







批量归一化(BatchNormalization)
对输入的标准化(浅层模型)
处理后的任意一个特征在数据集中所有样本上的均值为0、标准差为1。
标准化处理输入数据使各个特征的分布相近
批量归一化(深度模型)
利用小批量上的均值和标准差,不断调整神经网络中间输出,从而使整个神经网络在各层的中间输出的数值更稳定。
神经网络学习过程本质上就是为了学习数据分布,如果训练数据与测试数据的分布不同,网络的泛化能力就会严重降低。
输入层的数据,已经归一化,后面网络每一层的输入数据的分布一直在发生变化,前面层训练参数的更新将导致后面层输入数据分布的变化,必然会引起后面每一层输入数据分布的改变。而且,网络前面几层微小的改变,后面几层就会逐步把这种改变累积放大。训练过程中网络中间层数据分布的改变称之为:"Internal Covariate Shift"。BN的提出,就是要解决在训练过程中,中间层数据分布发生改变的情况。
批量归一化的分析
转载于https://baijiahao.baidu.com/s?id=1621528466443988599&wfr=spider&for=pc
1.在所有情况下,BN都能显著提高训练速度
2.如果没有BN,使用Sigmoid激活函数会有严重的梯度消失问题
3.中间层神经元激活输入x从变化不拘一格的正态分布通过BN操作拉回到了均值为0,方差为1的高斯分布。这有两个好处:1、避免分布数据偏移;2、远离导数饱和区,BN很好地解决了梯度消失问题
4.但这个处理对于在-1~1之间的梯度变化不大的激活函数,效果不仅不好,反而更差。比如sigmoid函数,s函数在-1~1之间几乎是线性,BN变换后就没有达到非线性变换的目的;而对于relu,效果会更差,因为会有一半的置零。总之换言之,减均值除方差操作后可能会削弱网络的性能。
5.对于小批量(即4),BN会降低性能,所以要避免太小的批量,才能保证批归一化的效果
6.如果对于具有分布极不平衡的二分类测试任务(例如,99:1),BN破坏性能并不奇怪。也就是说,这种情况下不要使用BN
7.BN算法后,参数进行了归一化,不用太依赖drop out、L2正则化解决归 一化,采用BN算法后可以选择更小的L2正则约束参数,因为BN本身具有提高网络泛化能力的特性。
1.对全连接层做批量归一化
位置:全连接层中的仿射变换和激活函数之间。
全连接批量归一化:
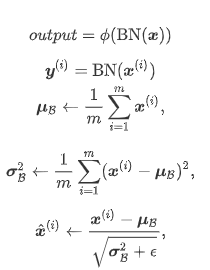
这⾥ϵ > 0是个很小的常数,保证分母大于0
引入可学习参数:拉伸参数γ和偏移参数β。
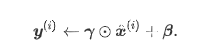
若![]() ,批量归一化无效。
,批量归一化无效。
2.对卷积层做批量归⼀化
位置:卷积计算之后、应⽤激活函数之前。
如果卷积计算输出多个通道,我们需要对这些通道的输出分别做批量归一化,且每个通道都拥有独立的拉伸和偏移参数。 计算:对单通道,batchsize=m,卷积计算输出=pxq 对该通道中m×p×q个元素同时做批量归一化,使用相同的均值和方差。
3.预测时的批量归⼀化
训练:以batch为单位,对每个batch计算均值和方差。
预测:用移动平均估算整个训练数据集的样本均值和方差。
残差网络(ResNet)
深度学习的问题:深度CNN网络达到一定深度后再一味地增加层数并不能带来进一步地分类性能提高,反而会招致网络收敛变得更慢,准确率也变得更差。
残差块(Residual Block)
恒等映射:
左边:f(x)=x
右边:f(x)-x=0 (易于捕捉恒等映射的细微波动)预测的是残差
在残差块中,输⼊可通过跨层的数据线路更快 地向前传播
稠密连接网络(DenseNet)
主要构建模块:
稠密块(dense block): 定义了输入和输出是如何连结的。
过渡层(transition layer):用来控制通道数,使之不过大。通常是1*1卷积层:来减小通道数,步幅为2的平均池化层:减半高和宽















 1400
1400











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









