量之和来加权。最小化上式中的损失函数会令预测的条件概率分布尽可能接近真实的条件概率分布。
然而,作为常用损失函数的一种,交叉熵损失函数有时并不是好的选择。一方面,正如我们在“近似训练”一节中所提到的,令模型预测 成为合法概率分布的代价是它在分母中基于整个词典的累加项。这很容易带来过大的计算开销。另一方面,词典中往往有大量生僻词,它们在数据集中出现的次数极少。而有关大量生僻词的条件概率分布在交叉熵损失函数中的最终预测往往并不准确。
鉴于此,作为在word2vec之后提出的词嵌入模型,GloVe模型采用了平方损失,并基于该损失对跳字模型做了3点改动:
- 使用非概率分布的变量
和
,并对它们取对数。因此,平方损失项是
。
- 为每个词
增加两个为标量的模型参数:中心词偏差项
和背景词偏差项
。
- 将每个损失项的权重替换成函数
。权重函数
是值域在
的单调递增函数。 如此一来,GloVe模型的目标是最小化损失函数
其中权重函数 的一个建议选择是:当
时(如
),令
(如
),反之令
。因为
,所以对于
的平方损失项可以直接忽略。当使用小批量随机梯度下降来训练时,每个时间步我们随机采样小批量非零
,然后计算梯度来迭代模型参数。这些非零
是预先基于整个数据集计算得到的,包含了数据集的全局统计信息。因此,GloVe模型的命名取“全局向量”(GlobalVectors)之意。
需要强调的是,如果词 出现在词
的背景窗口里,那么词
也会出现在词
的背景窗口里。也就是说,
。不同于word2vec中拟合的是非对称的条件概率
,GloVe模型拟合的是对称的
。因此,任意词的中心词向量和背景词向量在GloVe模型中是等价的。但由于初始化值的不同,同一个词最终学习到的两组词向量可能不同。当学习得到所有词向量以后,GloVe模型使用中心词向量与背景词向量之和作为该词的最终词向量。















 253
253











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









