







 本文通过周志华《机器学习》中的西瓜数据集,实践了基于单层决策树的AdaBoost算法。详细介绍了AdaBoost的工作原理及其实现过程,包括数据加载、训练集与测试集划分、单层决策树生成及最佳决策树选择。
本文通过周志华《机器学习》中的西瓜数据集,实践了基于单层决策树的AdaBoost算法。详细介绍了AdaBoost的工作原理及其实现过程,包括数据加载、训练集与测试集划分、单层决策树生成及最佳决策树选择。
基于单层决策树的AdaBoost算法实践
最近一直在学习周志华老师的西瓜书,也就是《机器学习》,在第八章集成学习中学习了一个集成学习算法,即AdaBoost算法。AdaBoost是一种迭代算法,其核心思想是针对同一个训练集训练不同的分类器(弱分类器),然后把这些弱分类器集合起来,构成一个更强的最终分类器(强分类器)。
AdaBoost是adaptive boosting(自适应boosting)的缩写,其运行过程如下:训练数据中的每个样本,并赋予其一个权重,这些权重构成了权重向量D。一开始,这些权重都初始化成相等值。首先在训练数据上训练出一个弱分类器并计算该分类器的错误率,然后在同一数据集上再次训练弱分类器。在分类器的第二次训练当中,将会重新调整每个样本的权重,其中第一次分对的样本的权重将会降低,而第一次分错的样本的权重将会提高。为了从所有弱分类器中得到最终的分类结果,AdaBoost为每个分类器都分配了一个权重值alpha,这些alpha值是基于每个弱分类器的错误率进行计算的。计算出alpha值之后,可以对权重向量D进行更新,以使得那些正确分类的样本的权重降低而错分样本的权重升高。在计算出权重向量之后,AdaBoost又开始进入下一轮迭代。AdaBoost算法会不断的重复训练和调整权重的过程,直到训练错误率为0或者弱分类器的数目达到用户的指定值为止。算法过程如下所示:




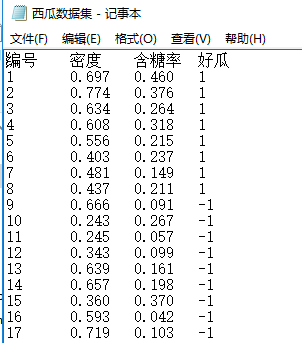
为了加深自己的理解和提高自己的动手能力,于是便想以西瓜书p89页上的西瓜数据集为例,在该数据集上应用基于单层决策树的AdaBoost算法。心动不如行动,于是参考另外一本书《机器学习实战》,开始了从理论到实践的尝试。本文的代码全部都是采用python 3.6版本进行编写的。在开始之前,我将数据集存放在一个名为“西瓜数据集.txt”的文件中,其中1表示好瓜,-1表示坏瓜,如下图所示:
接下来我们需要向该txt文件中加载数据,在编写程序之前,我们在“西瓜数据集.txt”文件所在的文件夹下创建了一个叫“adboost.py”的新文件(所有的代码均写在该文件内),并在adboost.py文件中编写加载数据的代码,如下所示:
import numpy
def loadDataSet(file_Name):
'''
这个函数用来加载训练数据集
输入:存储数据的文件名
输出:数据集列表 以及 类别标签列表
'''
with open (file_Name,encoding='utf8')as fr:
dataMat=[];labelMat=[]
line_list=fr.readlines()[1:]
Feature_number=len(line_list[0].strip().split())
for line in line_list:
lineArr=[]
line_new=line.strip().split()
for i in range(Feature_number):
lineArr.append(float(line_new[i]))
dataMat.append(lineArr[1:-1])
labelMat.append(lineArr[-1])
return numpy.array(dataMat),numpy.array(labelMat)由于我将西瓜数据集.txt文件设置成了utf-8的格式,因此open()函数中设置了encoding='utf8',如果你将西瓜数据集.txt文件设置成ANSI的格式(windows中ANSI就是GBK格式),那么encoding='utf8'则不需要。
为了便于观察数据加载结果,我们通过numpy中的array()函数将列表转换成数组的形式,通过将其打印出来,我们看到如下图所示:


至此我们已经有了样本数据集,接下来我们把样本数据集分成两个部分,为了方便起见,这里就不采用随机的方式来划分,通过人为的指定,我把第2,10,13个样本数据提取出来作为测试集,所需要的代码如下所示:
def dataSplit(dataArr,labelArr):
'''
此函数的作用是将有限的样本数据集划分成训练集和测试集两部分
输入:dataArr 所有的样本数据集,以numpy.ndarray形式封装
labelArr 所有样本数据集对应的类别标签
输出:trainDateArr 训练集
trainlabelArr 训练集对应的类别标签
testDateArr 测试集
testlabelArr 测试集对应的类别标签
'''
trainDateArr = numpy.delete(dataArr.copy(),[1,9,12],0)
trainlabelArr = numpy.delete(labelArr.copy(),[1,9,12])
testDateArr = dataArr.copy()[[1,9,12],:]
testlabelArr =labelArr.copy()[[1,9,12]]
return trainDateArr,trainlabelArr,testDateArr,testlabelArr由于本文采用基于单层决策树的AdaBoost算法,当然AdaBoost算法可以使用任意分类器作为弱分类器(比如逻辑回归、k-NN以及贝叶斯分类器等等),因此首先编写单层决策树的生成函数,此函数如下所示:
def treeClassify(dataMat, column, threshold, inequation):
'''
这是一个通过阈值threshold来对样本数据进行分类的,所有在阈值一边的数据会分到类别-1,而在另外一边的数据分到类别+1
输入: datamat是样本数据集,接收列表形式的输入
column用于指定待切分的特征
threshold用来作为column所指定的特征列当中的值的比较阈值
inequation用来指定是大于还是小于阈值
输出:决策之后的类别标签(numpy.ndarray形式)
'''
if dataMat.ndim> 1:
label_result = numpy.ones((dataMat.shape[0], 1))
else:
label_result = numpy.ones((1, 1))
if inequation == 'less_than':
if dataMat.ndim > 1: #表示dataMat是一个二维数组
label_result[numpy.nonzero(dataMat[:, column] <= threshold)[0]] = -1.0
else: #否则dataMat就是一个一维向量
if dataMat[column] <= threshold:
label_result = -1.0
else:
if dataMat.ndim > 1: #表示dataMat是一个二维数组
label_result[numpy.nonzero(dataMat[:, column] > threshold)[0]] = -1.0
else: #否则dataMat就是一个一维向量
if dataMat[column] > threshold:
label_result = -1.0
return label_result如何才能找到最佳的决策树呢?也就是说在某一轮迭代当中,决策树有很多种划分可能,我们去哪种划分呢?当然是越准确越好,我们根据错误率来寻找最佳的单层决策树,而最小错误率所对应的单层决策树就是我们要找的最佳决策树啦。此处采用加权错误率,而权重值就用每一轮迭代中的权重向量。程序如下所示:
def buildSingleTree(dataArr, labelArr, weightArr):
'''
这个函数根据加权错误率来找到最佳的单层决策树
输入:dataArr是numpy.ndarray形式的样本数据集
labelArr是numpy.ndarray形式的类别标签
weightArr是当前轮次迭代所对应的权重向量
输出:bestSigleTree 存储给定权重向量weightArr时所得到的最佳单层决策树的相关信息
minError 最佳单层决策树所对应的错误率,即最小错误率
bestLabelResult 当前最佳单层决策树的类别估计值
'''
dataMatrix = numpy.mat(dataArr)
labelMatrix = numpy.mat(labelArr).T
m, n = dataMatrix.shape
bestSigleTree = {}
bestLabelResult = numpy.mat(numpy.zeros((m, 1)))
minError = numpy.inf
for i in range(n):
feature_value_list = sorted(dataMatrix.A[:, i])
for j in feature_value_list:
for inequation in ['less_than', 'greater_than']:
threshold = float(j)
predicted_label = treeClassify(dataMatrix, i, threshold, inequation)
current_error = numpy.mat(numpy.ones((m, 1)))
current_error[predicted_label == labelMatrix] = 0
weighted_Error = weightArr.T * current_error
if weighted_Error < minError:
minError = weighted_Error
bestLabelResult = predicted_label[:, :]
bestSigleTree['column'] = i
bestSigleTree['threshold'] = threshold
bestSigleTree['inequation'] = inequation
return bestSigleTree, minError, bestLabelResult
为了获得用于AdaBoost算法的多个弱分类器以及相应的alpha值,我们编写如下程序:
def refreshWeightArr(expon, original_weightArr):
'''
这是一个训练数据集的权值分布WeightArr的更新函数
输入:expon是由基分类器的权重(由分类错误率计算得到的)、类别标签以及单层决策树划分后得到的类别估计值计算得到的
original_weightArr是更新之前的WeightArr
输出:updated_weightArr是更新之后的训练数据集的权值分布
'''
intermediate_variable = original_weightArr * numpy.exp(expon)
updated_weightArr = intermediate_variable / intermediate_variable.sum()
return updated_weightArr
def adaBoostTrain(dataArr, labelArr, iterationsNumber=40):
'''
这是基于单层决策树的adaBoost算法
输入:dataArr是numpy.ndarray形式的样本数据集
labelArr是numpy.ndarray形式的类别标签
iterationsNumber是迭代次数
输出:多个弱分类器组成的numpy.ndarray形式的分类器集合
'''
classifier_Arr = []
m = dataArr.shape[0]
weightArr = numpy.ones((m, 1)) / m
accumulative_estimated_value = numpy.zeros((m, 1))
for i in range(iterationsNumber):
current_SigleTree, current_Error, current_label_Result =\
buildSingleTree(dataArr, labelArr, weightArr)
alpha = float(0.5 * numpy.log((1.0 - current_Error) / max(current_Error, 1e-16)))
current_SigleTree['alpha'] = alpha
classifier_Arr.append(current_SigleTree)
expon = -1 * alpha * numpy.array(labelArr).reshape(m, 1) * current_label_Result
weightArr = refreshWeightArr(expon, weightArr)
accumulative_estimated_value += alpha * current_label_Result
if len(numpy.nonzero(numpy.sign(accumulative_estimated_value) !=\
labelArr.reshape(m, 1))[0]) == 0:
break
return classifier_Arr
我们现在已经有了AdaBoost算法的多个弱分类器以及相应的alpha值,现在编写一个针对测试样本的分类函数,程序编写如下:
def testDateClassify(newDateSet, classifierArr):
'''
此函数用于对新数据进行自动分类,得到分类结果
输入:newDateSet是待分类的新数据
classifierArr是根据训练数据集用adaBoost算法训练出来的弱分类器集合
输出:类别预测值
'''
newdataArr = numpy.array(newDateSet)
if newdataArr.ndim > 1:
m = newdataArr.shape[0]
else:
m = 1
accumulative_estimated_value = numpy.zeros((m,1))
for i in range(len(classifierArr)):
current_label_Result = treeClassify(newdataArr, classifierArr[i]['column'], \
classifierArr[i]['threshold'], classifierArr[i]['inequation'])
accumulative_estimated_value +=classifierArr[i]['alpha'] * current_label_Result
return numpy.sign(accumulative_estimated_value)接下来我在adboost.py文件继续添加代码,来检测adaBoost算法对测试集数据的分类效果,如下所示:
if __name__=="__main__":
dataArr,labelArr = loadDataSet('西瓜数据集.txt')
trainDateArr, trainlabelArr, testDateArr, testlabelArr = dataSplit(dataArr, labelArr)
classifierArr = adaBoostTrain(trainDateArr, trainlabelArr)
test_result = testDateClassify(testDateArr, classifierArr)
print('预测结果')
print(test_result) #adaBoost算法对测试集类别的预测结果
print('真实结果')
print(testlabelArr.reshape(3,1)) #测试集的真实类别标签其结果如下:

至此,对西瓜数据集进行的AdaBoost算法的应用就完成了。
参考资料:
[1] 周志华 《机器学习》
[2] Peter Harrington著 李锐译 《机器学习实战》
[3] 李航 《统计学习方法》

















 1099
1099

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









