







梯度下降法,堪称训练神经网络的黑魔法。掌握该魔法,要先搞懂 梯度的概念。
梯度是什么东东?
梯度是一个多维向量。对于多元函数 f ( x 1 , x 2 , . . . , x n ) f(x_1,x_2,...,x_n) f(x1,x2,...,xn)上的某一点 ( x 1 , x 2 , . . . , x n , y ) (x_1,x_2,...,x_n,y) (x1,x2,...,xn,y),其梯度被定义为: ⟨ ∂ f ∂ x 1 , ∂ f ∂ x 2 , . . . , ∂ f ∂ x n ⟩ \left \langle \frac{\partial f}{\partial x_1}, \frac{\partial f}{\partial x_2},...,\frac{\partial f}{\partial x_n} \right \rangle ⟨∂x1∂f,∂x2∂f,...,∂xn∂f⟩,也就是说,函数的梯度作为一个向量,其分量等于各个自变量对应的偏导数。
梯度的方向和大小,具有直观的几何意义。可以证明(本文不证):,某点的梯度方向,总是指向函数值“变化率”最大的方向,而梯度的大小等于该“变化率”。
一元函数的变化率,就是该函数的导数;而刻画多元函数的“变化率”,则需要引入方向导数的概念。
对于一元函数,自变量只有增大和减小两个变化方向,而对于多元函数,自变量可以有任意多个变化方向。不妨以二元函数 f ( x , y ) = x 2 + y 2 f(x,y)=x^2+y^2 f(x,y)=x2+y2 为例。如下图:
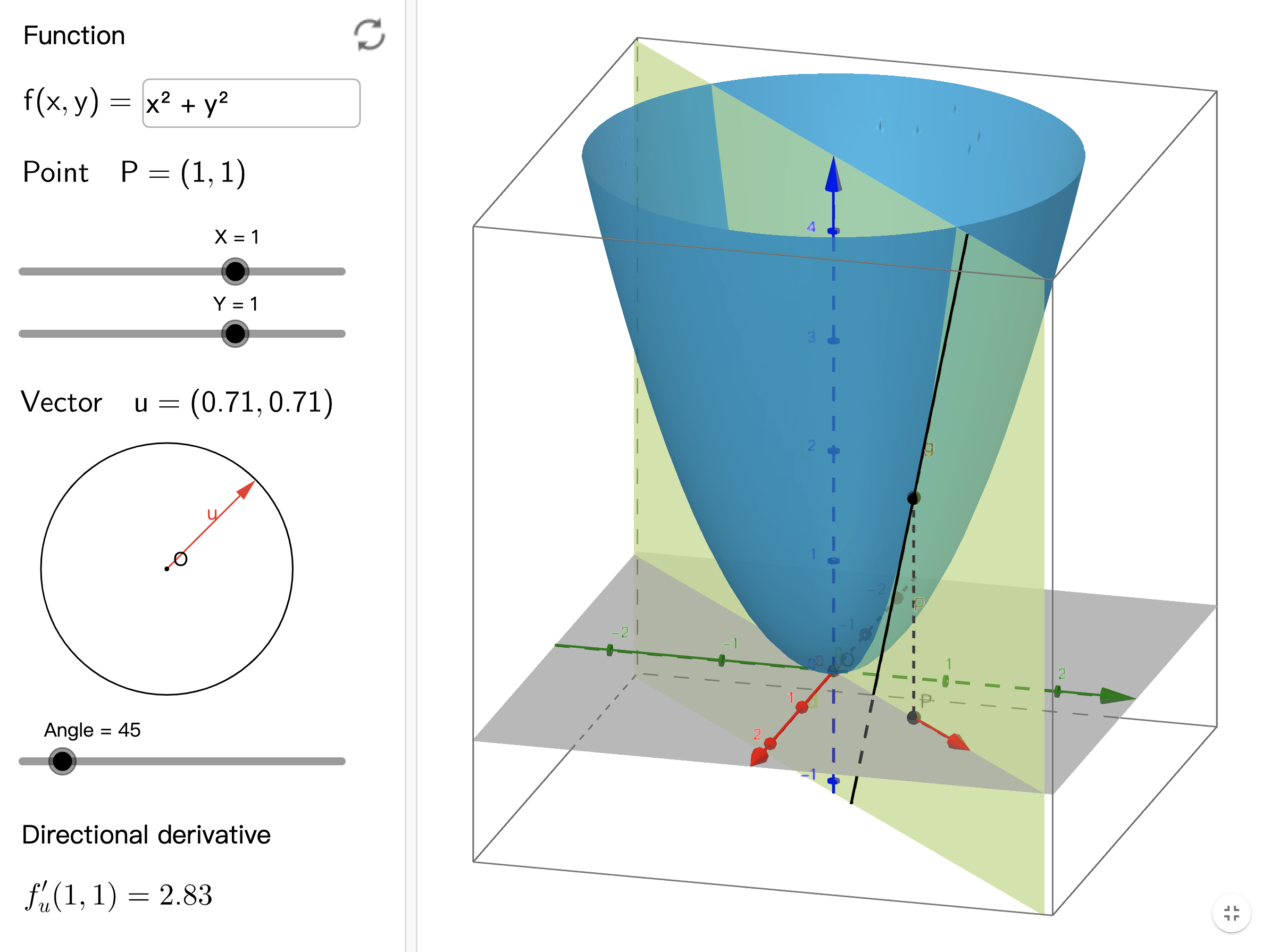
该图出自 geogebra 方向导数。访问该网址可以查看动态效果。
图中的点 P 0 ( 1 , 1 , 2 ) P_0(1,1,2) P0(1,1,2),在 x O y xOy xOy 平面上的投影为点 P ( 1 , 1 ) P(1,1) P(1,1)。红色的箭头所示的单位向量 u u u,表示 P 0 P_0 P0 点处函数 f f f 的一个自变量变化方向。设黑色的切线和 x O y xOy xOy 平面的夹角为 θ \theta θ,和一元函数类似, t a n ( θ ) tan(\theta) tan(θ) 等于函数 f f f 在 P 0 P_0 P0 处沿着方向 u u u 的方向导数,用符号表示为 f u ′ ( 1 , 1 ) f_u^{'}(1,1) fu′(1,1)。
拖动图中的手柄,可以调整红色箭头 u u u 的方向。显然, u u u 可以在 x O y xOy xOy 平面中 360 度旋转,对应地, P 0 P_0 P0 点处方向导数 f u ′ ( 1 , 1 ) f_u^{'}(1,1) fu′(1,1) 也会变化;当方向导数取到最大值时, u u u 的方向就是 P 0 P_0 P0 处变化率最大的方向,也就是 P 0 P_0 P0 处的梯度方向。
怎么个下降法
顾名思义,梯度下降法就是沿着梯度的反方向进行下降,直到找到函数的局部最小值或者全局最小值。
想象一下你在山上,站在某个点。如果你沿着不同的方向走,你会发现高度的变化率是不同的,也就是山的陡峭程度是不同的,而沿着梯度指向的方向,是最陡峭的。那么,每次沿着梯度的反方向迈出一小步,就能以最快的速度下山。
怎么判断你已经到了山谷呢?很简单,你只管沿着梯度的方向走,只要高度下再下降了,也就是梯度变成了 0 时,你就到了山谷。
显然,每一步迈出的距离大小,会影响下山的速度。这个步长,称之为学习率,记为 η \eta η。
梯度下降法用于训练神经网络时,目标是最小化损失函数。什么叫损失函数这里先不用管,只要知道它是一个多元函数即可。
一个神经网络可以有成千上万的参数,对应地,损失函数可以有成千上万的自变量。
运行梯度下降法时,首先需要随机地初始化这些自变量,然后沿着梯度反方向迭代若干轮。
一般地,对于损失函数 f ( x 1 , x 2 , . . . , x n ) f(x_1,x_2,...,x_n) f(x1,x2,...,xn),梯度下降法每次迭代,更新参数(自变量)的方式为:
x i ← x i − η ∂ f ∂ x i (式1) x_i \leftarrow x_i - \eta \frac{\partial f}{\partial x_i} \tag{式1} xi←xi−η∂xi∂f(式1)
这个式子,就是训练神经网络时的魔法所在。
你可能会好奇,一个拥有成千上万个自变量的函数,怎么对其求出每一个偏导数呢?这就要用到大名鼎鼎的误差逆传播算法了,这里也先跳过。
潜在的问题
陷入局部最小
梯度下降法可能会陷入局部最小值,而不是全局最小值。比如:如果初始位置位于局部最小值的附近,那么梯度下降法可能会很快找到该局部最小值然后停止,而不是全局最小值。
遭遇鞍点
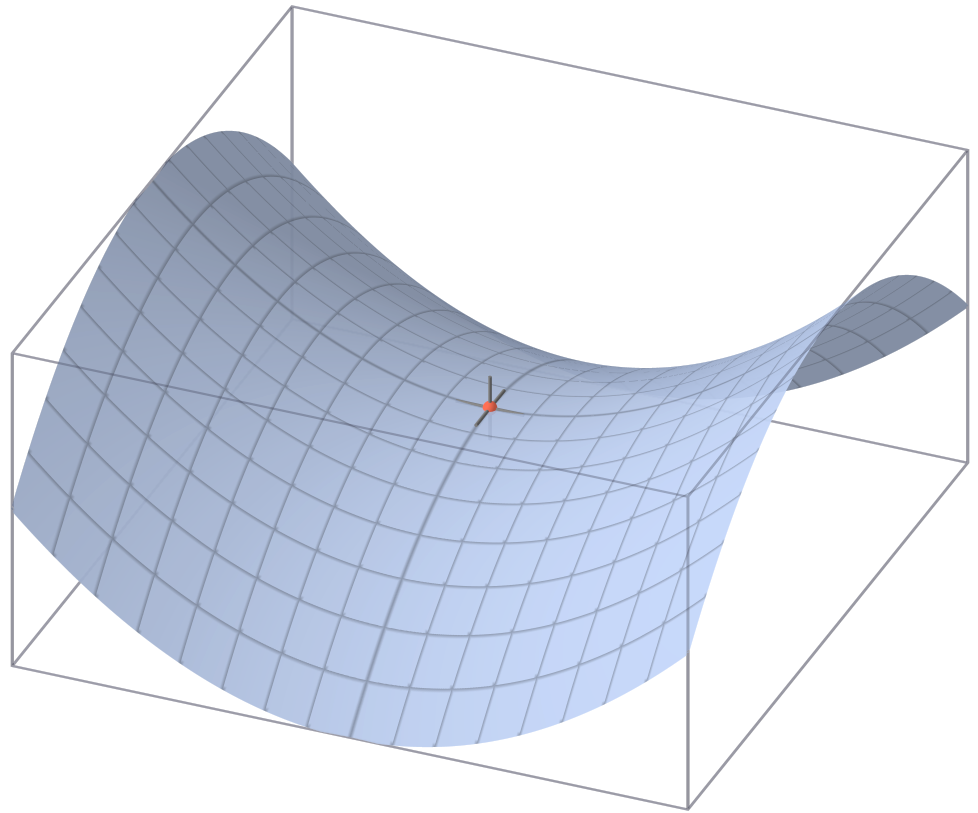
如上图所示,鞍点处的梯度为 0,但既不是极小值,也不是极大值。遭遇鞍点时,梯度下降法会终止。
学习率的选择
从式 1 可以看到,学习率 η \eta η 的选择至关重要。
如果学习率设置得太小,那么梯度下降法就会非常缓慢地收敛,浪费计算资源。
如果学习率设置得太大,那么梯度下降法可能会在最小值附近来回震荡,无法收敛。

















 4255
4255

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









